Zwiększenie wydajności klastra w Elasticsearch

Elasticsearch wykorzystujemy już od jakiegoś czasu jako naszej bazy szeregów czasowych. Co więcej, zamierzamy wyciągnąć z niego jeszcze więcej przy naszym nowym produkcie — Kudos Pro. Spojrzeliśmy jednak ostatnio na to, w jaki sposób używamy tej platformy, aby sprawdzić, czy wyciągamy z niej wszystko, co możemy.
Dochodzenie
Kiedy przyglądaliśmy się klastrowi, od razu zorientowaliśmy się, że nie używamy najnowszej wersji platformy. Mieliśmy 6.7 a 7.2 dopiero co się wtedy pojawiła. Chcieliśmy zatem najpierw dokonać aktualizacji.
Kiedy przyjrzeliśmy się dokładniej wydajności i zużyciu zasobów, zauważyliśmy, że używamy bardzo dużo pamięci dostępnej dla JVM, bo około 80% w naszym klastrze. Wyskoczyło nam wtedy duże powiadomienie ostrzegające o możliwym spadku wydajności.
 Ostrzeżenie w konsoli Elastic
Ostrzeżenie w konsoli Elastic
Sprawdziliśmy również historię naszego systemu ticketowego i, biorąc pod uwagę przeszłe przypadki, okazało się, że aktualizacja mogłaby zająć mnóstwo czasu. Co więcej, częsty kontakt ze wsparciem technicznym Elastic byłby konieczny do jej ukończenia.
Kolejnym problemem była zbyt duża liczba shardów w klastrze. Mamy tylko dwa węzły danych, a liczba shardów wynosiła ponad 3000 w 650 indeksach.
Okazuje się, że te problemy są ze sobą powiązane, a główną przyczyną problemu przy aktualizacji jest liczba shardów w klastrze. Zdecydowaliśmy się więc na rozwiązanie tego problemu, zanim przejdziemy do aktualizacji.
Zaczęliśmy dochodzić, dlaczego ta liczba jest tak wysoka w tak małym klastrze i odkryliśmy, że wersja, której używaliśmy ma w domyśle 5 shardów na indeks (co zostało zmienione w Elasticsearch 7).
Odkryliśmy również, że zbyt często zmieniamy indeksy, tworząc nowy co tydzień dla większości naszych przypadków użycia. Czasem robiliśmy to nawet codziennie. Indeksy te były niewielkie, średnio około 2 MB na indeks.
Korekcja
Najpierw postanowiliśmy zająć się częstotliwością roll overu indeksów.
Indeksami, które tworzyliśmy codziennie od nowa, były, na przykład, Heartbeat, Watches i SLO. Większość tych danych ma znaczenie tylko przez miesiąc od ich zebrania, więc zdecydowaliśmy się usunąć indeksy, które były starsze niż 60 dni.
Posiadamy job Kubernetesa, który działa codziennie i w takich przypadkach wywołuje Elasticsearch Curator. Dodaliśmy więc do kuratora zadanie usunięcia tego typu indeksów po 60 dniach.
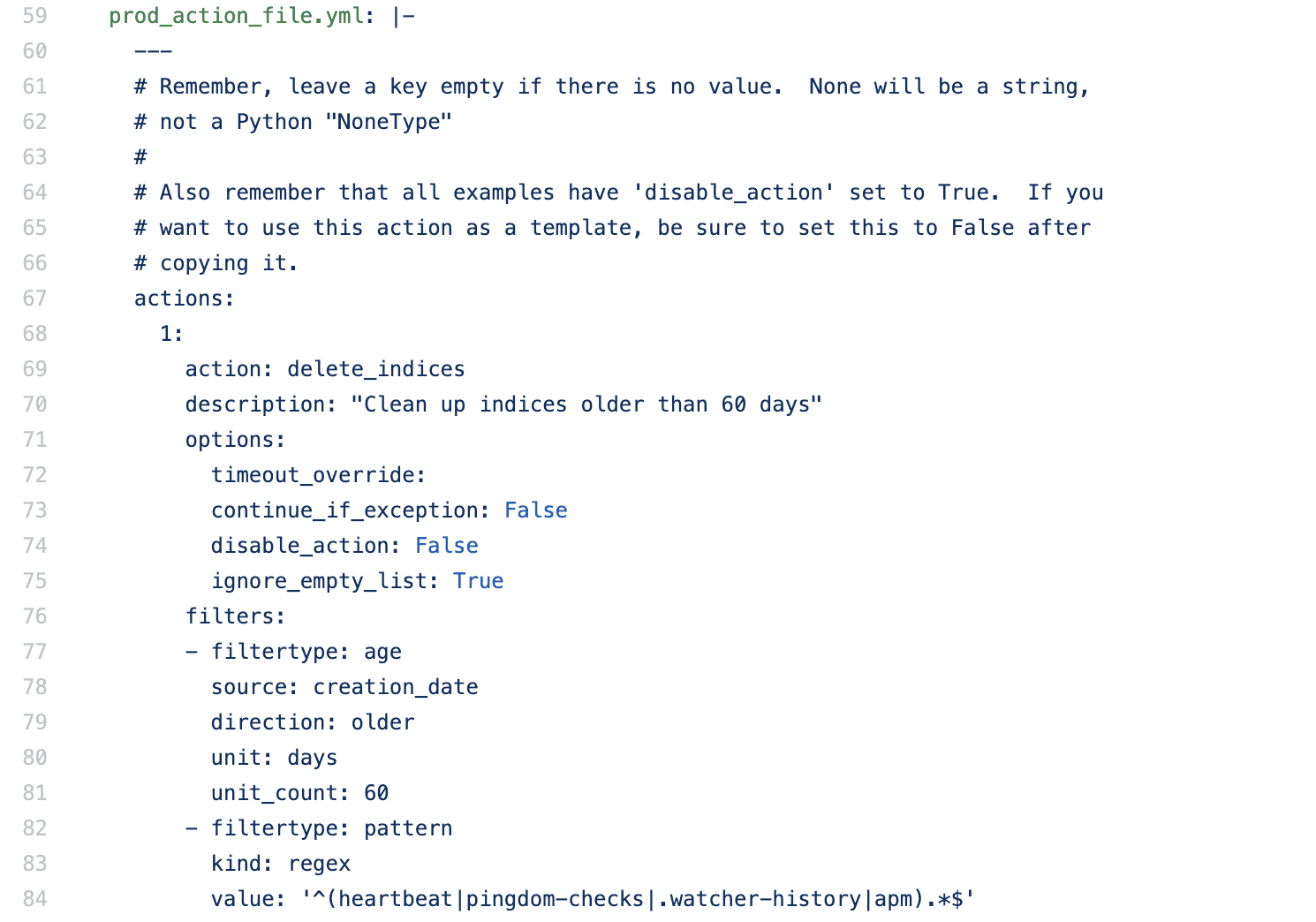
Pomogło nam to w zmniejszeniu liczby shardów i indeksów o około 350, ale nadal mieliśmy ponad 1000 shardów na węzeł.
 Limit miękki shardów na węzeł
Limit miękki shardów na węzeł
Następnie przeszliśmy do indeksów odnawianych co tydzień. Tutaj mieliśmy do czynienia z takimi rzeczami, jak raportowanie danych i budowanie metryk monitoringu, które zostały pozyskane przy użyciu Logstash działającego na Kubernetesie.
Większość danych była mała, czasami nawet kilka megabajtów na indeks, więc postanowiliśmy zmienić użycie na indeksy omawiane co roku, aby zaoszczędzić miejsce i zmniejszyć liczbę shardów.
Pierwszą rzeczą, jaką zrobiliśmy z indeksami była, zmiana na logstash, aby używać indeksów omawianych co roku. Ta prosta zmiana w konfiguracji razem z nowymi danymi zostały wczytane do corocznego indeksu. Nazwy były do siebie podobne, więc pasowały do wzorca indeksu ustawionego w Kibana na raportowanie.
 Zmiana na indeks omawiany co roku
Zmiana na indeks omawiany co roku
Kiedy już stworzyliśmy nowy indeks, który będzie nam służyć przez rok, musieliśmy przenieść wszystkie dane z wielu mniejszych indeksów do jednego dużego. Aby to zrobić, napisaliśmy skrypt w Pythonie, który miał stworzyć listę indeksów cotygodniowych dla każdego roku, przeindeksował je w indeksy omawiane co roku i usunął stary indeks omawiany co tydzień (po sprawdzeniu, czy dane zostały poprawnie przeniesione).

Kiedy to zrobiliśmy, udało nam się zredukować liczbę indeksów i shardów w klastrze z odpowiednio 650 i 3000 do 270 i 300.
Miało to ogromny wpływ na klaster, zmniejszając jego użycie pamieci JVM z 80% na 40% na każdym węźle.
Nie chcąc zaprzepaścić naszego sukcesu, musieliśmy zapewnić, aby wszystkie nasze indeksy były tworzone z odpowiednią ilością shardów. Zmodyfikowaliśmy więc template indeksów z logstash i ustawiliśmy ją na użycie jednego sharda na indeks (nowe ustawienie domyślne).

Przyjęliśmy podejście Infrastructure as a code i zapisaliśmy szablon indeksu w repozytorium ze skryptem Pythona, który sparsuje JSON i wstrzyknie go do API Elasticsearcha. W ten sposób zespół inżynierów może zmienić szablon indeksów i zastosować go w ten sam sposób za każdym razem.
Aktualizacja
Po wprowadzeniu nowego schematu indeksów i przeniesieniu danych do indeksów tworzonych raz na rok mogliśmy sprawdzić narzędzie do aktualizacji w Kibanie, by zobaczyć, czy mamy już wszystko.
Kilka ustawień wymagało aktualizacji. Były to głównie ustawienia powiadomień dla czynności pilnowaniu systemu, które musiały zostać przeniesione do key store w panelu sterowania Elasticsearch.
Następnie rozpoczęliśmy aktualizację. Przeszliśmy z 6.7 do 6.8, aby sprawdzić, czy zmiany, które wprowadziliśmy miały wpływ na wydajność procesu aktualizacji.
Sukces! ?
Byliśmy w stanie przejść na kolejną wersję minor bez problemu.
Kolejnym krokiem była aktualizacja do wersji major 7.2.
Dzięki Elastic Cloud taki update można zrobić za pomocą kliknięcia myszką. Upewniliśmy się, że mamy kopię zapasową wszystkich indeksów z naszego klastra, którą wgraliśmy na bucket GCS i rozpoczęliśmy aktualizację.
Niestety nie poszło gładko.
Jeden z węzłów głównych nie przeszedł poprawnie w tryb online, więc klaster utknął na chwilę w stanie zawieszenia między wersjami 6.8 a 7.2. Udało nam się uruchomić i zakończyć aktualizację do wersji 7.2, ale węzły 6.8 były nadal uruchomione i skonfigurowane.
Ostatecznie skontaktowaliśmy się ze wsparciem technicznym z Elastic, a oni wkrótce rozwiązali problem.
Podsumowanie
To była długa przeprawa, ale pod koniec nasz klaster Elasticsearch działał w wersji 7.2 i przy okazji lepiej go dostosowaliśmy do tego, jak go używamy. Zużycie pamięci JVM jest znacznie niższe i mamy też rozsądne wartości domyślne dla shardów.
Dowiedzieliśmy się przez to wiele o Elasticsearch i sposobie administrowania klastrem, co dało nam lepsze zrozumienie tego, w jaki sposób możemy dalej korzystać z niektórych funkcji.
Oryginał tekstu w języku angielskim przeczytasz tutaj.