Zalety i wady architektury serverless w pigułce

Serverless polega na korzystaniu z zasobów komputerowych, które działają jako serwisy, bez potrzeby zarządzania fundamentalną infrastrukturą. Co więcej, nie oznacza to, że serwery nie odgrywają już żadnej roli. Sam termin odzwierciedla punkt widzenia programisty.
Główne cechy
Mike Roberts zaproponował następujące kryteria, według których definiujemy serverless:
- Hostami serwera i procesami nie zarządza klient, czy developer (wysokopoziomowa abstrakcja)
- Elastyczność oznacza autoskalowanie i automatyczne przydzielanie zasobów na podstawie obciążenia
- Płatność za to, czego się używa w zależności od oferty danego dostawcy
- Rozmiar i liczba serwerów nie definiują wydajności
- Domyślnie, wysoka dostępność i tolerancja na błędy
Serverless = FaaS + BaaS
Jak już osiągniemy powyższe, to możemy założyć, że serverless to nie tylko function as a service, ale również backend as a service (np. przechowywanie w chmurze, uwierzytelnianie, bazy danych).
Co więcej, chciałbym Wam pokazać porównanie między różnymi modelami typu “as a service”, a tradycyjnym IT, gdzie cały stos znajduje się tam, gdzie się pracuje. Im dłuższa strzałka na poniższysz obrazie, tym więcej potrzeba zarządzania.
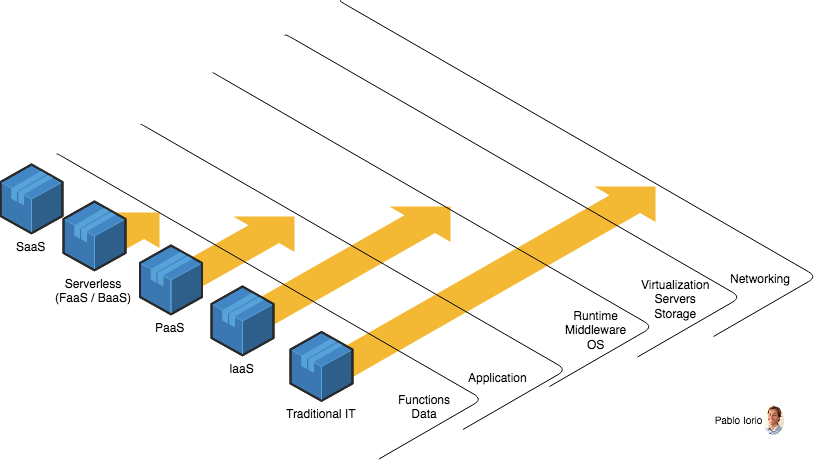 Jak bardzo trzeba tak naprawdę zarządzać. Porównanie między różnymi modelami typu “as a service”.
Jak bardzo trzeba tak naprawdę zarządzać. Porównanie między różnymi modelami typu “as a service”.
Zalety architektury serverless
Płacisz tyle, ile używasz
Cena wynika z liczby żądań do Twoich funkcji. Zazwyczaj możliwe jest też skorzystanie z okresu próbnego, który jest za darmo. Jest to bardzo korzystne, jeśli chodzi o analizę kosztów. Zdaje mi się jednak, że dostawcy tworzą darmowe plany, by pozyskać nowych klientów. Podczas analizy kosztów/przychodów trzeba wziąć pod uwagę koszty migracji funkcji, usługi towarzyszące serverless (np. API Gateway, CDN, load balancery itd.) oraz dane.
Wbudowana elastyczność
Wszystko skaluje się automatycznie w zależności od dodawania i odejmowania zasobów.
Produktywność
Z jednej strony taki typ architektury zapewnia na początku szybki developement, kiedy liczba funkcji jest ograniczona. A to dlatego, że nie trzeba wtedy martwić się o początkową konfigurację infrastruktury. Z drugiej jednak strony, duża liczba funkcji może znacznie utrudnić tę kwestię, zwłaszcza jeśli spojrzymy z testerskiego punktu widzenia oraz pod kątem debugowania. Opcją, która pozwoli nam mieć większą kontrolę nad rzeczami i może zwiększyć naszą wydajność, jest użycie emulatorów developmentu. Różnią się one jednak trochę od środowiska produkcyjnego, pomimo kilku podobieństw - jakaś funkcja może więc działać w emulatorze, ale nie na produkcji.
Testy jednostkowe każdej funkcji z osobna są prostsze
A to ze względu na zasadę pojedynczej odpowiedzialności, która pozwala zredukować przestrzeń testową do minimum. Testy integracyjne mogą być jednak bardziej wymagające.
Abstrakcje
Pomimo że wysokopoziomowe abstrakcje pomagają nam skupić się na złożoności w domenie biznesowej, to jednak łatwo jest utracić tutaj kontrolę. To jest niestety ten klasyczny trade-off w inżynierii oprogramowania.
Model oparty na zdarzeniach
Taka architektura istnieje już trochę czasu. Serverless idealnie do niej pasuje. Funkcje można łączyć przy pomocy "hooków". Na przykład, funkcja może być rozwinięta w taki sposób, aby przetwarzać niepowodzenie uwierzytelnianie z OAuth. Zasada otwarte-zamknięte zapewnia dobrze zdefiniowane interfejsy, które są w stanie rozszerzać rozwiązania bez zwiększania powierzchni testowej.
Mikroserwisy
Korzystanie z funkcji umożliwia rozwijanie architektury opartej na mikroserwisach. Łatwiej jest wtedy rozwijać oddzielne komponenty, tak aby nie trzeba było dokonywać ich jednoczesnego deploymentu. Z drugiej jednak strony zwiększając liczbę elementów, zwiększamy złożoność, latencję oraz koszt utrzymania i monitorowania. Tutaj możesz dowiedzieć się więcej o operacyjnej złożoności mikroserwisów.
Niemutowalność
Funkcji się nie modyfikuje, każda zmiana to nowa wersja. W przypadku stworzenia nowej wersji zaleca się monitorowanie użycia poprzedniej wersji i wyrzucenie jej, w momencie, kiedy już nikt jej nie używa.
Izolacja i bezpieczeństwo
Każda z funkcji może mieć jedynie dostęp do swojego własnego kontenera. Jeśli uruchomienie funkcji się nie powiedzieć, to nie będzie ona mogła mieć dostępu do innych kontenerów.
Łatwiejsze tworzenie się nowych środowisk
Dzieje się tak, kiedy kilka przepływów pracy działa równolegle, ponieważ tworzenie się wszystkich komponentów można zautomatyzować.
Wsparcie dla teamów wielojęzycznych
Chodzi tutaj o wiele języków programowania. Funkcje mogą być wtedy wykonywane w JS, Pythonie, Go, w jakimkolwiek języku z JVM (Java, Clojure, Scala itd.) lub jakimkolwiek języku .NET. Pomaga to w lepszym dopasowaniu się do umiejętności zespołu i do implementowanych wymagań.
Bezstanowe z natury
Bezstanowość oznacza, że każde żądanie jest wykonywane w izolacji i nie przekazuje się między nimi stanu. Jest to bardzo korzystne, ponieważ daje nam elastyczność bez potrzeby zamartwiania się o stan. Co więcej, zmniejsza złożoność. Na rynku oferowane są też wersje, które przechowują stan - np. trwałe funkcje Azure, lub AWS step functions, które zawierają w sobie funkcje orkiestracyjne i umożliwiają definicję bardziej złożonych przepływów pracy.
Domyślnie duża dostępność i tolerancja na błędy
SLA w AWS Lambda w każdym miesiącu i w każdym regionie to 99.95%.
Wady i wyzwania
Podejścia hybrydowe
Podejście hybrydowe, w których korzystamy z chmury i serwerów on-premise, musi być ostrożnie przemyślane, ponieważ wszystkie elementy serverless będą domyślnie elastyczne, a elementy on-premise już takie nie są. W takim przypadku być może będzie trzeba użyć throttlingu, by nie przeciążyć infrastruktury, która się nie skaluje.
Złożoność systemowa
Z jednej strony niektóre części systemu stały się prostsze. Z drugiej jednak, zwiększyła się złożoność, a to dlatego, że mamy więcej orkiestracji między funkcjami i serwisami, schematu wiadomości, więcej API, błędów sieci i tak dalej. Wymagane są dobre monitorowanie, rozpoznanie operacyjne i automatyzacja deploymentu, aby móc debugować cały system.
Zamknięcie na określonego dostawcę
Redukcja w przenaszalności. Mamy tutaj też ograniczony wybór, jeśli już zdecydowaliśmy się na danego vendora. Istnieją frameworki FaaS, które tworzą abstrakcję nad rozwiązaniami konkretnych dostawców, co zwiększa przenaszalność. Koszty migracji nadal mogą być duże. W większości przypadków nie wynikają one z różnic w kodzie samych funkcji, a w działaniu usług, które są użyte, by z funkcji stworzyć pełne rozwiązanie.
Ograniczenia zasobów
Funkcje mają swoje ograniczenia ze względu na alokację pamięci, zarządzanie limitem czasu żądania, rozmiar żądania, rozmiar samej funkcji i wykonanie współbieżne. Granice te są spójne z filozofią serverless. Dobrze sprawdzi się tutaj mała funkcja, z pojedynczą odpowiedzialnością, która jest uruchomiona przez krótki czas, nie zużywa dużo zasobów i jest małego rozmiaru. Jeżeli chcesz mieć proces działający dłużej i pożerający dużo pamięci, to inna architektura pewnie będzie lepsza.
Testy integracyjne są ciężkie
Kiedy już dotrzesz to pewnego poziomu funkcji i będzie trzeba wykonać orkiestrację, to testy integracyjne stają się niezwykle wymagające. Staje się tak, kiedy nie masz kontroli nad wszystkimi serwisami, które istnieją wokół danego rozwiązania. Musisz wtedy tworzyć stuby tych serwisów. Jeśli vendor nie zapewnia takiej możliwości, to trzeba je samemu stworzyć.
Debugowanie też jest ciężkie
Replikacja chmury na lokalnej maszynie jest trudna. Nie chodzi tutaj o samą próbę, ponieważ dostawcy chmury powinni zapewniać opcje do debugowania w chmurze, uruchamiając repliki podobne do tych, które możemy spotkać na produkcji. Zobaczmy, w którą stronę pójdzie debugowanie w ciągu kilku następnych lat.
Obserwowalność
Obserwowalność zawiera w sobie monitorowanie, alerty, gromadzenie logów i śledzenie wykonania w systemie rozproszonym. Monitoring i altery każdego serwisu są częścią usług dostawcy. Gromadzenie logów oraz śledzenie wykonania w systemie rozproszonym mogą oznaczać więcej pracy, zwłaszcza jeśli używa się zewnętrznych serwisów i gdzie to wszystko jest zebrane w jedną całość. Dzieje się tak, ponieważ nie można tutaj używać standardowych wzorców. Przetwarzanie w tle nie jest możliwe do zrealizowania. To samo tyczy się agentów i demonów, które działają w funkcjach. Dużo się w tym obszarze jednak dzieje, spodziewam się, że niektóre rzeczy mogą się poprawić.
Cold start, lub wysoka latencja
Kiedy jakieś zdarzenie uruchamia daną funkcję, jeśli się jej przez jakiś czas nie używało, to trzeba wtedy zainicjować instancję kontenera. Powoduje to opóźnienie między żądaniem a wykonaniem funkcji - czyli cold start. Będzie on zależał od kilku czynników - np. języka programowania, liczby linijek do wykonania, biblioteki do załadowania i innych rzeczy związanych z konfiguracją środowiska.
Za bardzo ambitne API Gateway
Jeden z problemów wskazanych przez ThoughtWorks Radar to sytuacja, w której warstwa gateway gromadzi zbyt dużo logiki biznesowej. Wie ona również o orkiestracji, która jest wymagana między różnymi funkcjami/serwisami. W konsekwencji trudniej się testuje i zmniejsza się przenaszalność.
Podsumowanie
Mamy szczęście, że żyjemy w czasach pełnych nowych technologii i architektur, nawet jeśli alternatyw byłoby tyle, że będzie ciężko wybrać. Serverless pozwala na osiągnięcie bardzo dużej elastyczności, jeżeli chodzi o zasoby. Z drugiej strony w pewnych warunkach oznacza utratę kontroli.
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.