Jak integrować 20 miliardów rekordów dziennie

Pewnie wiele osób czeka na moment, w którym wreszcie dostanie prawdziwie wielkie dane i zastanawia się jakie przeszkody napotka i jak trudne będą do rozwiązania.
Tak właśnie było w moim przypadku, brałem udział w wielu projektach, ale ciągle czułem niedosyt, chciałem więcej danych. W końcu doczekałem się, projekt, który mi przydzielono, polegał na zebraniu danych diagnostycznych z 225 tysięcy komórek LTE rozmieszczonych mniej lub bardziej równomiernie w całym kraju oraz udostępnieniu ich użytkownikom końcowym, czyli np. analitykom. Wstępnie oszacowaliśmy, że finalnie będziemy zbierać około 20 mld rekordów dziennie, czyli około 500GB skompresowanych danych. W wersji pilotażowej monitoringiem objęto około 10% sieci, a te ze względu na heterogeniczność urządzeń.
Architektura
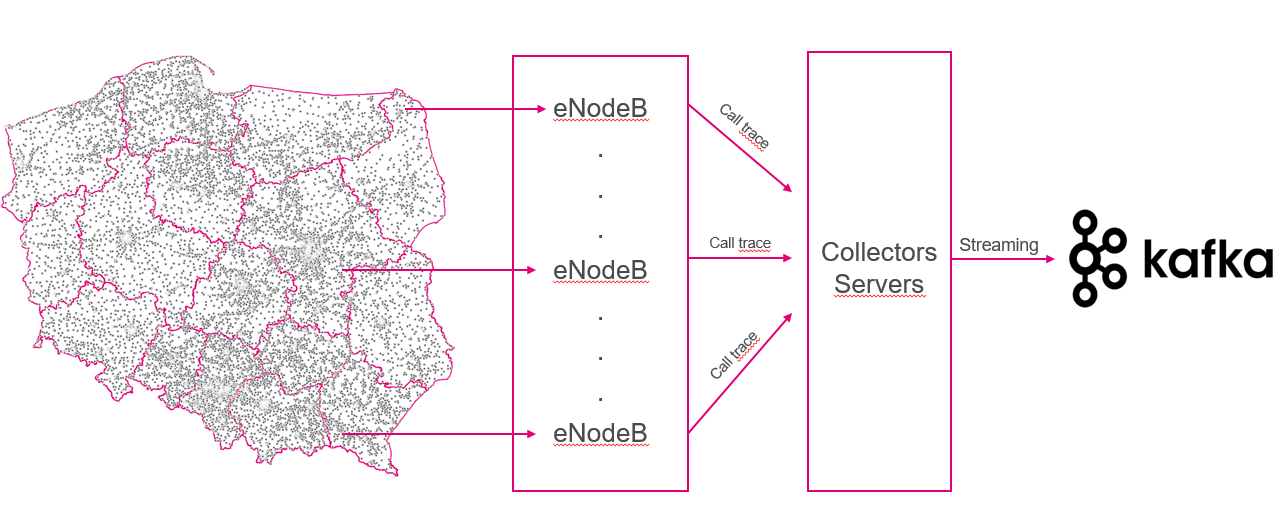
Sieć komórkowa jest podzielona na obszary, które potocznie nazywamy komórkami, każda z 225 tysięcy kropek na mapie reprezentuje środek ciężkości komórki, czyli miejsce w które „świeci” antena. Anteny w sieci LTE są połączone z eNodeB, odpowiednikiem stacji bazowej w sieci GSM.
Tu kończy się sieć LTE i zaczyna się cześć realizowana w ramach opisywanego projektu.
Call trace są agregowane w różny sposób przez Collector Serwery ze względu na to, że instancje eNodeB zostały wyprodukowane przez różne firmy. Następnie dane są wysyłane strumieniowo do Kafka.
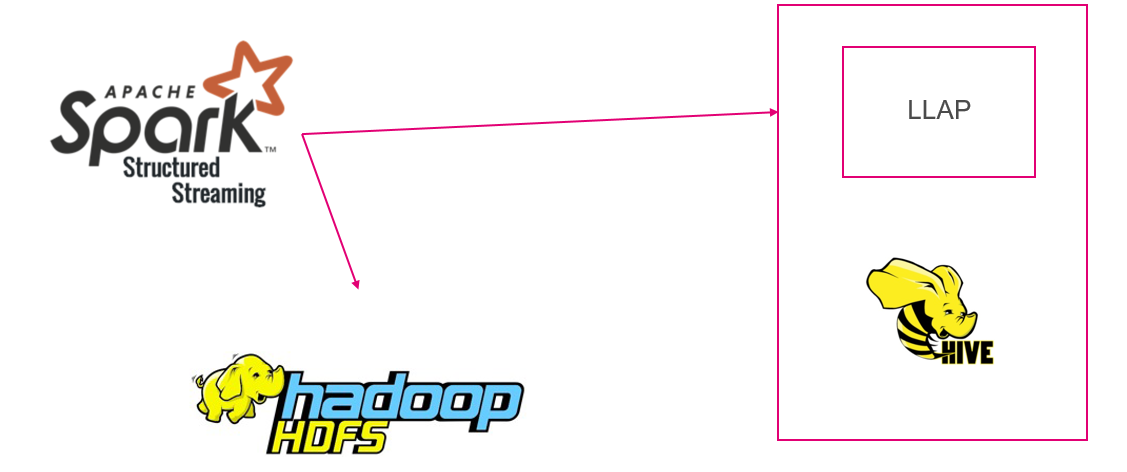
Z Kafka z pośrednictwem Sparka trafiają do zewnętrznej tabeli w Hive.
Implementacja
Projekt nie posiadał złożonej logiki biznesowej, wyzwaniem natomiast było dobranie odpowiednich komponentów i dostrojenie parametrów, tak żeby umożliwić bezawaryjne i wydajne działanie aplikacji.
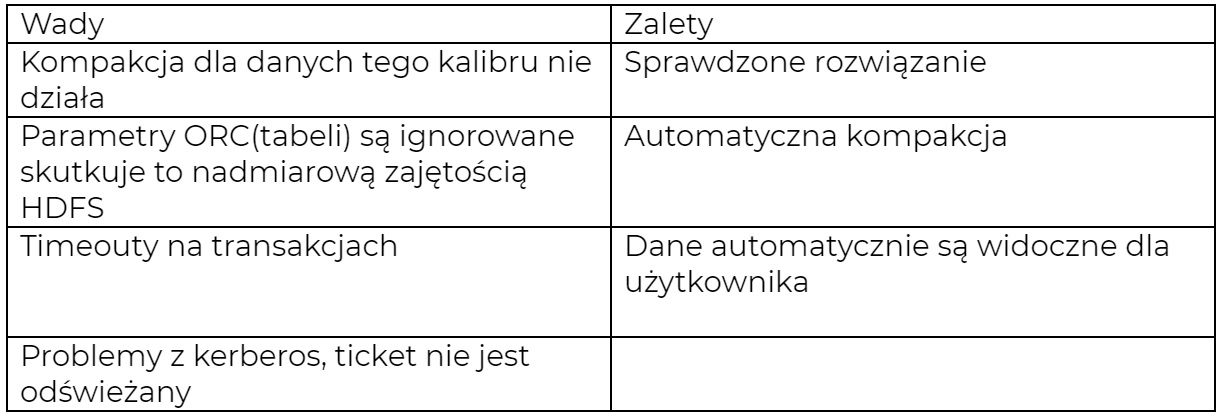
Pierwsza wersja aplikacji opierała się o Hive Warehouse Connector, zapis odbywał się bezpośrednio do tabeli transakcyjnej, jednak ilość problemów, jakie przysparzała — zmusiła nas do zmiany podejścia.
W poniżej tabeli znajdują się wady i zalety pierwszej wersji.
Druga – uproszczona wersja aplikacji to bezpośredni zapis na HDFS. Zyskaliśmy większą stabilność, jednocześnie pozbywając się wad pierwszej wersji.

Poniżej znajduje się dokładne zestawienie wersji komponentów użytych w aplikacji.
Komponenty

Monitoring
W Spark 2.X nie ma zakładki Streaming Statistics dla Structured Streaming
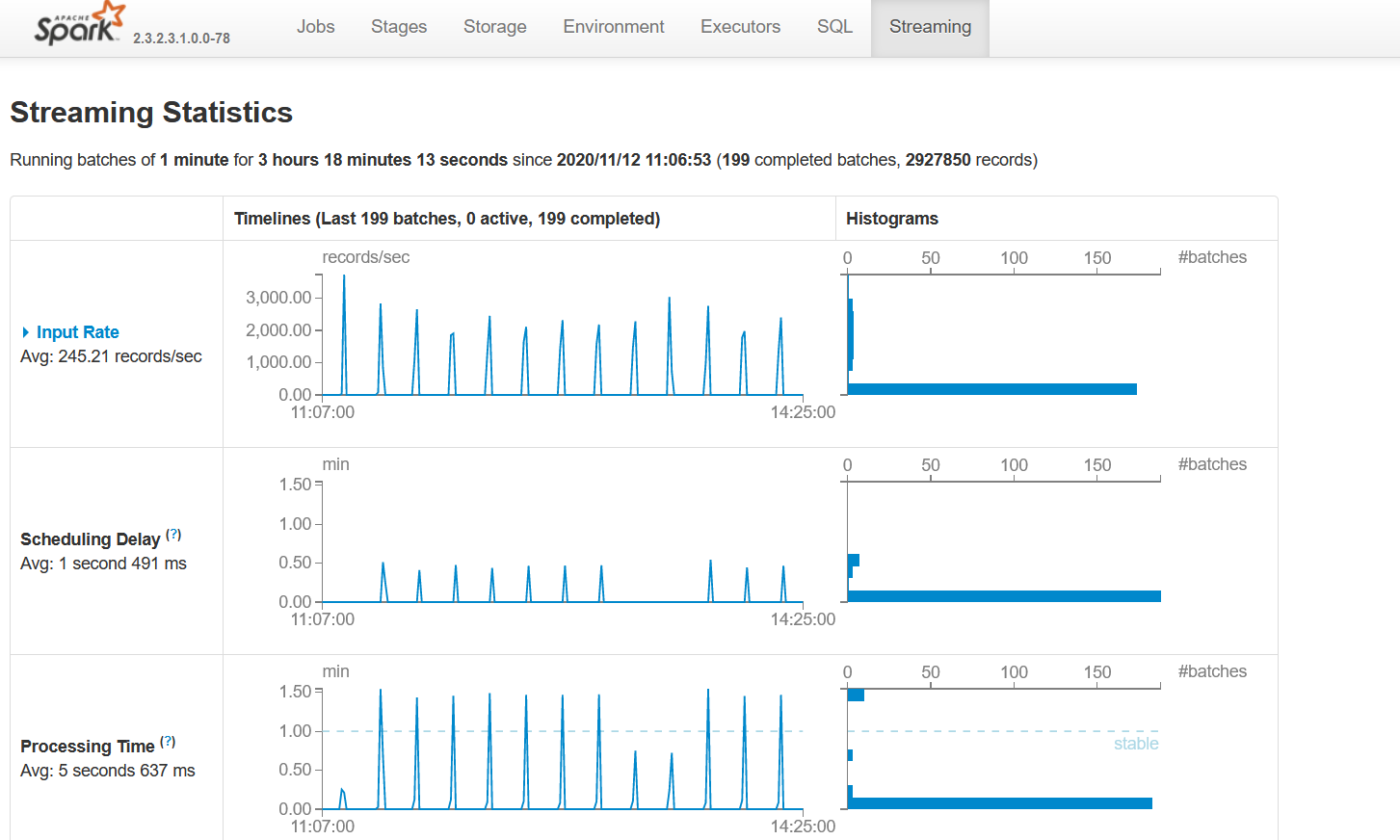
Na szczęście dostępny jest interfejs org.apache.spark.sql.streaming.StreamingQueryListener, który w połączeniu z informacjami, które można pobrać przez klienta Kafka, pozwala na implementację w zupełności wystarczającego monitoringu:
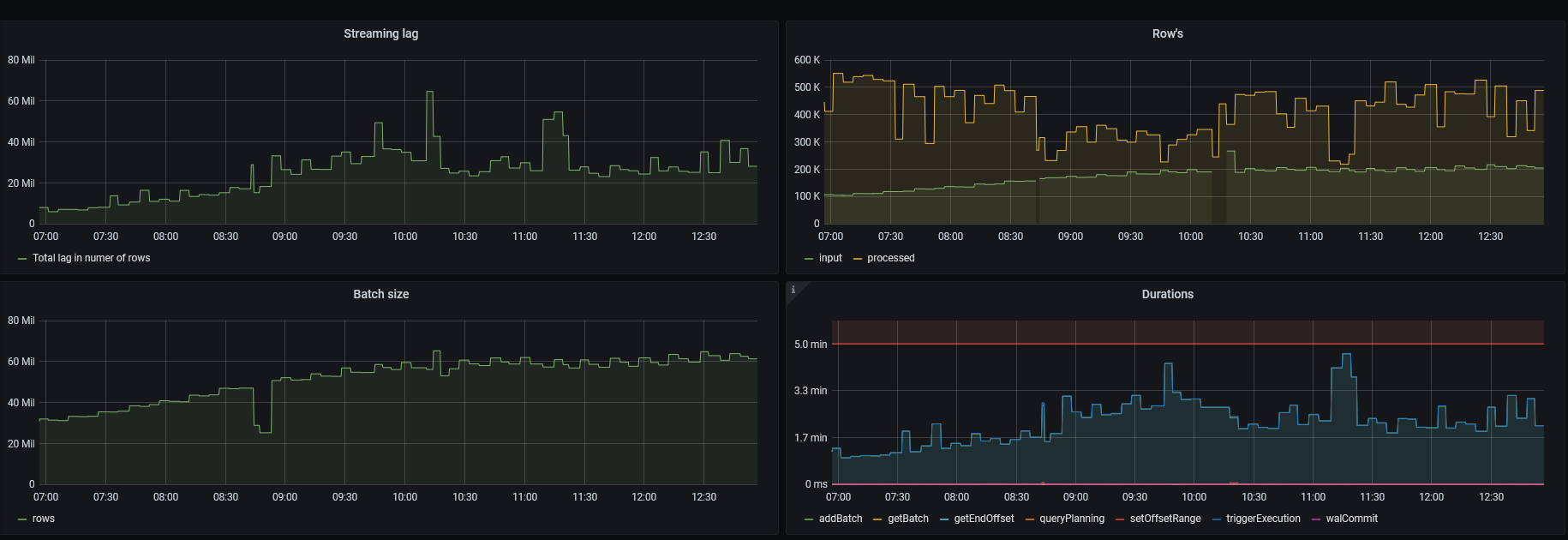
Tak jak wspomniałem wcześniej, monitoring komórek sieci LTE uruchamiano stopniowo, więc problemy też pojawiały się stopniowo ☺
Niestety węzły nie były w stanie przetworzyć danych na bieżąco
Bardzo pomocny okazał się parametr minPartitions, ustawienie na wartość równą dwukrotności ilości partycji kafka, pozwoliło na ustabilizowanie przetwarzania.
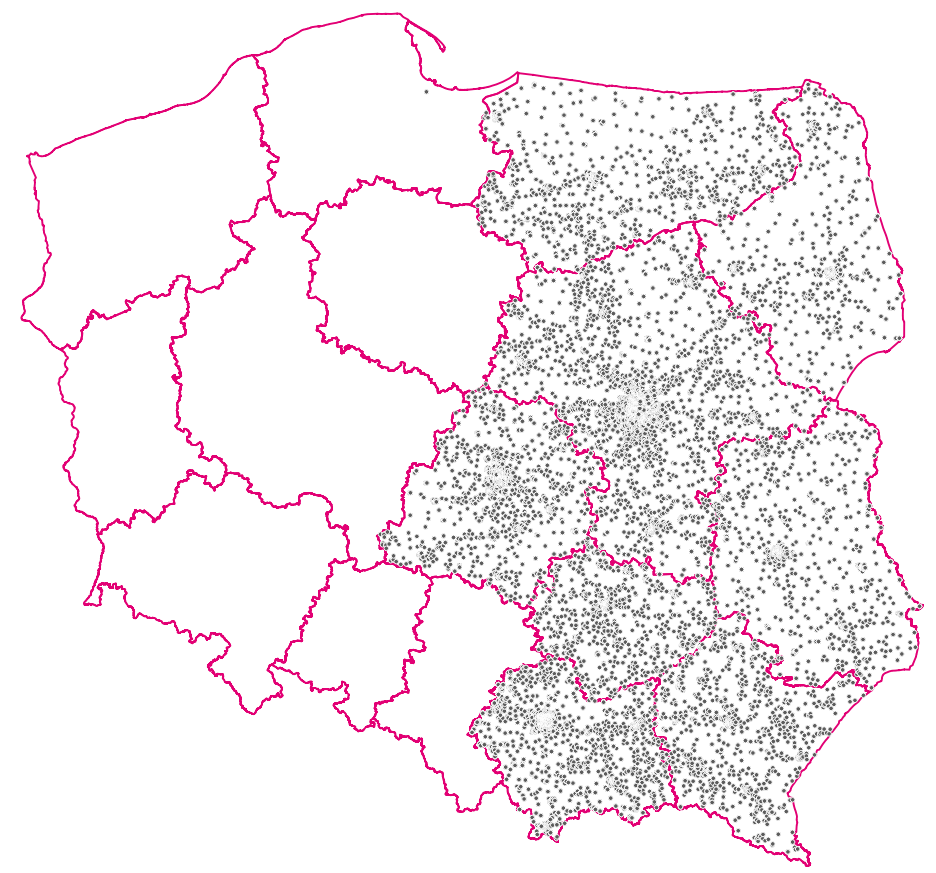
Uruchomienie monitoringu na terenie całego kraju spowodowało kolejne problemy:
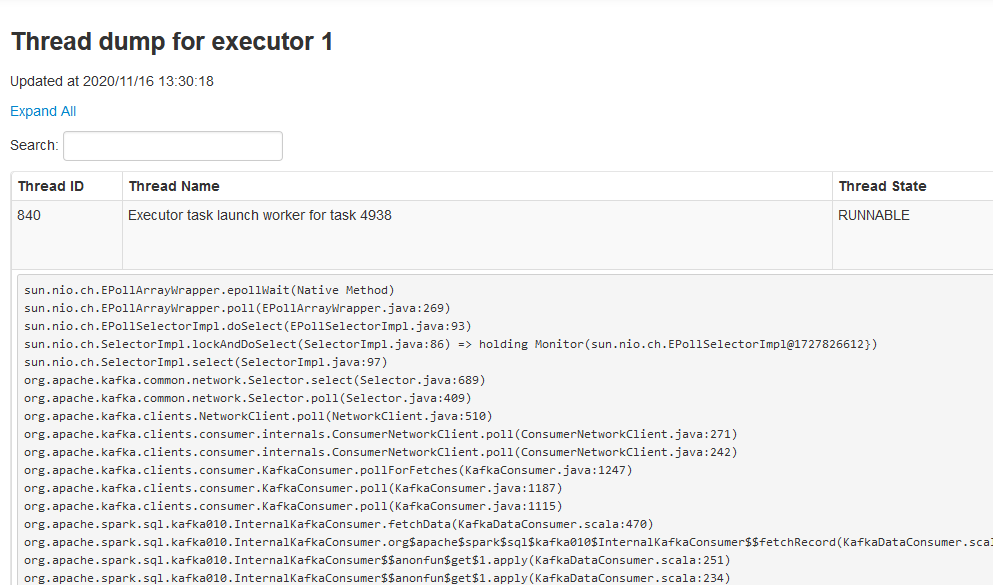
Jednak tym razem wspomniany parametr nie pomógł, zrzut pamięci wątku węzła wskazywał problem związany z kafka:
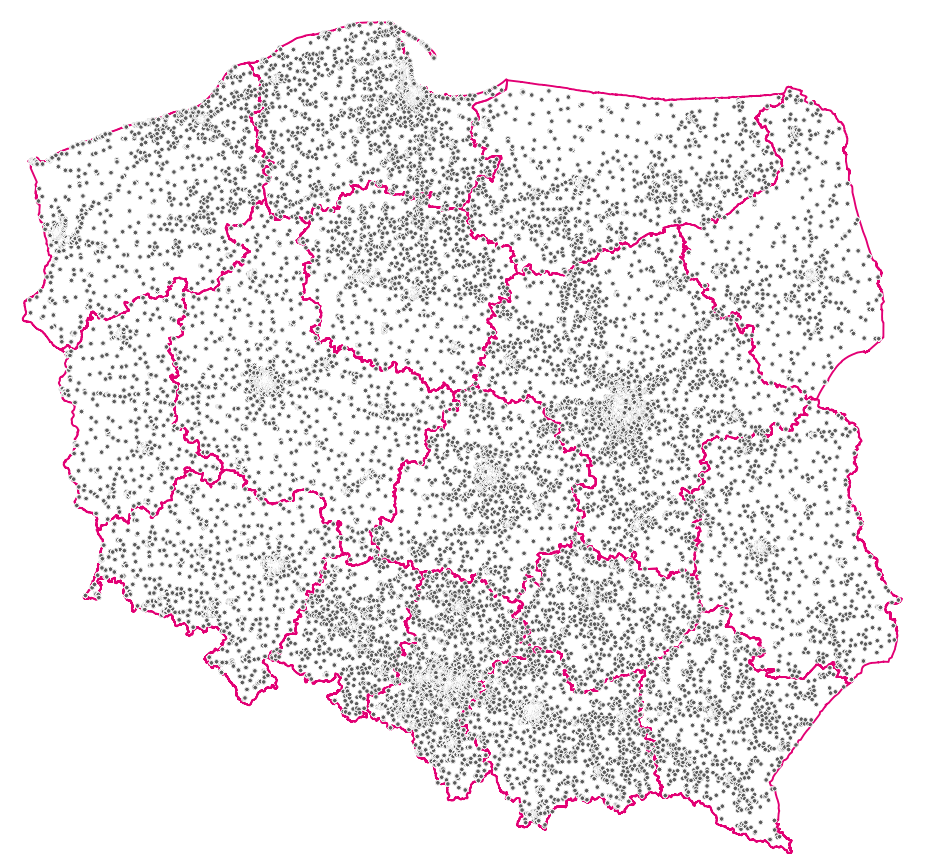
W istocie tak było, potwierdziło to wzbogacenie monitoringu o kolejną wizualizację:
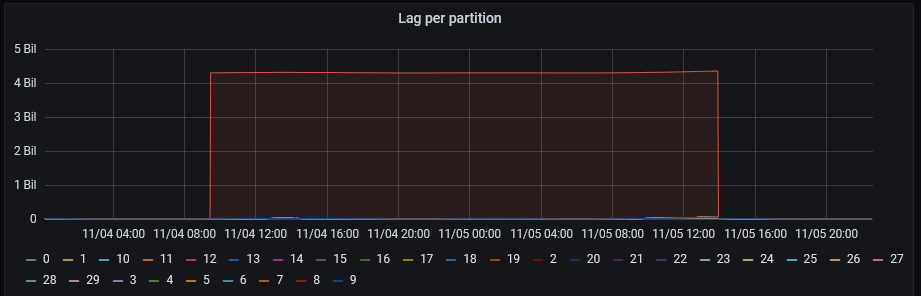
Wniosek był prosty — jedna partycja otrzymywała większość ruch, pomogło naprawienie wyznaczania klucza wiadomości.
W chwili pisania artykułu aplikacja zaliczyła szósty miesiąc bezawaryjnego działania, oby tak dalej!