Implementacja mikrofrontendu – zalety i wady

Wszyscy chcą implementować mikroserwisy. Czy warto interesować się tym podejściem przy pracy na frontendzie? Sprawdźmy.
Na temat mikroserwisów na backendzie powstało wiele artykułów. Po początkowym zachłyśnięciu się tematem (wszyscy stosujmy mikroserwisy – są taaakie piękne) zauważono, że nadają się one do określonych problemów - jak każde narzędzie. Podobnie jest na frontendzie, przy czym tutaj trzeba być jeszcze bardziej ostrożnym. W przeciwieństwie do backendu nie zawsze możemy sobie pozwolić na pełną dowolność w wyborze zależności (jak np. technologia), gdyż ostatecznie użytkownik aplikacji będzie musiał cały ten kod pobrać (w przypadku backendu serwer jedynie otrzyma request i zwróci odpowiedź – zazwyczaj nie ma aż takiego znaczenia ilość wybranych bibliotek do rozwiązania biznesowego problemu).
Raj, w którym stosowane są jedynie mikrofrontendy – NIE ISTNIEJE.
Mikrofrontendy czerpią inspirację z mikroserwisów obecnych po stronie backendu. Będę starał skupić się głównie na problemach występujących na frontendzie, jednak część z nich jest wspólna dla obu tematów.
Czym u nas będzie mikrofrontend? Określmy go jako fragment aplikacji, który może w dużej mierze działać niezależnie. Jeżeli mówimy o pełnej niezależności, to wtedy nic nie stoi na przeszkodzie, aby zrealizować to jako osobną aplikację – w końcu, po co komplikować sobie życie?
Droga do mikrofrontendu
Analogicznie jak w przypadku mikroserwisów warto zacząć od tworzenia modularnego monolitu. Jedno repozytorium, być może jeden projekt (jeden stos technologiczny). Proste zarządzanie, wdrożenie, wszystko w jednym miejscu, łatwe ponowne użycie kodu. Jedyne, o czym warto pamiętać przy projekcie, który będzie dłużej rozwijany, to by starać się grupować funkcjonalności i wytyczać granice między nimi.
Na tym etapie błąd niewiele kosztuje – łatwo przenieść folder z jednej lokalizacji do drugiej i poprawić importy. Później będzie o wiele prościej wydzielić w razie potrzeby osobny moduł. Tutaj przykład, jak organizować pliki (grupowanie po funkcjonalnościach) zrealizowany w React.
Projekt jednak się rozrasta, dochodzą nowe osoby i zespoły. Jeżeli ich praca jest organizowana niezależnie od siebie, to w pewnym momencie kod tworzony przez nich także stanie się niezależny (Conway's law).
Teraz możemy się natknąć na takie problemy:
- osoba z zespołu A wprowadza funkcjonalność, która zahacza o obszar rozwijany przez zespół B bez ich wiedzy, w związku z czym nie obsługuje przypadku, którego nie była świadoma =>chcemy, aby każdy obszar miał odpowiedzialny za niego zespół z największą wiedzą (podział odpowiedzialności),
- z powodu niedostarczenia funkcjonalności przez zespół B cały projekt musi czekać z wdrożeniem=> chcemy móc niezależnie wdrażać fragmenty aplikacji („moduły”),
- aktualizacja zależności (bibliotek) jest zbyt czasochłonna w jednym dużym projekcie (poprawki w kodzie, testowanie całego projektu, zmergowanie ogromnej ilości zmian ze względu na konflikty),
- rozwiązanie, które stanowi fundament projektu (np. użyta biblioteka lub framework) nie sprawdza się (np. ludzie popełniają w nim wiele błędów)=> chcemy przetestować alternatywne rozwiązanie. Zamiast przepisywania (na co może nie być czasu) lub tworzenia proof of concept na boku (znowu czas), wolimy rozwiązać mały biznesowy problem z użyciem innego narzędzia (testowanie w boju),
- problemy z rekrutacją nowych pracowników z powodu użytego mało interesującej technologii=> zastosowane rozwiązanie może być takie samo jak w punkcie wyżej.
Wydzielamy osobny projekt – generujemy nowe problemy?
Jednym z rozwiązań powyższych problemów może być wydzielenie fragmentu kodu, np. do osobnego repozytorium. W zależności, jaki problem chcemy rozwiązać, może wystarczyć osobny folder i pozostanie przy „monorepo”.
Co może pójść nie tak? Jak zwykle – to zależy od naszego projektu. Jeżeli wydzieliliśmy całkowicie niezależny fragment, który może być samodzielną aplikacją, to możemy otwierać szampana.
W dużych, kompleksowych rozwiązaniach jednak nie jest tak różowo. Po pierwsze, wydzielenie od razu całego modułu może być bardzo ciężkie. Nawet jeżeli staraliśmy się tworzyć „modularny monolit” w ramach jednej aplikacji, to zazwyczaj tworzą się zależności między wewnętrznymi modułami. Wydzielenie osobnego projektu nie będzie opierało się na prostym wytnij i wklej w nowej lokalizacji.
Często obieraną drogą jest praca iteracyjna: stworzenie repozytorium, przeniesienie małej rzeczy (albo stworzenie nowej) i integracja ze starym rozwiązaniem. Jakie przeciwności możemy napotkać?
- W zależności, jakie problemy rozwiązujemy (np. zmieniamy technologię), sama integracja może być problematyczna. Potencjalne rozwiązania omówię później.
- Współdzielenie funkcjonalności, które powtarzają się w wielu modułach. Nie mam tu na myśli wydzielenie biblioteki komponentów, które będą używane w projekcie, a raczej powtarzalne „cross-cutting concerns”, np. uwierzytelnianie, które w każdym module powinno być zrealizowane w ten sam sposób, czy menu nawigacyjne, które również powinno być jedno dla całej aplikacji.
Oba problemy można rozwiązać za pomocą wydzielenia nowej biblioteki (lub komponentu), ale w przypadku zmiany w jego interfejsie, każdy moduł musi się dostosować (a chcielibyśmy tego uniknąć). Z początku nie natkniemy się na ten problem (w końcu wydzielamy na razie tylko fragment istniejącej aplikacji), ale nadejdzie moment, gdy będziemy tworzyli nowy moduł i nie będziemy chcieli go ładować do starej aplikacji, gdyż użytkownik nie potrzebuje elementów tam się znajdujących.
Jak posklejać stare z nowym?
Nawiązując do ostatniego problemu, mamy dwie drogi działania:
- Wydzielamy fragment (moduł), który jest ładowany do starej aplikacji. Wszelkie cross-cutting concerns mogą pozostać w starej aplikacji. Minusem może być to, że aby użyć nowej/przeniesionej funkcjonalności, użytkownik musi to zrobić przez stary moduł – pytanie, czy potrzebuje tego wszystkiego?
- Możemy wprowadzić nowy byt, który będzie decydował, czy wyświetlić stary, czy nowy element. „Kontener” do ładowania i zarządzania obiema aplikacjami. Oprócz definicji routingu mogą tam być współdzielone między zespołami elementy – jedno i to samo menu nawigacyjne, uwierzytelnianie, logowanie, strony z błędami (np. 403, 404). Możemy nawet pokusić się o stworzenie (w razie potrzeby) szyny do komunikacji między modułami w kontenerze. Jednak im bardziej autonomiczne będą fragmenty, tym zazwyczaj lepiej.
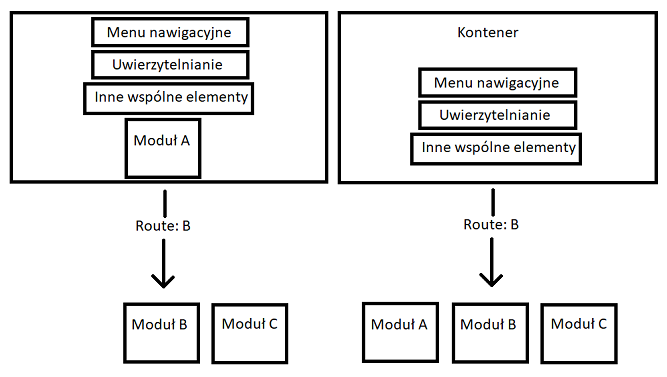
Ładowanie do starej aplikacji vs ładowanie do kontenera.
Ładowanie modułów
Tak naprawdę, niezależnie od wybranego rozwiązania (wersja z kontenerem lub bez). Musimy jakoś zrealizować ładowanie wydzielonego kodu. Co możemy zrobić?
<iframe />
Plusy
+ możemy załadować dowolną stronę
+ najłatwiejsze pierwsze użycie – podajemy tylko URL, z którego ładujemy stronę
+ pełna izolacja modułów
Style z załadowanego modułu nie wpłyną na kontener ani na inny moduł. Możemy załadować dwa moduły z tym samym frameworkiem w różnych wersjach, nawet jeżeli wpływają na globalny namespace (np. Ember, Blazor).

Minusy
- izolacja może spowodować problemy, gdy będziemy chcieli zapewnić komunikację pomiędzy modułami
Mamy jedynie postMessage do komunikacji.
Zarządzanie routingiem z poziomu modułu (on też może zawierać swoje route’y). Jeżeli już wydzielamy jakąś domenę, to naturalne wydaje się, aby tam się znajdowała definicja route’ów odpowiadających temu fragmentowi aplikacji (w końcu to zespół, który go rozwija, wie czego potrzebuje). Dla przykładu: kontener będzie miał jedynie definicję, że route’y zaczynające się od /route-A należą do modułu A. Z kolei moduł A już u siebie będzie definiował /route-A/subroute-1, /route-A/subroute-2, itd. Wewnątrz iframe’a nie mamy zbytnio opcji odczytywania (ani modyfikowania) URL strony. Pozostaje postMessage albo komunikacja przez parametry w URL iframe’a (src atrybut). Ostatecznie i tak musimy zdefiniować wszystkie route’y w kontenerze i powiadamiać odpowiedni moduł o każdej zmianie URL-a.
- problemy z czytnikami ekranowymi
- każdy iframe ma osobny kontekst, w związku z czym wymaga trochę większych zasobów. Może się to stać problemem, gdy będziemy mieli wiele iframe’ów (co raczej nie jest typową sytuacją, ale warto być tego świadomym).
Ładowanie JS-ów
Plusy
+ możemy swobodniej komunikować się z modułami (mogą same zarządzać globalnym stanem, np. URL-em i reagować na jego zmiany),
+ mamy dostępne w modułach wszystkie mechanizmy osiągalne z poziomu JavaScriptu,
+ większa kontrola i elastyczność rozwiązania.
Minusy
- przy niewłaściwym podejściu możemy wpłynąć na kontener lub inny moduł (sporo zależy od zastosowanych rozwiązań) – globalne zmienne, style (to można rozwiązać poprzez css modules, styled components, czy nawet plugin, który doda prefix do naszych selectorów w CSS), globalne eventy, dostęp do window, itd. Są to jednak problemy, które normalnie mogłyby wystąpić. Przy mikrofrontendach może być trudniej zlokalizować ich źródło, czy przewidzieć globalny efekt,
- więcej pracy przy integracji i dbaniu o ty by moduły na siebie nie wpływały,
- problem przy ładowaniu w jednym momencie modułów korzystających z tego samego frameworka w różnych wersjach i modyfikującego globalny namespace.
Użycie elementów rozpoznawalnych przez przeglądarkę (web componenty)
Możemy to traktować jako podtyp poprzedniego rozwiązania. Moduł w tym wypadku będzie zamkniętym jednym komponentem. Warto tutaj jedynie wspomnieć o elemencie składającym się na web componenty: shadow DOM. Pozwala on w natywny sposób zapewnić enkapsulację poddrzewa DOM i ustrzec się przed przypadkową ingerencją z zewnątrz, szczególnie w kontekście template’u HTML i styli. Piszę „przypadkową”, bo dalej pozostaje możliwość modyfikacji - nawet, gdy ustawimy mode: closed przy tworzeniu shadow DOM.
Ładowanie JS-ów
Skupię się tutaj na drugim podejściu, gdyż iframe jest raczej dosyć oczywisty. Mamy głównie dwie opcje.
Zależność statyczna – definiowana w trakcie budowania
W tym rozwiązaniu kontener ma jawnie określone zależności na moduły, które pełnią rolę poniekąd bibliotek. Każdy moduł ma własny proces release’u, ale by jego najnowsze zmiany były widoczne, wymagana jest modyfikacja kontenera (aktualizacja zależności oraz jego release). Zostajemy wtedy przy wersji z centralnym sterowaniem odnośnie wdrożeń.
Plusem jest to, że możemy wykorzystać automatyczne mechanizmy do dzielenia kodu i wydzielania wspólnych zależności, jakie udostępniają narzędzia na frontendzie (code splitting). Tak przygotowany kod będzie prawdopodobnie mniejszy i bardziej zoptymalizowany, niż gdy każdy moduł będzie osobno budowany.
Oczywistym minusem wydaje się to, że wszystko jest najpierw budowane osobno, a później w całości – może dojść do nieprzewidzianych problemów, gdy coś działa w izolacji, ale już nie w integracji. Ilość potencjalnych problemów rośnie w miarę, gdy moduły się rozrastają i dodawane są nowe.
Dodatkowo problemem może być zastosowany framework – nie każdy będzie wspierał.
Integracji możemy dokonać za pomocą np. Webpacka.
Zależność dynamiczna – definiowana w trakcie uruchomienia
W tym podejściu nie mamy jawnie zdefiniowanej zależności. Moduły są hostowane tak, jakby były osobnymi aplikacjami. Główna aplikacja/kontener ładuje odpowiedni moduł poprzez pobranie odpowiednich plików (style, JS-y). Jedyne co powinno być zdefiniowane, to adresy, pod którymi moduły są dostępne. To wymaga jednej z dwóch rzeczy:
- pliki modułów, które muszą zostać pobrane, muszą mieć stałe i niezmienne nazwy(wtedy kontener ma zdefiniowaną konkretną ścieżkę do tych plików). Minusem przy JS-ach jest to, że przeglądarka będzie je cache’ować, więc użytkownik nie zobaczy zaktualizowanej wersji, tylko starą.
Możemy zapobiec cache’owanu (np. ustawiając odpowiedni header przy odpowiedzi zwracanej przez serwer lub dodając do query stringa w URLu losowy ciąg znaków), ale to z kolei spowoduje, że pliki będą za każdym razem od nowa pobierane. Alternatywnie możemy w trakcie deploymentu modułu aktualizować plik konfiguracyjny kontenera – wymaga to jednak procesu obejmującego więcej niż jedno repozytorium.
- każdy moduł będzie mieć 1 plik o niezmiennej nazwie z nazwami plików do pobrania. Może to być jakiś plik konfiguracyjny, który będzie aktualizowany z każdym releasem modułu. Wiele starterów do aplikacji webowych zawiera wstrzykiwania ścieżek plików do pliku
index.html(np. HtmlWebpackPlugin) – w najprostszym rozwiązaniu można właśnie go wykorzystać.
To, co zyskujemy w takim podejściu, to niezależne wdrożenia – nie musimy z każdym releasem modułu martwić się o aktualizację kontenera. Mamy kilka(naście) mniejszych procesów zamiast jednego dużego odpowiadającego za integrację.
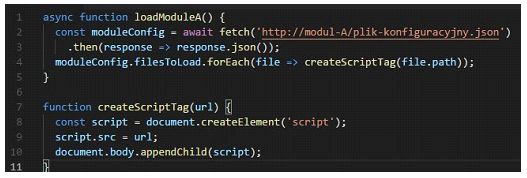 Przykładowa prosta implementacja ładowania skryptów z modułu
Przykładowa prosta implementacja ładowania skryptów z modułu
Potencjalne problemy
Użyte zależności w modułach
Jeżeli mamy ten sam zbiór bibliotek w każdym module, to możemy się pokusić o wydzielenie tych zależności do kontenera. W tym wypadku jednak wracamy do problemu, gdy wszystkie mikrofrontendy muszą w tym samym momencie aktualizować swoje zależności – tym razem do wersji narzucanej przez kontener. Praca jedynie jest podzielona na kilka zespołów.
Możemy zrezygnować z tego i pozwolić, aby każdy moduł dostarczał swój kod razem z zależnościami. Jeżeli skończymy z dużą ilością bardzo małych frontendów, to prawdopodobnie będziemy ładowali tą samą zależność kilka razy. Nie powinno to być problemem, ale mieć tego świadomość. Jeśli stanie się to problemem, możemy np. powydzielać zależności do osobnych plików, których nazwy będą zawierały numer wersji. Jeżeli pliki będą hostowane z tego samego miejsca (np. CDN), to będą cache’owane nawet między modułami.
Większym problemem przy ładowaniu plików może być ich wpływ na globalny namespace (np. dopisywanie właściwości do obiektu window). Będzie to szczególnie kłopotliwe, gdy załadujemy inny moduł, który polega na tej samej zależności, ale w innej wersji. Powinniśmy wtedy wcześniej usunąć takie zmiany.
 Przykład frameworka dopisującego własne zmienne
Przykład frameworka dopisującego własne zmienne
do window, co może sprawić problemy
Współdzielenie kodu
Zgodnie z zasadą DRY, nie chcemy duplikować kodu. Co możemy zrobić? Stworzyć nową bibliotekę. Bez problemu umieścimy tam wszelkie utilsy.
Co jednak z komponentami? Jeżeli wszędzie używamy tej samej technologii, to możemy je (szczególnie te prostsze, prezentacyjne) też tam umieścić (warto pamiętać, że development takiej biblioteki będzie opierał się na konkretnej wersji zależności, co może potencjalnie powodować problemy w niektórych modułach). W przeciwnym wypadku warto zastosować rozwiązanie, które jest transpilowane do czystego JS-a i rozpoznawane przez przeglądarkę, np. web componenty (jest dużo narzędzi wspomagających ich pisanie).
Alternatywnie wybrać coś, co jest biblioteką do tworzenia komponentów, a nie frameworkiem. Dobrym przykładem jest tutaj React – możemy tak przygotować naszego bundle’a, aby działał w dowolnym miejscu. Doprowadzi nas to jednak do sytuacji, gdy w jednym module będziemy mieli 2 technologie do tworzenia UI (modułowa + pochodząca z biblioteki). Sami musimy odpowiedzieć sobie na pytanie, czy jest to akceptowalne.
Co z komponentami biznesowymi, które przynależą do danego modułu i zespołu, ale są potrzebne w pozostałych częściach aplikacji? Możemy również wydzielić osobną bibliotekę dla każdego modułu specjalnie na jego biznesowe funkcjonalności, kierując się zasadami określonymi wyżej. Możemy wtedy mieć wersjonowanie biblioteki niezależne od modułu, który ją tworzy.
Inną opcją jest trzymanie komponentów w module, do którego należą i ładowanie ich w ten sam sposób, w jaki jest ładowany moduł do kontenera. Wystarczy mieć jedynie osobny punkt wejściowy do pobrania „startera modułu” (użyty w kontenerze do wystartowania fragmentu aplikacji) oraz osobny do pobrania „publicznych komponentów z modułu”. Plusem jest to, że komponenty są rozwijane tam, gdzie domenowo przynależą. Użycie w module „matce” jest również bardziej podobne do tego jak są używane w pozostałych modułach.
Ostatnia możliwość, to komunikacja przez kontener (bezpośrednia delegacja do niego lub rzucenie eventu) albo przez inny stworzony byt – nie tworzą się wtedy zależności bezpośrednio między modułami. Potrzebujemy wtedy jednak osobnego miejsca, które będzie zawierało mapowanie między żądaniem a modułem i komponentem do wyświetlenia. Nic też nie stoi na przeszkodzie, aby z czasem wprowadzić takie rozwiązanie.
Takie zależności między modułami nie są wskazane i warto ich unikać – po to wydzieliliśmy moduł, by był jak najbardziej niezależny. Komponent używany na zewnątrz modułu trudniej jest zmienić – musimy przede wszystkim dbać o to, by jego interfejs się nie zmieniał. Dlatego ważne jest, aby komponent był jak najbardziej niezależny – wszystko, co się go tyczy, powinno być w nim zamknięte (jak np. pobieranie danych). Wtedy api komponentu jest prostsze i maleje szansa na zepsucie zewnętrznych konsumentów przy zmianach.
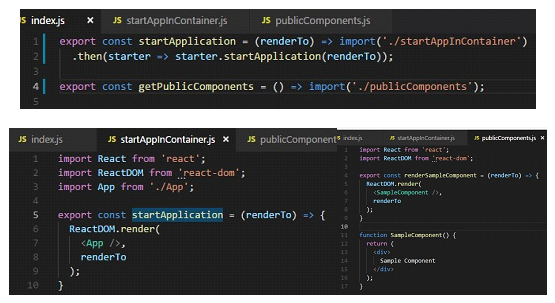 Przykład eksportowania startera modułu (używany przez kontener) oraz publicznych komponentów (używanych przez inne moduły)
Przykład eksportowania startera modułu (używany przez kontener) oraz publicznych komponentów (używanych przez inne moduły)
Alternatywną opcją do wyświetlenia komponentu może komunikacja omówiona poniżej (mniej jawna zależność).
Komunikacja między modułami
W pewnym momencie może nastąpić potrzeba skomunikowania poszczególnych modułów ze sobą lub z kontenerem. Warto ponownie podkreślić (podobnie jak przy współdzieleniu kodu), aby unikać komunikacji międzymodułowej i tworzenia zależności w miarę możliwości.
Jeżeli jednak potrzebujemy wprowadzić taką komunikację, to mamy kilka opcji.
Sterowanie poprzez URL
Daje to nam niejawną zależność, a jedynym kontraktem są wtedy URL-e, do jakich moduły mogą nawigować. Moduł A chce wyświetlić stronę z produktami, więc przekierowuje do subroute’a /products. Kontener z kolei wie, że ten subroute należy do modułu B, wyświetla go i sterowanie przejmuje moduł B (wyświetla odpowiedni komponent).
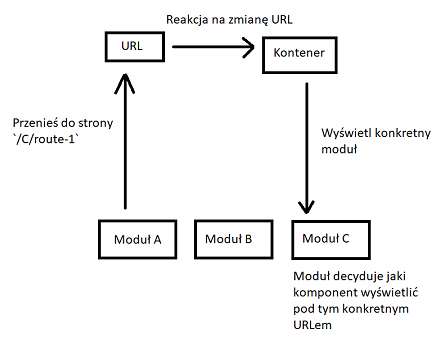
W większości przypadków lepiej wprowadzać luźną zależność poprzez niejawną komunikację.
Rzucanie eventami (CustomEvent)
Przy tym rozwiązaniu mamy również luźne powiązanie między modułami. Problem może wystąpić wtedy, gdy w kontrakcie coś się zmieni, a konsumenci/producent się nie dostosują – przez pewien czas może nikt nie zauważyć problemu.
Można też pokusić się o własne rozwiązanie – stworzyć szynę komunikacyjną i przypiąć ją do globalnego obiektu (window), aby była wszędzie dostępna, albo przekazać do modułów podczas ich ładowania.
Gdybyśmy potrzebowali jawnej komunikacji, to pozostaje jeszcze opcja przekazania callbacków do modułu (lub udostępnienia ich również w globalnym obiekcie). Warto to jednak zostawić na elementy niezbędne z perspektywy funkcjonowania mikrofrontendu.
Co nam dało zastosowanie mikrofrontendów?
- każdy fragment może mieć dedykowany zespół, który będzie za niego odpowiedzialny - można ustalić zasadę, że kod nie zostanie zmerge’owany, póki nie zobaczy go osoba z zespołu odpowiedzialnego za dany moduł,
- łatwiej zarządza się takimi modułami – wiadomo, komu można przydzielić zadanie. Istotne, aby zespoły były dzielone „pionowo” (czyli potrafiły dostarczyć kompletną funkcjonalność w ramach modułu), a nie „poziomo” (na podstawie warstw aplikacji lub technicznych rozwiązań, czyli np. osobny zespół do zarządzania stylami, do komponentów, do logiki biznesowej itd.) – zmniejszymy wtedy ilość blokerów (potencjalne, jakie mogą się pojawić, to przy funkcjonalnościach obejmujących więcej niż 1 moduł),
- łatwiejsze wdrożenia – można wdrażać każdy moduł niezależnie,
- mniejszy próg wejścia do pojedynczego modułu – nowa osoba nie musi od razu ogarniać całości, a jedynie mniejszy wycinek (nie będzie czuła się aż tak przytłoczona),
- łatwiejsza aktualizacja zależności w mniejszym module – nie musimy od razu dostosowywać ogromnego systemu, szczególnie gdy są niekompatybilne wsteczne zmiany,
- możliwość użycia różnych bibliotek w różnych modułach,
- jako efekt uboczny możemy osiągnąć krótszy czas ładowania pierwszego fragmentu kodu. Nie powinniśmy tego jednak traktować jako argumentu „za”, gdyż możemy to osiągnąć bez wprowadzania mikrofrontendów (np. w webpacku z użyciem dynamic importów lub jawnie określając punkty wejściowe).
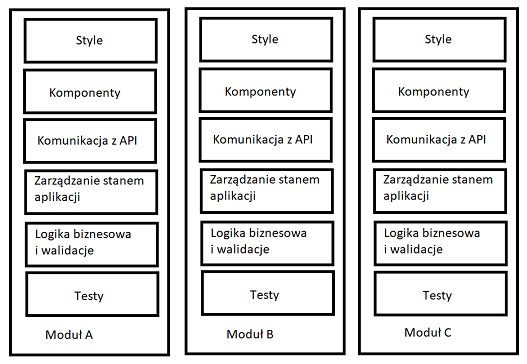 Dzieląc moduły i zespoły „pionowo”, osiągamy ich niezależność – mogą dostarczyć kompletną funkcjonalność bez polegania na innych.
Dzieląc moduły i zespoły „pionowo”, osiągamy ich niezależność – mogą dostarczyć kompletną funkcjonalność bez polegania na innych.
Jakie są minusy zastosowanie mikrofrontendów?
- zwiększony stopień skomplikowania całego produktu. Musieliśmy wprowadzić mechanizm ładowania poszczególnych modułów,
- nawigacja po kodzie mikrofrontendów jako całości może być utrudniona – jednak przy dobrze wydzielonych modułach nie powinno być to częste,
- przy niewłaściwie zaprojektowanych granicach systemu, może wytworzyć się siatka zależności pomiędzy frontendami – zamiast posiadać „spaghetti” kod w monolicie, możemy skończyć ze „spaghetti” podzielonym na mniejsze porcje (co będzie szczególnie niebezpieczne, gdy to „spaghetti” będzie wykraczało poza moduł),
- przeniesienie funkcjonalności z jednego modułu do drugiego będzie bardziej skomplikowane niż ta sama operacja wykonana w jednym projekcie,
- dłuższy czas ładowania biznesowych funkcjonalności z innego modułu. Z drugiej strony czas oczekiwania na pierwsze załadowanie będzie krótszy. Nic też nie stoi na przeszkodzie, by takie funkcjonalności w razie potrzeby wyciągać do osobnych bibliotek dedykowanych mikrofrontendom,
- większy końcowy rozmiar całego kodu, szczególnie gdy nie wynosimy wspólnych zależności. Ich wyniesienie przywróci problem z cięższą ich aktualizacją (będzie to wymagało dostosowania całego systemu),
- większa ilość projektów do zarządzania – trzeba zarządzać systemem jako całością, synchronizować pracę zespołów, czasami jeden zespół może być blokerem dla drugiego. Finalnie powinno to być prostsze niż organizacja pracy wielu grup w jednym dużym repozytorium.
- problem w momencie, gdy moduły korzystają z tych samych zależności, które wpływają na globalny namespace – przy zmianie modułu, trzeba przywrócić poprzedni stan.
 Posiadanie wielu mniejszych „mikro spaghetti” frontendów z masą zależności między sobą nie będzie lepsze od jednego dużego „mono spaghetti”.
Posiadanie wielu mniejszych „mikro spaghetti” frontendów z masą zależności między sobą nie będzie lepsze od jednego dużego „mono spaghetti”.
Podsumowanie
Na sam koniec podkreślę jedną rzecz: warto pamiętać, że mikrofrontendy to kolejne narzędzie, które może ułatwić nam pracę. Podobnie jak przy mikroserwisach warto jednak uważać, aby nie stosować ich w każdym projekcie, gdyż oprócz rozwiązań mogą także przysporzyć nowych problemów – warto postawić na szali wszystkie „za” i „przeciw” w kontekście tworzonego produktu i dopiero wtedy podjąć decyzję o ich zastosowaniu.