

XSolve (Boldare now)
WTF - otwarty framework do testowania aplikacji webowych
Tworzenie open source w czasie pracy to nie mrzonka. XSolve stworzyło swój framework do testów end-to-end.
XSolve Web Testing Framework to framework służący do automatyzacji testów End-To-End (E2E) aplikacji webowych. Powstał w ramach firmowej inicjatywy „10% czasu na open-source” i został udostępniony na licencji MIT. Jest już używany w kilku komercyjnych projektach.
Jednym z celów powstania frameworka było umożliwienie pisania w prosty sposób testów przydatnych zarówno dla dev-teamu jak i „biznesu”. Z tego powodu dosyć mocno zostały rozbudowane logi z wykonywania testów. Dla „biznesu” użyteczne będą raporty - scenariusze Gherkinowe, które w języku naturalnym opisują wykonywane testy oraz screenshoty, które wizualizują błędy. Dev-teamowi mogą przydać się natomiast bardziej „niskopoziomowe” logi, jak historia requestów zbierana przez proxy, czy log z przeglądarkowej konsoli.
Metody udostępniane przez framework są wysokopoziomowe oraz posiadają wbudowane waity, co znacząco upraszcza pisanie testów. Prostota pisania testów została dowiedziona w czasie wewnątrzfirmowych szkoleń dla stażystów, którzy byli w stanie w krótkim czasie wdrożyć się do nowej dla nich technologii i zacząć pisać użyteczne z punktu widzenia projektu testy.
Nasz Web Testing Framework jest dostępny na githubie i NPMZałożenia
Język
Framework został napisany w języku JavaScript. Powodów jego wyboru było kilka, ale najważniejszy to zdecydowanie jego popularność w przypadku aplikacji webowych. Pisanie testów w języku wykorzystywanych przez developerów ma tę zaletę, że eliminuje problemy ze znalezieniem osób mogących wykonać ich późniejsze Code Review. Code Review wykonywane przez osoby specjalizujące się w danej technologii jest też najbardziej wartościowe - nie ogranicza się do samego sprawdzenia ogólnych założeń. W przypadku języków takich jak Python czy Java byłby to już problem.
Selenium Webdriver
Najprawdopodobniej najczęściej wykorzystywanym bezpośrednio lub pośrednio narzędziem służącym do automatyzacji testów E2E aplikacji webowych jest Selenium Webdriver. Bindingi Selenium Webdrivera są dostępne również dla języka JavaScript (chociaż są uproszczone w porównaniu do tych dla PHP, Pythona czy Javy). Selenium Webdriver został wykorzystany również w przypadku XSolve Web Testing Framework.
Gherkin - przydatność z punktu widzenia „biznesu”
Testy E2E powinny być przydatne nie tylko z punktu widzenia dev-teamu. Ważnym „odbiorcą” testów jest również „biznes” - testy powinny być w miarę możliwości zrozumiałe również dla osób nietechnicznych. Z tego powodu jako warstwa BDD został użyty Gherkin. Przy odpowiednim użyciu narzut na pisanie warstwy gherkinowej jest minimalny, a sam Gherkin ma dużo zalet również dla dev-teamu - generuje czytelne raporty z wykonania testów, ułatwia tworzenie bug-reportów itp.
Logi
Głównym celem testów E2E jest potwierdzenie, że aplikacja działa poprawnie. Bardzo ważną rzeczą jest jednak możliwość szybkiej identyfikacji błędu w przypadku „czerwonego” testu. W takich przypadkach każda informacja mogąca ułatwić odtworzenie błędu lub jego naprawę może być przydatna.
- Gherkin
Pierwszym poziomem logów są scenariusze gherkinowe. Są to właściwie kroki umożliwiające odtworzenie błędu, które nie tylko, że mogą być użyte w bug reporcie, ale również będą zrozumiałe dla klienta. - Screenshot
Kolejnym, często używanym outputem testów są screenshoty - umożliwiają zobaczenie jak wysokopoziomowo wygląda testowana aplikacja w momencie faila testu. - Proxy - HAR (HTTP ARchive)
Bardzo przydatnym z punktu widzenia developerów logiem jest zdecydowanie HAR. Umożliwia prześledzenie poszczególnych requestów co może być bardzo przydatne przy próbie identyfikacji problemu. Do ich zbierania zostało użyte proxy, pliki HAR są zapisywane dla wszystkich scenariuszy. - Logi z konsoli przeglądarki
Dla frontend developerów przydatny może być log z przeglądarkowej konsoli. - Logi Selenium
Selenium driver log może być natomiast bardzo użyteczny dla QA przede-wszystkim podczas pisania nowych testów. - Logi Frameworka
Uzupełnieniem powyższych logów może być dodatkowo log z frameworka - zarówno ogólny, w przypadku faila poszczególnych metod, jak i dokładny - informacyjny, który ułatwia prześledzenie działania testów. - Inne
Z innych logów, które mogą się okazać przydatne, ale których obsługa nie jest jeszcze zaimplementowana po stronie frameworka można wymienić np. logi z web-servera. Źródłem logów mogą być również narzędzia specyficzne dla użytej w projekcie technologii - w przypadku backendu w PHP i Symfony użyteczne mogą się okazać logi z Symfony profilera.
Łatwe oraz szybkie pisanie testów
Ograniczeniem tego, ile da się przetestować w projektach komercyjnych prawie zawsze jest budżet - praktycznie niemożliwe jest przetestowanie aplikacji tak skrupulatnie, jakby się chciało. Sam framework ma jednak istotny wpływ na szybkość pisania testów.
- Wysokopoziomowe metody
Wysokopoziomowe metody udostępniane przez framework umożliwiają szybsze pisanie testów, dodatkowo znacznie je ułatwiając. Dostępność wysokopoziomowych metod nie ogranicza jednak użytkownika - niskopoziomowe metody Selenium Webdrivera są również dostępne i mogą zostać użyte gdy jest to potrzebne. - Wbudowane waity
Metody frameworkowe posiadają wbudowane waity, co znacznie upraszcza ich użycie. Użytkownik zachowuje jednak nad nimi kontrolę - domyślnie zostaną użyte wartości z pliku konfiguracyjnego config.json, można jednak również wybrać niestandardową wartość podczas wywoływania poszczególnych metod.
Stabilność
Dev-team nie będzie miał zaufania do testów jeżeli ich rezultaty nie będą powtarzalne dla danej wersji aplikacji, gdy niektóre testy randomowo będą „czerwone”. Najczęściej pojawiającymi się przyczynami niestabilności testów, jakie miałem okazję widzieć były niepoprawnie użyte waity oraz zmiany stanu aplikacji w czasie wykonywania danej akcji. Wbudowanie dynamicznych waitów do metod frameworkowych ma jeszcze jedną zaletę poza łatwością używania czy szybkością pisania testów - poprawia stabilność testów.
Headless
Testy E2E często uruchamiane są na serwerach headlessowych. Często polecane przeglądarki headlessowe jak np. PhantomJS nie odpowiadają rzeczywistym przeglądarkom. PhantomJS używa forkowanej wersji silnika QTWebKit z biblioteki Qt, która znacząco różni się nawet od silnika Webkit używanego w przeglądarce Safari. Testy E2E uruchamiane na tego typu przeglądarkach nie zagwarantują, że aplikacja działa poprawnie.
Jedną z możliwości uruchomienia testów headlessowo na rzeczywistej przeglądarce jest użycie linuksowego narzędzia Xvfb (X virtual framebuffer), które umożliwia stworzenie wirtualnego ekranu wewnątrz, którego uruchomiona może zostać rzeczywista przeglądarka jak Chrome czy Firefox. W przypadku przeglądarek niedostępnych dla systemu Linux możliwe jest natomiast użycie Remote Drivera i podłączenie się do maszyny wirtualnej lub któregoś z serwisów chmurowych udostępniających przeglądarki do testów.
Metody
Framework udostępnia metody które najogólniej można podzielić na akcje, validatory i „inne”.
Akcje to metody umożliwiające wykonanie określonych zadań w przeglądarce - jak np. kliknięcie. Validatory natomiast umożliwiają weryfikację rezultatu wykonanych akcji.
Zarówno akcje jak i validatory wykonywane są w kontekście elementu na stronie - można np. kliknąć w element oraz można sprawdzić czy np. element jest widoczny. Same elementy identyfikowane są za pomocą XPathów.
Pełna lista dostępnych metod razem z ich opisami znajduje się w dokumentacji na Githubie, tutaj zostanie przedstawionych kilka przykładowych.
Akcje:
click(xpath, customTimeout)Metoda click umożliwia kliknięcie w element identyfikowany przy pomocy XPatha przekazanego parametremxpath.customTimeoutto parametr opcjonalny, umożliwiający określenie maksymalnego czasu, jaki może zająć wykonanie akcji. W przypadku braku zostanie użyta wartość domyślna z pliku konfiguracyjnego frameworka.loadPage(url, customTimeout)umożliwia otwarcie strony podanej jako argument
loadPageurl.
ParametrcustomTimeoutpodobnie jak w przypadku metodyclickjest opcjonalny.- Ważniejsze akcje:
fillInInputsetCheckboxValue- ustawienie wartości checkboxa - true / falsesetFileInputValuesleep- statyczny sleepcleanBrowserState- czyszczenie stanu przeglądarki (cookies, localStorage, sessionStorage, console log)
Walidatory:
- Get a Validate
We frameworku zostało przyjęte założenie że metody get zwracają wartość jak np. liczba elementów na stronie, tekst elementu itp. Metody validate służą natomiast do weryfikacji czy np. liczba elementów jest zgodna z podaną, czy tekst elementu jest zgodny z podanym.
Zasadniczą różnicą jest to, że get pobiera aktualny stan, natomiast w przypadku validate ważne jest przede wszystkim żeby do określonego czasu wartość była zgodna z oczekiwaną - jest to istotne szczególnie w przypadku dynamicznych stron gdzie wartość może się zmienić. Validate umożliwia więc przeniesienie logiki niżej - zamiast pobierać wartość w testach i następnie sprawdzać czy jest zgodna z oczekiwaną można użyć tu validatora.
Samą logikę można przenieść jeszcze niżej - do XPatha co może umożliwić weryfikację kilku wartości równocześnie. Zostało to przedstawione w poniższym przykładzie - validateElementDisplayed. validateElementDisplayed(xpath, customTimeout)
MetodavalidateElementDisplayedvaliduje, czy element identyfikowany za pomocą XPatha jest widoczny. Może to być prosty element, jak i bardziej rozbudowany XPath w stylu przedstawionego poniżej weryfikujący 2 wartości równocześnie. XPath ten znajduje element div, który zawiera 2 elementy-childy span o określonych wartościach.![]()
- Ważniejsze metody:
getCurrentUrl,validateUrl,validateUrlByRegexvalidatePageReadyStatevalidateElementDisplayed/NotDisplayedvalidateElementVisible/NotVisiblevalidateElementsDisplayed/NotDisplayedgetCheckboxValue,validateCheckboxValuegetElementsNumbergetElementText,validateElementText

Inne metody
Pozostałe metody nie są związane bezpośrednio z samymi akcjami wykonywanymi na stronie, ale mogą być przydatne podczas pisania testów. Są to np. loggery oraz metody umożliwiające wykonanie screenshota, czy pobranie aktualnego czasu.
Konfiguracja
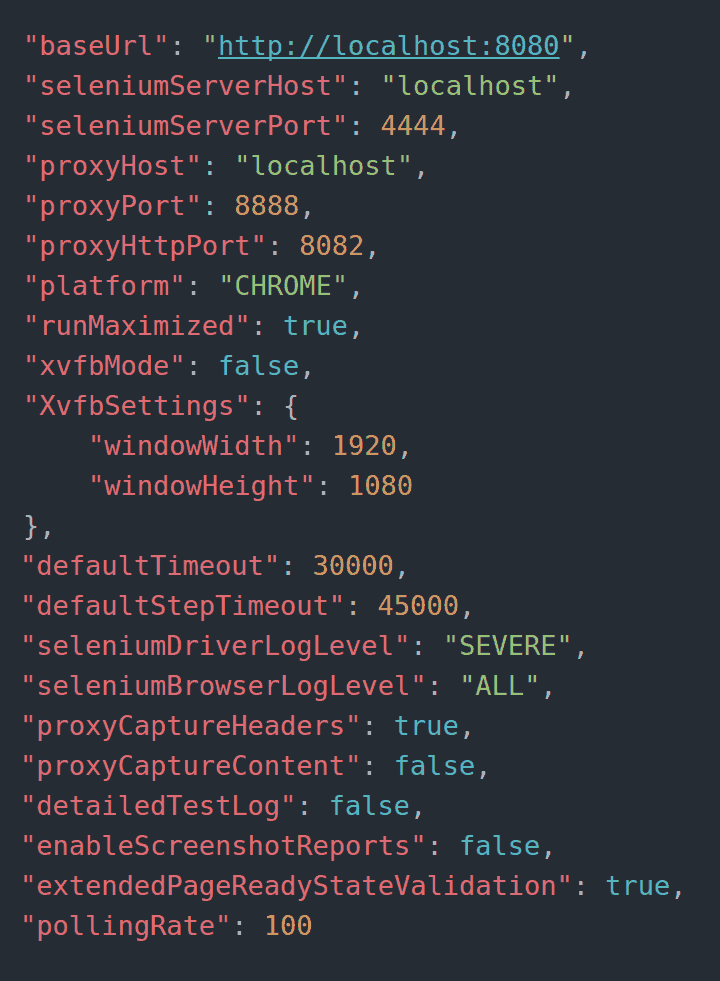
Konfiguracja frameworka odbywa się przy pomocy pliku config.json. Jest on wymagany przez framework - powinien znajdować się w głównym katalogu projektu. Zawiera najważniejsze ustawienia frameworka - od najbardziej podstawowych jak URL Selenium Servera, aż do bardziej zaawansowanych jak poziom logowania proxy, czy opóźnienia odpytywania Selenium Servera. Przykładowa konfiguracja została pokazana na obrazku, dokładniejsze informacje znajdują się w dokumentacji na Githubie.
Jak wyglądają testy?
Framework nie narzuca sposobu pisania testów poza tym że „u góry” muszą być scenariusze gherkinowe. Zostanie tu przedstawiona w skrócie jedna z możliwości jak mogą wyglądać testy.
Gherkin
W katalogu features znajdują się pliki .feature zawierające scenariusze gherkinowe dla poszczególnych funkcjonalności. W poniższym przykładzie znajduje się przykładowy scenariusz weryfikujący poprawność działania jednej z funkcjonalności przykładowego sklepu internetowego - kupowania produktu.
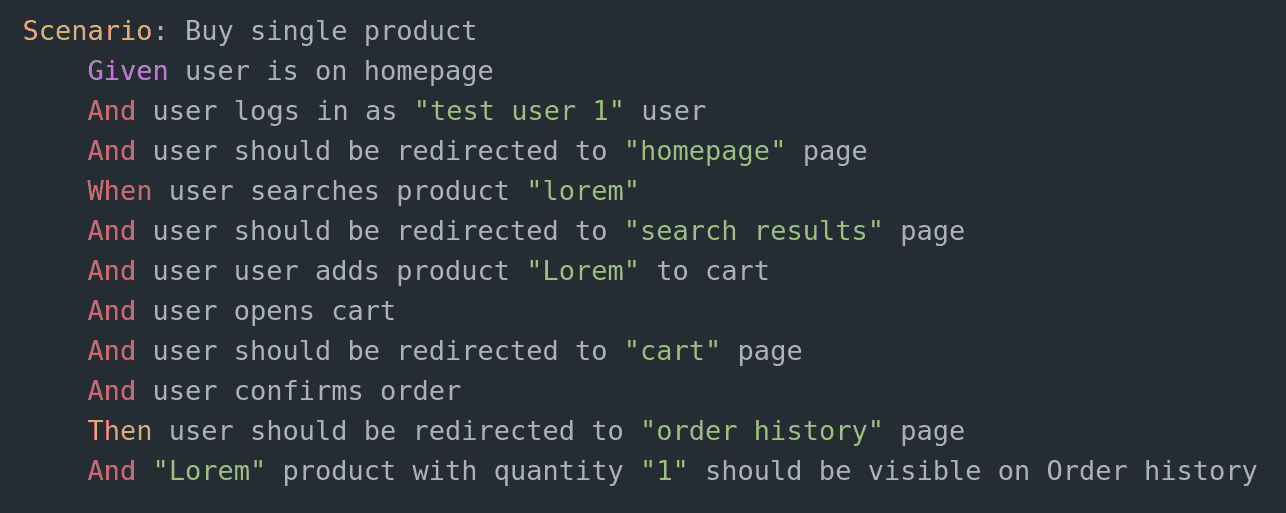
Kroki są wysokopoziomowe - opisują całe akcje. Stepy opisujące całe akcje jak dodanie określonego produktu do koszyka są zrozumiałe dla „biznesu” czy dev-teamu a równocześnie ograniczają narzut związany z pisaniem scenariuszy. Dodatkowo ewentualne zmiany po stronie aplikacji nie powodują najczęściej konieczności przepisywania znacznej części scenariusza - wystarczą zmiany „pod spodem”.
Dane testowe w większości przypadków nie są umieszczane bezpośrednio w Gherkinie a jedynie używna jest czytelna nazwa, która pozwala je pobrać.
Step->Context
Na przykładzie logowania zostanie pokazane jak mapowane są poszczególne stepy z odpowiadającymi im akcjami.
![]()
Metody „contextowe” generowane są automatycznie przez Cucumbera - wystarczy nazwać użyte parametry (w tym przypadku userName) i wywołać potrzebną metodę z odpowiedniego Page.

W tym przypadku testowany formularz logowania znajduje się na stronie głównej - metoda logIn służąca do logowania znajduje się więc w Page’u HomePage (strona główna jest bardzo uproszczona więc nie jest tu potrzebny osobny Page jak np. LoginPage). Tutaj jedynie jest wykonana odpowiednia metoda i przekazany jej jest parametr - nazwa użytkownika (“test user 1”). Właściwa logika znajduje się już w metodzie Page’owej.
Page

Widoczna tutaj metoda logIn wypełnia pole login, wypełnia pole hasło oraz klika w przycisk logowania. Dane testowe jak nazwa użytkownika czy hasło są pobierane z pliku z danymi testowymi metodą getUserData. Odpowiedni użytkownik w danych testowych identyfikowany jest za pomocą nazwy przekazanej w parametrze userName.
Dane testowe
Dane testowe znajdują się w pliku testData.js. Może być to np. JSON zawierający wszystkie potrzebne wartości. Dane dotyczące użytkowników mogą być opisane np. jako userData. W przypadku scenariusza logowania wystarczające byłyby nazwa użytkownika i hasło, w innych scenariuszach mogą być jednak potrzebne również inne informacje opisujące tego użytkownika takie jak np. mail.
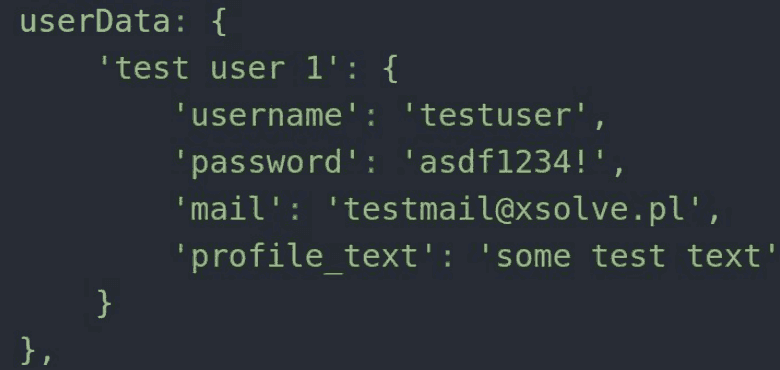
Sama metoda getUserData pokazana w poniższym przykładzie jedynie zwraca wartości dla danego użytkownika poprawiając czytelność w porównaniu do bezpośredniego pobrania wartości. Mogą się jednak zdarzyć przypadki gdy dane muszą zostać w jakiś sposób przetworzone.

Open-source
XSolve Web Testing Framework to nadal projekt młody - wiele funkcjonalności można jeszcze dopisać, jest również wiele możliwości udoskonalenia już istniejących. Zachęcam do uczestniczenia w rozwijaniu frameworka - zarówno w formie PRów, jak i w postaci sugestii co zmienić, poprawić itp.
Github: https://github.com/xsolve-pl/testing-framework
NPM: https://www.npmjs.com/package/xsolve_wtf
Tomasz Konieczny Senior QA Engineer w XSolve