

Connectis_Connectis_
CQRS i Event Sourcing - czyli łatwa droga do skalowalności naszych systemów_
Odkryj, jak CQRS i Event Sourcing stają się kluczowymi elementami w rozwijaniu skalowalnych systemów IT, zmieniając podejście do projektowania.
Command Query Responsibility Segregation (CQRS) oraz Event Sourcing to ostatnimi czasy „buzz words” w branży IT. Oprócz niepodważalnych zalet płynących ze stosowania tych dwóch rozwiązań w społeczności pokutuje stwierdzenie, że sam koncept jak i implementacja są niemalże trywialne.
Czy aby na pewno? W dzisiejszym artykule postaramy się wspólnie dowiedzieć, czym oba te podejścia są, jakie korzyści płyną z ich stosowania oraz jak możemy dzięki nim zaprojektować nasz system.
CQS - Command Query Separation_
Zanim przejdziemy do bohatera pierwszoplanowego (CQRS), warto zapoznać się z konceptem, z którego bezpośrednio się on wywodzi. Mowa o CQS, czyli Command Query Separation. Został on przedstawiony w roku 1986 przez Bertranda Meyera. Widać więc wyraźnie, że wbrew powszechnemu stwierdzeniu nie jest to nic nowego. Czym zatem jest CQS? Jest to zasada, która mówi, że każda metoda w systemie powinna być zaklasyfikowana do jednej z dwóch grup:
- Command - są to metody, które zmieniają stan aplikacji i nic nie zwracają.
- Query - są to metody, które coś zwracają, ale nie zmieniają stanu aplikacji.
Bardzo spodobało mi się zdanie, które dobrze tłumaczy tę ideę:
„Pytanie nie powinno zmieniać odpowiedzi.”
Może wydawać się to dość oczywiste, jednak z mojego doświadczenia wiem, że programiści nie zawsze się do tego stosują. Bardzo prostym przykładem są metody, które wyglądają następująco:

Widać tu mały problem. Metoda GetOrCreateItem nie zawsze będzie się zachowywać identycznie. Poza tym mieszamy kod logiki biznesowej aplikacji z "głupim" pobraniem obiektu z bazy danych. Niesie to za sobą pewne problemy, o których wspomnę nieco później. Jak zapewne się domyślacie stosując CQS nasz kod w takim przypadku wyglądał by następująco:
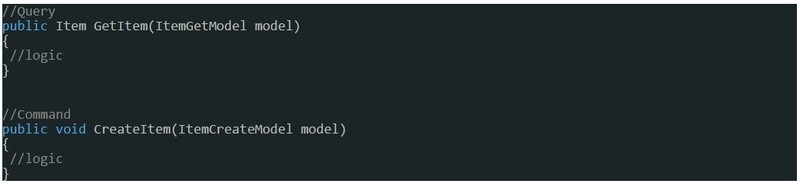
CQRS - Command Query Responsibility Segregation
Blisko 20 lat po "narodzinach" CQS, dwie wielkie osobistości tj. Greg Young oraz Udi Dahan przedstawili światu jego następce czyli CQRS - Command Query Responsibility Segregation. Pomysł był bardzo prosty. Dlaczego dokonujemy podziału jedynie metod na te, które pobierają dane oraz na te, które zmieniają stan naszej aplikacji? Możemy przecież zaprojektować nasz system tak, aby tymi zadaniami zajmowały się osobne klasy. To jest główna różnica między dwoma podejściami.
„Mówiąc o CQS myślimy o metodach. Mówiąc o CQRS myślimy o obiektach.”
W tym miejscu należy dodać, że nie ma jednej drogi do zaimplementowania CQRS, ponieważ tak jak w przypadku każdego wzorca projektowego podejść jest kilka. Zaraz, zaraz! Wzorca? Tak, wbrew wielu opinii, które możecie znaleźć w internecie CQRS nie jest architekturą aplikacji. To od nas zależy czy zostanie on wprowadzony "globalnie", czy jedynie w niewielkim jej fragmencie. Potwierdził to sam Greg Young:
„CQRS and Event Sourcing are not architectural styles. Service Oriented Architecture, Event Driven Architecture are examples of architectural styles.”
Dobrze, przejdźmy więc do graficznej reprezentacji ów wzorca, która powinna pomóc nam zrozumieć z czym, tak na prawdę, mamy do czynienia:
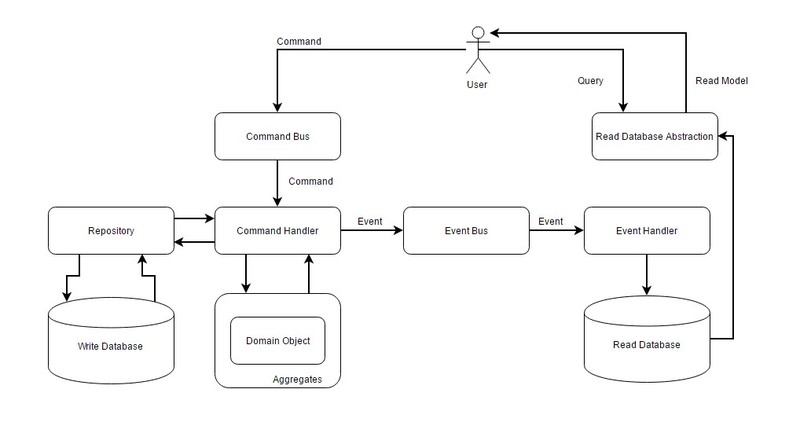
Tak jak wspomniałem, jest to jedna z możliwych implementacji. Na schemacie widzimy wiele składowych, dlatego przejdźmy do omówienia ich po kolei:
- Command - jest to obiekt, który reprezentuje intencje użytkownika systemu. Przykładowo możemy stworzyć obiekt UpdateItemQuantityCommand z polami Id oraz Quantity.
- Command Bus - ma dwa zadania. Po pierwsze zapewnia kolejkowanie wszystkich wchodzących do systemu komend. Po drugie, odszukuje odpowiedni dla danej komendy Command Handler i wywołuje na nim metodę Handle.
- Command Handler - jego zadaniem jest najpierw walidacja komendy. Następnie tworzy on lub zmienia stan obiektu domenowego. Ostatnim etapem jest zapisanie zmian do bazy danych (write) przy użyciu repozytorium i przekazanie wygenerowanych zdarzeń dla Event Bus-a.
- Domain objects (models) - są sercem naszej aplikacji. To w nich znajduje się złożoność biznesowa naszego systemu. Warto zwrócić uwagę na to, że na schemacie otacza je jeszcze jedna warstwa, czyli tzw. Aggragates. Jest to wzorzec wywodzący się z Domain-Driven-Design. W dużym uproszczeniu agregaty mają na celu traktowanie grupy logicznie/biznesowo powiązanych ze sobą obiektów jako jedną jednostkę. Dobrze przedstawił to Martin Fowler, który za przykład podał zamówienie oraz pozycje zamówienia. Obie te grupy teoretycznie mogą istnieć osobno, ale wygodniej jest to traktować jako jedna, spójna całość. Warto także dodać, że zmiany na obiektach domenowych generują w nich zdarzenia.
- Event - jest to obiekt reprezentujący zmiany, które zaszły w systemie. Przykładowo, konsekwencją obsłużenia przedstawionej wcześniej komendy mogłoby być zdarzenie ItemQuantityUpdatedEvent.
- Event Bus - ma dwa zadania. Po pierwsze zapewnia kolejkowanie wszystkich wygenerowanych w systemie zdarzeń. Po drugie, odszukuje odpowiedni dla danego zdarzenia Event Handler i wywołuje na nim metodę Handle.
- Event Handler - jego zadaniem jest zapisanie zmian do bazy danych, która służy do odczytu.
- Read Database Abstraction - jest to nic innego jak warstwa, która pośredniczy w pobieraniu danych. Sposób implementacji jest tutaj dowolny, dlatego sama nazwa na schemacie jest bardzo ogólna.
Domyślam się, że części z Was całość mogła jeszcze bardziej zamotać w głowie, dlatego poniżej przygotowałem diagram sekwencji, który lepiej prezentuje flow danych w systemie. Przykład prezentuje realizację komendy UpdateItemQuantityCommand:
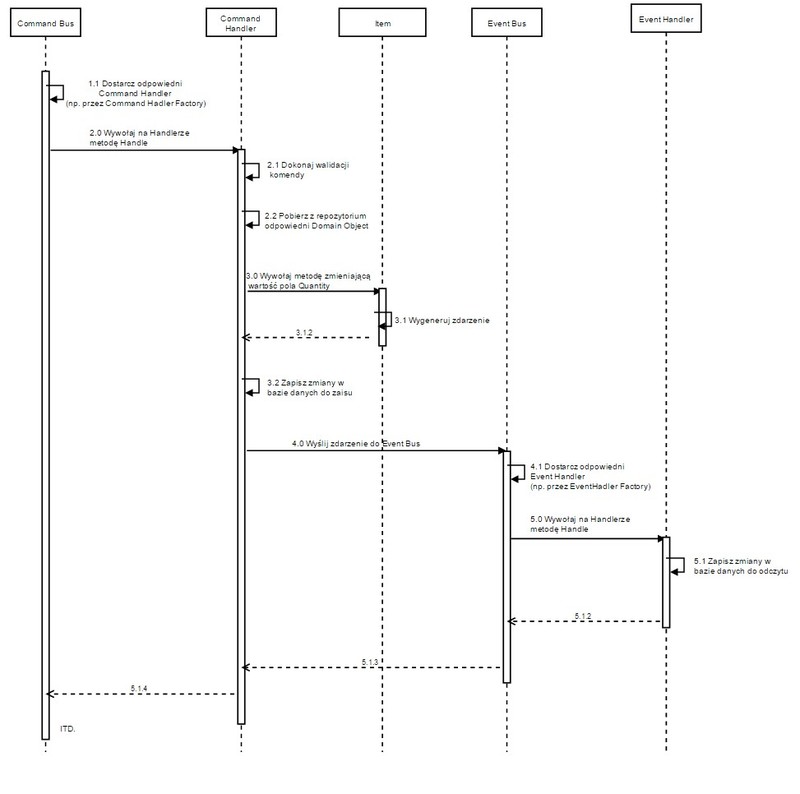
ES - Event Sourcing_
W tym wszystkim musimy jeszcze odszukać rolę Event Sourcingu. Czy jest on składową wzorca? Nie do końca.
Faktycznie, na schemacie zdarzenia wystąpiły jako sposób synchronizacji dwóch baz danych. Są one bowiem częścią CQRS, jednak takie ich zastosowanie nie realizuje założeń Event Sourcingu. Zadaniem ES jest bowiem odtwarzanie aktualnego stanu aplikacji (patrz obiektów domenowych) na podstawie zdarzeń składowanych w magazynie danych zwanym Event Store. Z początku może wydawać się to rozwiązaniem bezsensownym, jednak takim nie jest, ponieważ na podobnej zasadzie działają, chociażby systemy bankowe.
Prosty przykład. W jednym z moich wpisów o poziomach izolacji przytoczyłem przykład ilustrujący zjawisko false update (jeżeli ktoś nie czytał, niech zrobi pauzę i zapozna się z tym fragmentem na moim blogu www.foreverframe.net). Zauważcie, co spowodowało tam błąd składowanych danych. System przechowywał jedynie jedną liczbę, która informowała użytkownika o jego saldzie. Gdyby zamiast tego generowane było zdarzenie mówiące o zwiększeniu salda o konkretną kwotę, problem by nie istniał.
Dlaczego? Ponieważ zamiast jednej informacji o saldzie, moglibyśmy aplikować w naszym obiekcie domenowym eventy, które stopniowo doprowadziłby nas do aktualnego stanu konta użytkownika. Ta prosta koncepcja jest zatem bardzo potężna w swym działaniu. Jak to się ma zatem do naszego aktualnego schematu wzorca CQRS? Jedyną zmianą byłoby zastąpienie Write DB magazynem Event Store. Drugą zmianą byłby sposób pobieranie obiektów domenowych. Zamiast pobierać je "w całości" teraz należy pobrać wszystkie zdarzenia, które wygenerował dany domain object, a następnie w jego wnętrzu je aplikować, tym samym otrzymując jego stan obecny. Proste? A jakie przydatne!
Po co to wszystko_?
Wiemy zatem jak powinniśmy podejść do implementacji CQRS/ES. Nie znamy jeszcze odpowiedzi na kluczowe pytanie: po co? Klasyczne aplikacje N-Layer wydają się przy tym bardzo proste i nie komplikują systemu do tego stopnia. Przygotowałem dla Was kilka powodów, które być może przekonają Was do tego konceptu:
- Asymetryczna skalowalność - dzięki zastosowaniu dwóch źródeł danych jesteśmy w stanie wyskalować naszą aplikację w stronę odczytu lub zapisu. Ponadto takie podejście pozwala nam na projektowanie baz danych oraz dobór technologii tak, aby operacje odczytu/zapisu wykonywane były maksymalnie szybko. NoSQL? Zdenormalizowana baza danych? Czemu nie!
- Podział pracy w zespole - jak zapewne zauważyliście, strona odpowiedzialna za odczyt danych jest dużo prostsza od tej do zapisu. Ponadto nie realizuje ona żadnej logiki biznesowej. Daje nam to możliwość podziału prac w zespole tak, aby programiści z mniejszym doświadczeniem mogli rozwijać część odczytu, bez obawy o zmianę zachowania naszej aplikacji.
- Mikroserwisy - ponieważ opisane wcześniej agregaty są spoiwem łączącym pewną logiczną część naszej domeny, możemy pokusić się o rozbicie naszej monolitycznej aplikacji na mniejsze części.
- Odtworzenie stanu aplikacji z dowolnej chwili - tak jak wspomniałem, ES umożliwia nam odtwarzanie aktualnego stanu naszej aplikacji. Nic nie stoi jednak na przeszkodzie, aby zdarzenia aplikować jedynie do pewnego momentu, tym samym uzyskując stan naszej domeny z przeszłości.
- Naturalny audyt - Implementując Event Sourcing zapewniamy sobie jednocześnie bardzo przyjemny i szczegółowy audyt naszych danych.
Dariusz Pawlukiewicz - Programista pasjonat. Za sprawą konkursu „Daj się poznać” świeżo upieczony blogger oraz podcaster. Uwielbia poznawać nowe, ciekawe technologie i nie boi się używać ich w swoich projektach. Fan TypeScript oraz frameworku Aurelia. Entuzjasta DDD, CQRS i Event Sourcingu. Na co dzień pracuje, jako Full Stack Developer w Connectis_.

Chcesz rozwijać się w Connectis_? Zobacz nasze aktualne OFERTY PRACY. :)