Jak zaimplementować BDD za pomocą SpecFlow

BDD (ang. Behavior Driven Development) jest praktyką inżynierii oprogramowania nastawioną na bardzo bliską współpracę programistów, testerów oraz osób ściśle związanych z domeną naszej aplikacji (może być to zarówno bezpośredni klient, jak i ekspert z danego obszaru) w celu osiągnięcia jasno określony rezultatów - wspólnego porozumienia co do funkcjonalności dostarczanej aplikacji oraz oczekiwanego działania poszczególnych jej części.
Porozumienie, o którym mowa, powinno również zostać odzwierciedlone w postaci grupy automatycznych testów akceptacyjnych, które od tego momentu mają pełnić rolę tzw. Żyjącej Dokumentacji (ang. Living Documentation). Bardzo często do tworzenia testów akceptacyjnych stosuje się składnię zbliżoną do języka naturalnego oraz narzędzi, które są w stanie z takiego opisu wygenerować lub bezpośrednio uruchomić testy w oparciu o framework testowy w danej technologii.
Czym jest SpecFlow?
SpecFlow jest przykładem narzędzia dla platformy .NET (C#), które służy właśnie do definiowania i uruchamiania testów akceptacyjnych. Korzysta ze składni Gherkin w celu opisania kroków testu językiem naturalnym oraz wymaga zdefiniowania tych kroków już w postaci kodu w języku C#. Więcej o tym w kolejnych częściach artykułu.
Sami autorzy SpecFlow chwalą się, iż ich produkt jest najczęściej wybierany w środowisku .NET do implementacji BDD. Ma ponad 10 milionów pobrań z menedżera pakietów NuGet, co samo w sobie świadczy o dużym zainteresowaniu, a z dotychczasowego doświadczenia mogę szczerze przyznać, że im większe community, tym łatwiejsza współpraca z narzędziem :)
Pierwsze kroki
Skoro wiemy już, na czym polega BDD oraz jakie narzędzie wybrać, aby rozpocząć implementację tej praktyki w naszym .NET-owym projekcie, czas przejść do skonfigurowania swojego środowiska. Do pracy polecam używać Visual Studio ze względu na możliwość zainstalowania rozszerzenia SpecFlow for Visual Studio. Dzięki temu rozszerzeniu zyskujemy m.in. możliwość tworzenia projektów SpecFlow z szablonów, wsparcie dla składni Gherkin, przechodzenie pomiędzy krokami testów a ich definicjami oraz wiele innych ułatwień.
Na potrzeby tego artykułu założę, że rozwijamy sklep z książkami - oczywiście w ogromnym uproszczeniu, bo nie jest to naszym głównym tematem :) Rozpoczynamy więc od stworzenia solution dla naszego projektu:
Następnie dodajemy projekt SpecFlow przy użyciu szablonu:
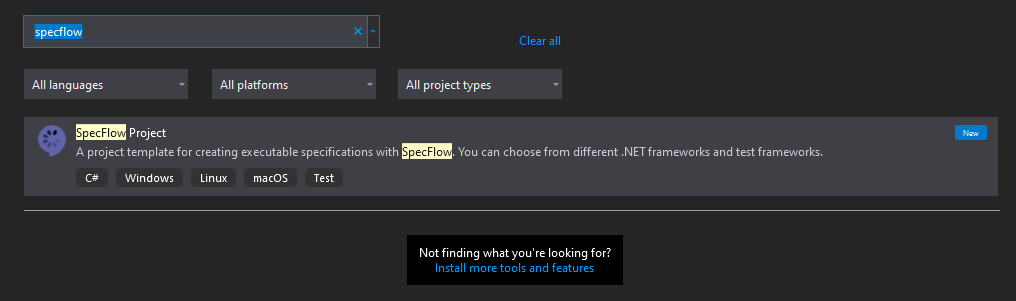
Podczas tworzenia należy wybrać odpowiednią wersję .NET oraz test framework, którego chcemy użyć (ja wybrałem .NET Core 3.1 oraz MSTest). Opcjonalnie możemy doinstalować bibliotekę FluentAssertions, która wprowadza bardziej intuicyjny zapis asercji w kodzie C#, ale aby nie poszerzać zakresu artykułu, nie będę z niej korzystał w kolejnych przykładach.
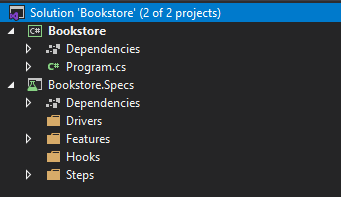
Ostatecznie powinniśmy zobaczyć strukturę podobną do tej:
SpecFlow w detalach
Struktura projektu
Szablon, którego użyliśmy do stworzenia projektu, zawiera przykładowe pliki, które pomagają zapoznać się z podstawową strukturą testów opartych na SpecFlow. I tak w katalogu Features mamy plik Calculator.feature, który zawiera opis testu przy użyciu Gherkina. Z tego pliku automatycznie generuje się plik Calculator.feature.cs, natomiast definicje poszczególnych kroków w pliku feature znajdują się w folderze Steps w pliku CalculatorStepDefinitions.cs.
Dla bardziej dociekliwych, folder Drivers służy do przechowywania klas, których powinniśmy używać jako dodatkowej warstwy pomiędzy kodem kroku a kodem aplikacji. Pozwala to zwiększyć czytelność definicji samego kroku, rozdzielenia odpowiedzialności oraz możliwemu ponownemu użyciu kawałków kodu. Folder Hooks natomiast powinien zawierać definicję wszelkich dodatkowych akcji, które chcemy wykonać np. na początku każdego testu lub by posprzątać po specyficznym teście.
Warto dodać, że SpecFlow posiada także szablony plików, dzięki którym łatwiej jest rozszerzać istniejący projekt i (przynajmniej dla podstawowych przypadków) nie zaprzątać sobie głowy tym, od czego musi się zacząć dany plik, jakimi atrybutami powinniśmy opatrzyć klasę lub metodę itp.
Jak opisać nasze testy
Przejdźmy teraz do analizy pliku Calculator.feature. Na samej górze znajduje się nazwa feature'a, który chcemy testować w danym pliku - odpowiednik suity testowej. Zaraz pod nim znajduje się krótki opis danego feature'a. W przypadku używania szablonu jest on od razu przygotowany do generacji dokumentacji, lecz wcale nie musimy z tego korzystać. Pozostawiam ten temat otwarty dla zainteresowanych (link).
Poniżej opisu znajdziemy natomiast słówko kluczowe Scenario, które zawiera definicję pojedynczego testu. Każdy taki test, przez konwencję znaną powszechnie w testowaniu, powinien zawierać trzy fazy - arrange (kroki zaczynające się od słówka Given), act (słówko When) i assert (słówko Then). Możemy również używać słówek And lub But zamiennie z ostatnio użytym słówkiem kluczowym - poprawia to nieco czytelność całego testu w języku naturalnym.
Dalsza część linijki jest już zarówno opisem kroku, jak i identyfikatorem, po którym SpecFlow będzie starał się znaleźć definicję opisaną w języku C#.
Definicje kroków
Przykładem takiej definicji jest następujący kod:
[Given("the first number is (.*)")]
public void GivenTheFirstNumberIs(int number)
{
...
}
Odpowiada jej natomiast krok, który może wyglądać następująco: Given the first number is 50. Jak można zauważyć, metoda z definicją jest opatrzona odpowiednim atrybutem, który przyjmuje string w formie wyrażenia regularnego. String ten będzie służył do wspomnianej wcześniej identyfikacji kroków z plików feature. Sama nazwa funkcji jest dowolna, natomiast ilość parametrów powinna odpowiadać ilości przechwytujących grup (ang. capturing groups) w wyrażeniu regularnym (poza drobnymi wyjątkami, o których będzie mowa za chwilę).
Warto zwrócić uwagę, że typ tych parametrów niekonieczne musi być stringiem, gdyż SpecFlow automatycznie dba o konwersję standardowych typów - widać to na naszym przykładzie. Jeżeli w waszym przypadku byłoby to niewystarczające, to dla bardziej skomplikowanych typów można definiować własne konwertery.
Wielolinijkowe stringi
Przy okazji parametrów warto wspomnieć o dwóch specyficznych przypadkach. Pierwszym z nich jest przekazanie do definicji wielolinijkowego stringa (zwanego również Doc String). Służy do tego składnia trzech cudzysłowów. Przypuśćmy, że w naszej docelowej aplikacji (sklep z książkami) chcemy przetestować moduł związany z ocenami i komentarzami książek, a jeden z kroków wygląda następująco:
Given the user 'Mark' rated the book 'SpecFlow for dummies' 5 stars with comment:
"""
Very interesting!
I recommend this reading :)
"""
Definicja tego kroku mogłaby wtedy wyglądać tak:
[Given(@"the user '(.*)' rated the book '(.*)' (.*) stars with comment:")]
public void GivenTheUserRatedTheBookStarsWithComment(string user, string bookName, int stars, string comment)
{
...
}
Nie ma potrzeby dodawania w atrybucie żadnych grup dla samego Doc Stringa, gdyż SpecFlow automatycznie przekazuje go jako ostatni parametr do funkcji.
Co warto wiedzieć, to że SpecFlow podczas tworzenia stringa, usuwa z początku każdej linii tyle białych znaków, ile znajduje się przed otwierającymi Doc String """. Oznacza to, że jeśli chcielibyśmy, aby obie linijki w docelowym obiekcie string miały na początku po dwie spacje, musielibyśmy zapisać to w następujący sposób:
"""
Very interesting!
I recommend this reading :)
"""
Tabele
Kolejnym specyficznym parametrem, którego możemy użyć, jest tabela. Będzie pomocna w przypadku definiowania listy obiektów o zbliżonej strukturze, np. aby zainicjalizować spis książek dostępnych w sklepie:
| Name | Price |
| SpecFlow for dummies | 23.99 |
| All about cats and the universe | 17.95 |
Odpowiednikiem tego kroku jest następująca definicja:
[Given(@"our store has following books for sale:")]
public void GivenOurStoreHasFollowingBooksForSale(Table table)
{
...
}
Podobnie jak dla Doc String, tabela jest przekazana jako ostatni parametr funkcji. Jeśli chcesz mieć większą kontrolę nad kodem, możesz użyć właściwości (ang. property) Rows, aby samemu odpowiednio przetworzyć przekazany do definicji obiekt Table.
Pracując z tabelami, warto jednak znać dwie generyczne metody rozszerzające CreateInstance<T> oraz CreateSet<T>. Pierwsza z nich może się przydać, gdy nasza tabela służy do opisania wyłącznie jednego obiektu, tzn. tytuły kolumn to nazwy pól obiektu, a kolejny wiersz zawiera ich wartości (działa również dla tabel zbudowanych wertykalnie, należy wtedy jednak pamiętać, że pierwszy wiersz zawiera nazwy kolumn, które nie będą używane do tworzenia obiektu).
W naszym przykładzie wolelibyśmy natomiast użyć metody CreateSet, dzięki której otrzymamy kolekcję obiektów:
IEnumerable<Book> books = table.CreateSet<Book>();
Wspólne części scenariuszy
W kontekście omawiania kroku służącego do inicjalizacji warto również wspomnieć o możliwości zdefiniowania w plikach feature zbioru kroków, które będą wykonywane przed każdym scenariuszem z danego pliku. Służy do tego blok Background:
Background: Books and Users database initialization
Given our store has following books for sale:
| Name | Price |
| SpecFlow for dummies | 23.99 |
| All about cats and the universe | 17.95 |
And 'Mark' is a registered user
Scenario: When user selects book then it appears in the cart
...
Scenario: When user has discount code then total cart price is updated
...
Dzięki temu oba scenariusze na samym początku zainicjalizują potrzebne informacje, co wyeliminuje duplikację kodu pomiędzy nimi oraz zwiększy też czytelność samego scenariusza poprzez wydzielenie potrzebnych, aczkolwiek nie bezpośrednio związanych z testowaną funkcjonalnością kroków do osobnego bloku.
Jak zapanować nad rosnącą ilością definicji
Dotychczas skupiliśmy się na jednym pliku feature związanym z zamówieniami książek. Jednakże w prawdziwych projektach ilość takich plików (jak i funkcji, które testujemy) jest znacząco większa. Aby móc zapanować nad wielkościami plików i ilością definicji kroków, bardzo często grupuje się je po obszarze aplikacji, którego dotyczą i wydziela do osobnych plików.
W zależności od przypadku możemy albo użyć modyfikatora partial, albo tworzyć osobne klasy z definicjami. W przypadku drugiej opcji należy wiedzieć, że każda klasa musi być opatrzona atrybutem Binding, aby SpecFlow wiedział, gdzie może znaleźć definicje kroku z pliku feature. Domyślnie przeszukuje on wszystkie klasy opatrzone tym atrybutem, jednak można nieco wpływać na ten mechanizm poprzez korzystanie z dodatkowego atrybutu Scope. Przy użyciu jego właściwości (ang. property) Feature, Scenario oraz Tag można precyzyjnie określić, w jakim przypadku dana klasa lub metoda powinny być użyte przez SpecFlow:
[Binding]
[Scope(Feature = "Bookstore.Orders")]
public sealed class BookstoreOrdersStepsDefinitions
{
...
}
W swojej dokumentacji autorzy zwracają jednak uwagę, aby korzystać ze scope’ów ostrożnie. Głównie dlatego, że można tym doprowadzić do problemów z definicjami kroków, które pomimo uniwersalnej implementacji będą niemożliwe do ponownego użycia w innym featurze czy scenariuszu. Także używajcie rozważnie :)
Podsumowanie
Omówione przeze mnie przykłady nie wyczerpują wszystkich możliwości, które dostarcza SpecFlow, lecz są wystarczające, aby zacząć pracę z tym narzędziem i na bieżąco poznawać użyteczne funkcjonalności.
W zakończeniu chciałbym jeszcze raz zaznaczyć, że SpecFlow sam w sobie nie jest równoznaczny z używaniem BDD w projekcie. Głównym założeniem jest kolaboracja osób zainteresowanych przy tworzeniu aplikacji.
Pokrótce chciałem również podsumować, jakie korzyści płyną z implementacji praktyki BDD w codziennej pracy:
- Wspomniana przed chwilą kolaboracja z klientem oraz możliwość zaangażowania go w proces tworzenia testów (od strony plików feature)
- Specyfikacja opisana językiem naturalnym - łatwa do zrozumienia i dla deweloperów, i dla osób mniej związanych z programowaniem
- Living Documentation- ciągle uruchamiane testy dbają zarówno o poprawność jak i aktualność tej dokumentacji
- Testy skupione na weryfikacji poprawnego działania funkcjonalności z perspektywy klientów
Mam nadzieję, że to krótkie wprowadzenie do zagadnienia BDD oraz narzędzia SpecFlow zachęcą Cię do zastosowania ich w swoich projektach. Przekonajcie się, czy sprawdzą się równie dobrze jak w tych, w których pracowałem dotychczas!