

Meriam KharbatSenior Software EngineerFled Intelligence Inc.
Wyrażenia regularne w JavaScript
Dowiedz się wszystkiego o działaniu wyrażeń regularnych w języku JavaScript.
Wyrażenia regularne są dla rozwoju oprogramowania czymś niezbędnym - tak czy siak, prędzej czy później się z nimi spotkasz. Pokażę Ci tutaj wszystko, co musisz wiedzieć, aby ich używać w JS. Oto nasz spis treści:
- Do czego wyrażenia regularne służą?
- Jak one wyglądają?
- Jak zdefiniować takie wyrażenie w JavaScript?
- W jaki sposób wyrażenia regularne działają?
- Jaka jest składnia wyrażeń regularnych w JS?
- Jak używać przechwytywania i odwołań wstecznych?
- Jak wyrażenia regularne zostają dopasowane?
- Jak optymalizować wyrażenia regularne?
- Kiedy nie używać wyrażeń regularnych?
Do czego wyrażenia regularne służą?
Można o nich myśleć, jak o szybkich i sprawnych narzędziach, które pozwalają na znajdowanie i zamianę wzorca w tekście. Do czego więc służą?
- Możesz sprawdzić, czy dany tekst zawiera jakiś substring lub wzorzec
- Możesz znajdować i zwracać dopasowania do wzorca
- Możesz przechwytywać te ciągi znaków z tekstu
- Możesz je też modyfikować
Tutaj możecie znaleźć kilka przypadków użycia wyrażeń regularnych na front endzie. Większość wysokopoziomowych języków programowania korzysta z wyrażeń regularnych. Silnik wyrażeń regularnych JavaScriptu opiera się na gramatyce wyrażeń regularnych z Perl5.
Jak wyglądają wyrażenia regularne?
Oto przykład takiego wyrażenia: /Medi[a-zA-Z]*/. Postaramy się teraz zrozumieć jego działanie. Opisuje ono wzorzec słów, które zaczynają się substringiem Medi. Będą tutaj pasować następujące słowa: Medium, Media, Medical oraz Medi. Spróbuj samemu.
Uwaga: wyrażenia regularne są case sensitive - są wrażliwe na wielkość znaku. A zatem medium nie będzie tutaj pasowało.
Jak zdefiniować wyrażenie regularne w JS?
Wyrażenie regularne to obiekt, który opisuje wzorzec znaków. W JS natomiast można je zdefiniować na dwa sposoby:
- Używając wyrażenia regularnego wewnątrz dwóch ukośników -
/.../
const myPattern = /Medi[a-zA-Z]*/;
- Lub, tworząc instancję obiektu RegExp:
const myPattern = new RegExp ("Medi[a-zA-Z]*");
Oba formaty sprawiają, że tworzy się to samo wyrażenie regularne w zmiennej myPattern.
Opcje
Oprócz samego wyrażenia, do regex możemy włączyć 5 opcji:
i: sprawia, że regex jest case insensitive. Na przykład,/Medi[a-zA-Z]*/ipasowałoby do wszystkich przypadkówg: dopasowuje wszystkie wystąpienia wzorca. Bez flagig, regex dopasowałby tylko pierwsze wystąpieniem: sprawia, że dopasowanie początku i końca dotyczy każdej linijki z osobnay: Pozwala na sticky matching; wyrażenie próbuje tej metody w ciągu znaków przez dopasowanie się z poprzedniej pozycjiu: pozwala na użycie kodu Unicode znaku\u...
Korzystając z obiektów RexExp, opcje te można przekazać jako parametr. Na przykład:
const myPattern = new RegExp ("Medi[a-zA-Z]*", "ig");
Jest to ekwiwalent następującego kodu:
const myPattern = /Medi[a-zA-Z]*/ig;
Jak wyrażenia regularne działają?
Oto krótka odpowiedź. Pomyśl o wyrażeniach regularnych jak o miniprogramie, który opisuje wzorzec i mówi maszynie, czego ma szukać. Mając to na uwadze, nie powinno Cię dziwić, że:
- Wyrażenia regularne definiują zestaw instrukcji. Na przykład: „najpierw znajdź wielką literę M, a potem małą…”
- Wyrażenia regularne mają swoje dane wejściowe (czyli tekst, który chcesz odnaleźć lub zamienić). Mogą one też zwrócić podzbiór, który miał zostać dopasowany;
- Wyrażenia regularne mają swoją składnię, można je kompilować, wykonywać, czy nawet optymalizować, aby były szybsze.
Poniżej opisałam to bardziej szczegółowo.
Jaka jest składnia wyrażeń regularnych w JS?
Dokładne dopasowanie
Alfanumeryczne znaki, które nie są meta metaznakami lub operatorami, zostaną dopasowane do samych siebie. W przykładzie /Medi[a-zA-Z]*/ M to znak, który pasuje sam do siebie, podobnie do e,d oraz i. Ustawienie jednego znaku po drugim będzie oznaczało, że szukamy M występującego przed e, które występuje przed d, występującym przed i. A zatem Medo nie będzie tutaj pasowało.
Alternatywa
Jeśli naszym celem jest wyrażenie tego, że chcemy dopasować a lub b, to możemy tutaj użyć operatora |. Wyrażenie regularne będzie zatem wyglądało następująco: /a|b/.
Dopasowywanie klasy znaków
Zdarzają się przypadki, w których nie chcemy mieć dokładnego dopasowania, ale szukamy znaków ze skończonego zbioru. Umożliwi nam to operator zbioru. Zbiór [abc] dopasuje się do jakiegokolwiek znaku - a, b lub c. Jeśli mielibyśmy dodać ^ zaraz po nawiasie, to zbiór [^abc] będzie pasował do każdego znaku, oprócz a, b i c.
W przykładzie /Medi[a-zA-Z]*/, [a-zA-Z] to klasa, która pasuje do każdego znaku od a do z (duża lub mała litera).
Moglibyśmy napisać [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ], ale umieszczając tam myślnik jako operator - i wtedy jakikolwiek znak od a do z (albo A do Z) włącznie będzie pasował.
Znak ucieczki
Nie wszystkie znaki w składni wyrażeń regularnych mogą reprezentować same siebie. W przykładzie /Medi[a-zA-Z]*/, * występuje jako kwantyfikator, który oznacza, że chcemy dopasować treść zero lub więcej razy - tak wiele razy, jak to możliwe - znak ze zbioru [a-zA-Z].
Jak możemy określić, że chcemy znaleźć znak *?
W regexie, gdy chcemy dopasować konkretny znak, który jest zarezerwowany jako operator, to musimy użyć znaku ucieczki - ukośnika wstecznego \. Jeśli dopasowujemy *, to musimy określić \* w składni regex. Jeśli chcemy dopasować literał ukośnika wstecznego, to trzeba określić \\.
Początek i koniec
Zdarzają się przypadki, w których chcemy dopasować wzorzec do początku ciągu znaków. W przykładzie /Medi[a-zA-Z]*/, zdMedium również będzie pasowało. Jeśli chcemy, aby do regexa pasowały tylko ciągi znaków zaczynające się od Medi, to musimy tylko dodać ^ na początku wyrażenia regularnego: /^Medi[a-zA-Z]*/.
Symbol dolara ($) będzie też oznaczał, że wzorzec musi pojawić się na końcu ciągu znaków.
Kwantyfikatory
Jeśli chcemy dopasować serię dwóch znaków m, to możemy napisać /mm/. Regex pozwala na określenie tego, ile razy musi wystąpić konkretny wzorzec, aby został uznany za dopasowanie. Na przykład, /m{2}/ określa dopasowanie dwóch następujących po sobie znaków.
W przykładzie /Medi[a-zA-Z]*/, * określa to, że dopasujemy się do jakiegokolwiek znaku z [a-zA-Z], tyle razy, ile jest to możliwe.
Zdefiniowane wcześniej klasy
Niektóre klasy zostały już wcześniej zdefiniowane. Załóżmy, że chcemy dopasować cyfry. Zdefiniowana wcześniej klasa \d dopasuje się do każdej cyfry dziesiętnej. Będzie to ekwiwalent [0-9]. Innymi przykładami mogą być \t dla klawisza poziomego oraz \n dla końca linii. Przystępna lista zdefiniowanych wcześniej znaków znajduje się tutaj.
Jak używać przechwytywania i odwołań wstecznych
Kiedy przed fragmentem składni regex znajduje się nawias okrągły, to tworzona jest wtedy grupa przechwytująca. Powiedzmy, że chcemy dopasować tag HTMLa - możemy wtedy wykorzystać następujące wyrażenie regularne: /<([a-z]\w*)\b[^>]*>/.
Przyjrzymy się temu dokładniej:
- Tagi HTMLa zaczynają się na
<i kończą na> [a-z]będzie pasowało do każdej małej litery w alfabecie\w*dopasuje się do każdego znaku alfanumerycznego, razem z podkreśleniem\bsprawdza, czy to początek lub koniec słowa[^>]*dopasowuje się do jakiegokolwiek znaku, oprócz>.
Ten regex dopasuje tagi: <div>, <span>, <something> itd. W przykładzie tym przechwytujemy nazwę tagu, czyli ([a-z]\w*), która jest częścią tego, co znalazł regex (np. div, span, something).
Wypróbujcie sami tutaj.
Powiedzmy, na przykład, że chcemy, aby nasze wyrażenie regularne pasowało do odpowiedniego elementu HTML, który rozpoczyna się tagiem i kończy się takim samym tagiem: <div>something</div>. Chcemy tutaj dokonać referencji do tagu, który uprzednio przechwyciliśmy. Notacja odwołania wstecznego to ukośnik wsteczny, a po nim numer grupy przechwytującej, do której chcemy się odwołać: jest to \1.
Nasz przykład ma tylko jedno przechwycenie. Aby dopasować się do pełnego elementu HTML, wyrażenie regularne będzie wyglądało następująco: /<([a-z]\w*)\b[^>]*>.*?<\/\1>/.
Przyjrzyjmy się temu dokładniej:
.*?dopasuje każdy znak, oprócz końca linii<\/\1>dopasuje tag zamykający.<pasuje do literału, a\/do/.\1to odwołanie wsteczne do naszego przechwycenia, a>pasuje do swojego literału.
To wyrażenie regularne będzie pasować do następujących ciągów znaków: <div> <i>something</i> </div>, <span>my span</span>, itd. Taki ciąg znaków jak <div> something</other> nie będzie zatem pasował. Nie jesteśmy w stanie dopasować prostego elementu HTML bez odwołania wstecznego.
Jak wyrażenia regularne zostają dopasowane?
Silnik wyrażeń regularnych JS wykorzystuje dopasowywanie wzorców, które określamy jako Nondeterministic Finite Automaton. Finite Automaton (lub FA) to model obliczeniowy wykorzystywany do akceptowania i odrzucania ciągów znaków składających się z symboli.
Dla uproszczenia: Finite Automation składa się ze skończonego zbioru stanów z możliwymi przejściami między nimi. Przetwarzanie wejściowego ciągu znaków polega na tym, że każdy znak zostanie sprawdzony pod kątem tego czy pasuje do zdefiniowanych stanów i przejść.
Wróćmy do naszego pierwszego przykładu: /Medi[a-zA-Z]*/. Jeśli chcielibyśmy go pokazać jako graf FA, to wyglądałby mniej więcej tak:
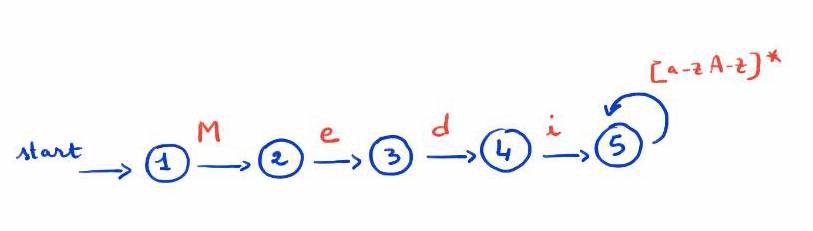
/Medi[a-zA-Z]*/ jako FA
Spójrzmy na kolejny przykład. Załóżmy, że mamy takie oto wyrażenie regularne: /Medi(um|cal|cine)/. Jego FA będzie wyglądało następująco:
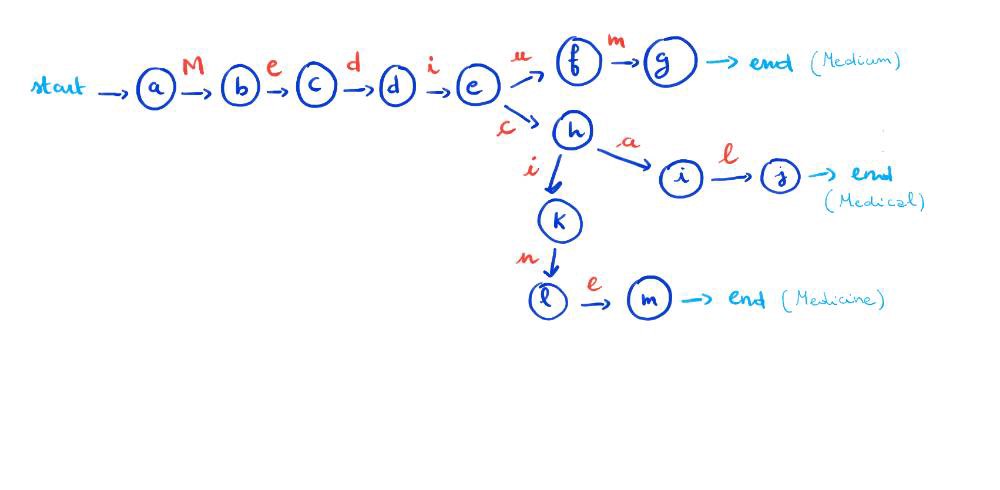 /Medi(um|cal|cine)/ jako FA
/Medi(um|cal|cine)/ jako FA
Jeśli przetestujemy to wyrażenie z Medium, Medical, czy Medicine, to skupi się ono na jednym z tych elementów. Jeśli jednak regex sprawdzi inputMedicinal, to najpierw dopasuje M, e, d, i (którego stanem będzie e). Potem natomiast dopasuje c, przejście do stanu k i na końcu l.
Obecnie mamy Medicin. Następną literą jest a, a automata nie pasuje, więc nie możemy przejść do m.
Automata wycofa się (ang. backtrack) do stanu h i spróbuje dopasować do innej ścieżki. Nie ma tutaj możliwego dopasowania. Nastąpi więc wycofanie się do stanu e, a tam również nie ma perspektyw na dopasowanie. Cały proces zakończy się wtedy niepowodzeniem.
FA określa się jako niedeterministyczne, ponieważ, gdy staramy się dopasować wyrażenie regularne do jakiegoś wejścia (np. Medicinal), to każdy znak w wejściowym ciągu znaków może być kilka razy sprawdzany, jeżeli chodzi o różne fazy automaty.
Jak optymalizować wyrażenia regularne
Nawet w tak prostym przykładzie, jak ten powyżej, widzieliśmy, że silnik musiał wycofywać się kilka razy, zanim zadeklarował niepasujące wejście.
Istotną częścią optymalizowania wyrażenia regularnego jest zmniejszenie ilości wycofań wykonanych przez silnik. Potrzeba mu więcej czasu na określenie, że wejście nie jest dopasowaniem, niż na określenie dopasowania, które się udało.
Im wcześniej stwierdzimy, że wejście nie pasuje, tym lepiej.
Oto słynny przykład niepoprawnego wyrażenia regularnego: /^(\w+\s?)*$/. W przykładzie tym staramy się dopasować słowa \w+ z opcjonalnym znakiem spacji \s?.
Jeśli postaramy się dopasować ten string: nie spowoduje to jakiegoś strasznego wycofywania się, ale silnik będzie potrzebował 26 kroków, aby stwierdzić, że mamy dopasowanie.
Jeśli jednak spróbujemy ewaluować nasze dane wejściowe: spowoduje to tak bardzo katastrofalne wycofywanie się, że zużycie procesora będzie na poziomie 100%. Jeśli wydarzy się to w przeglądarce, UI zawiesi się, a przeglądarka może ponownie załadować stronę.
A wszystko to dlatego, że zauważenie brakującego . zajmuje za dużo czasu.
Aby dobrze zoptymalizować swoje wyrażenia regularne, trzeba pamiętać o następujących rzeczach.
Mądrze używaj znaku alternatywy
Takie wyrażenia regularne, jak /(A|B|C)/ mają reputację powolnych, i traktują A, B i C jako skomplikowane części wyrażenia regularnego, które będą wymagały wycofywania.
W niektórych przypadkach alternatywy można uprościć. Zamiast pisać /(abc|abba)/, w którym to przypadku abc i abba nie wykluczają się wzajemnie, wyrażenie regularne można uprościć w taki oto sposób: /ab(c|ba)/.
Wyrażenie to jest szybsze, ponieważ wyszukiwarka spróbuje dopasować ab i nie wycofa się, jeśli nie ma dopasowania.
Przechwytuj grupy tylko wtedy, gdy zamierzasz użyć zawartego w nich tekstu
Przechwytywanie to bardzo przydatna funkcja wyrażeń regularnych, ale jeśli nie zamierzasz używać wyodrębnionego tekstu, to nie musisz z niej korzystać.
W poprzednim przykładzie nie musieliśmy przechwytywać c ani ba. Możemy przekształcić to w grupę nieprzechwytującą w następujący sposób: /ab(?:c|ba)/.
Optymalizacja kwantyfikatorów zachłannych
Kwantyfikator zachłanny, np.* lub +, najpierw spróbuje dopasować jak najwięcej znaków z wejściowego stringu, nawet jeśli oznacza to, że string ten nie będzie miał wystarczającej ilości znaków, aby dopasować resztę wyrażenia regularnego.
Jeśli tak się stanie, kwantyfikator zachłanny wycofa się, zwracając znaki, dopóki nie zostanie znalezione ogólne dopasowanie lub nie będzie więcej znaków.
Kwantyfikator leniwy spróbuje natomiast najpierw dopasować jak najmniej znaków w ciągu wejściowym.
W wielu przypadkach kwantyfikatory zachłanne można łatwo zastąpić kwantyfikatorami leniwymi. Załóżmy, że chcemy zoptymalizować część wyrażenia regularnego. Niech to będzie Med.*M.
Jeśli m znajduje się blisko końca łańcucha wejściowego, to lepiej jest użyć zachłannego kwantyfikatora *. Jeśli znak znajduje się blisko początku wejściowego ciągu znaków, lepiej byłoby użyć leniwego kwantyfikatora *? i zmienić wyrażenie podrzędne na Med.*?m.
Bycie konkretnym to podstawa
Pisząc wyrażenie regularne, to im bardziej są one dokładne, tym lepiej. Ogólnych wyrażeń podrzędnych, takich jak. *, używaj oszczędnie, ponieważ mogą powodować częste wycofywanie się silnika - szczególnie, gdy reszta wyrażenia nie pasuje do wejściowego ciągu znaków.
Powinno się raczej używać bardziej specyficznej klasy znaków. Daje to większą kontrolę nad tym, ile znaków * zużyje silnik regex, dając Ci możliwość zatrzymania nadmiernego wycofywania się.
Kiedy nie używać wyrażeń regularnych
Wyrażenia regularne są często używane do sprawdzania poprawności danych wejściowych użytkownika, ale mogą też powodować negatywny UX - zwłaszcza gdy programista przyjmuje własne założenia dotyczące danych wejściowych użytkownika.
Powracającym problemem, który napotykam jako użytkownik, jest surowa weryfikacja adresu e-mail. Niektóre formularze wymagają, aby adres e-mail nie zawierał znaku +. A inne wymagają, aby nazwa użytkownika lub numer telefonu były ograniczone do określonych znaków.
Taka walidacja jest bezużyteczna i może frustrować użytkowników.
W niektórych przypadkach wyrażenia regularne mogą być kosztowne i trudne w utrzymaniu. Doświadczyłam tego z pierwszej ręki, gdy używałam Fluentld do przeanalizowania niektórych logów bazy danych.
Ten kontener ciągle sprawiał, że procesor osiągał 100% zużycia, gdy logi nie były zgodne z oczekiwaniami i nie można tam było dopasować wyrażenia regularnego.
Za każdym razem, gdy kontener przestawał działać, musiałam na nowo ogarniać jakieś złożone wyrażenie regularne, które napisałam kilka miesięcy wcześniej.
Jeśli spędzasz dużo czasu na analizowaniu dużego tekstu, rozważ napisanie parsera.
Dalsza lektura
- https://javascript.info/regular-expressions
- https://www.regular-expressions.info/catastrophic.html
- https://swtch.com/~rsc/regexp/regexp1.html
- https://www.rexegg.com/regex-explosive-quantifiers.html
- https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Cheatsheet
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.
