Asynchroniczność w Angularze i jak ją ugryźć

Gdyby się głębiej zastanowić nad reaktywnym programowaniem, to można w podstawowych założeniach jego działania dostrzec pewne podobieństwa do procesu zamawiania pizzy. W obu przypadkach zaczyna się od złożenia zamówienia – zamawiając pizzę kontaktujemy się z lokalem (czy to telefonicznie czy przez aplikację) i wybieramy nasze ulubione dane z menu z dostawą w konkretne miejsce, zaś w przypadku aplikacji tworzymy zapytanie do serwera „zamawiając” konkretne dane z listy dostępnych usług.
Choćbyśmy byli głodni jak wilk, w żaden sposób nie możemy od razu usiąść i napawać się zamówioną pizzą, tak samo jak niekoniecznie będziemy mogli od razu cieszyć się z otrzymanych danych.
W obu przypadkach zanim dostaniemy zamawiany rezultat, muszą zostać wykonane z góry określone kroki. Pizza musi zostać uformowana, obsypana składnikami, upieczona i dopiero wówczas dostawca może doręczyć nam ją do rąk własnych. Jeśli zaś chodzi o dane, to najczęściej konieczne jest pobranie ich z bazy, może przefiltrowanie, posortowanie i dopiero następuje przekazanie odpowiedzi z serwera do aplikacji.
Mogłoby się wydawać absurdalne porównanie tych dwóch przypadków, ale jak widać rozłożenie ich na części pierwsze i zastanowienie się nad poszczególnymi krokami ujawnia bardzo zbliżony proces. Oczywiście ogromną różnicą jest też czas trwania obu procesów, ponieważ jeśli na dane byśmy mieli czekać tak długo jak czasem przychodzi nam czekać na pizzę… Ale na szczęście technologia zaszła już na tyle daleko, że czas pomiędzy wysłaniem zapytania a otrzymaniem odpowiedzi z serwera, to nawet jedynie milisekundy.
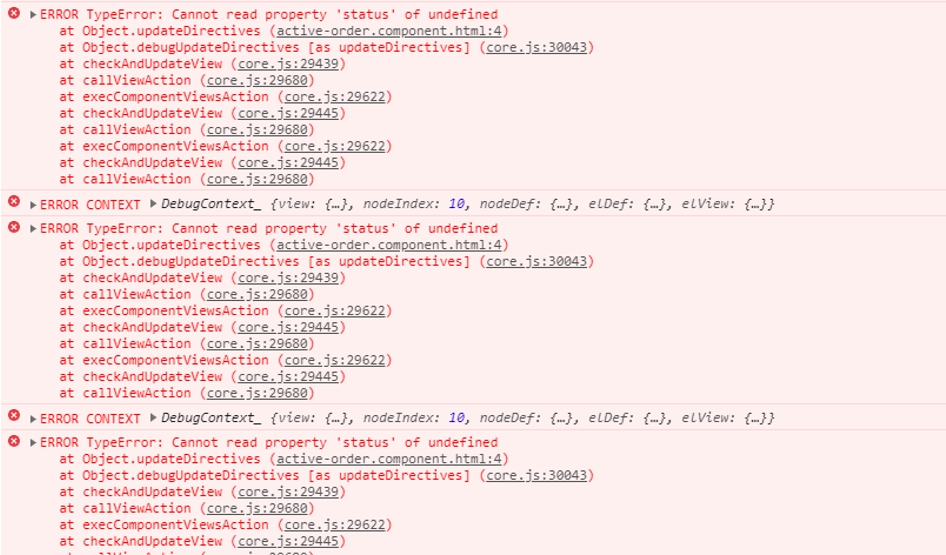
Niestety, to co dla nas ludzi może wydawać się jedynie kwestią mrugnięcia, dla frameworków to często zdecydowanie zbyt długo. Powstają wówczas takie sytuacje, gdy zanim dotrze odpowiedź z serwera, aplikacja już zdąży wygenerować widok swoich komponentów i zacznie nas okrzykiwać w konsoli, że próbujemy wykonywać operacje na danych, które przecież w ogóle nie istnieją. I mimo że wszystko może zadziać się na tyle szybko, że użytkownik mimo wszystko zobaczy poprawnie wygenerowaną stronę z właściwymi danymi, to jednak jeden rzut oka w konsolę ujawnia boleśnie czerwoną prawdę…
Strumienie i subskrypcje
Nie należy się jednak przerażać, jako że Angular dostarcza kilka wygodnych sposobów radzenia sobie z takimi asynchronicznymi danymi. Trzeba jednak pamiętać, że w trakcie tworzenia aplikacji wielokrotnie zajdzie konieczność skorzystania z nich, biorąc pod uwagę, jak bardzo współczesne aplikacje opierają się na strumieniach danych. Przykładami takich strumieni są:
- Timery i interwały– czyli strumienie aktywności w czasie,
- Dane z gniazd websocket– wspomniane już zamówienia składane do serwera,
- Dane z formularza wypełnianego przez użytkownika– przychodzą jako strumień znaków,
- Wymiana danych między komponentami– również można ją wykonać asynchronicznie.
Przed nadejściem ery Angulara już w Javascript pojawiły się mechanizmy pozwalające na pracę ze strumieniami. Najważniejszym z nich był Promise, którego poniekąd odpowiednikiem w Angularze jest Observable. Jest jednak między nimi znacząca różnica polegająca na tym, że o ile Promise mógł być wykorzystany jednokrotnie, o tyle Observable jest wielorazowy.
W praktyce działa to w taki sposób, że do strumienia danych będącego Observablem można założyć subskrypcję i to nie z jednego miejsca, ale wiele różnych komponentów może się jednocześnie subskrybować do tego samego strumienia. Wówczas za każdym razem, gdy strumień się zmieni, jego nowa wartość zostanie rozesłana do wszystkich zainteresowanych. Dla uproszczenia i zobrazowania tej funkcjonalności możemy sobie to przełożyć na prenumeratę czasopisma. Zgłaszamy się jako subskrybent i co miesiąc dostarczany jest nam do domu kolejny numer magazynu.
Kryje się tu jednak pewne niebezpieczeństwo. W realnym świecie, jeśli nie będziemy naszej hipotetycznej skrzynki pocztowej opróżniali z przychodzących do niej magazynów, to po kilku miesiącach zwyczajnie zabraknie w niej miejsca na nowe egzemplarze. Ryzyko kryje się również w świecie wirtualnym, jeśli nie zadbamy o porządek w naszych komponentach i zakończenie subskrypcji, gdy dane ze strumienia nie będą nas już interesowały. Takie niedbalstwo może spowodować wycieki danych, które z pewnością wolelibyśmy uniknąć. Na szczęście Angular w tym przypadku również ma dla nas kilka sposobów uporania się z tym problemem.
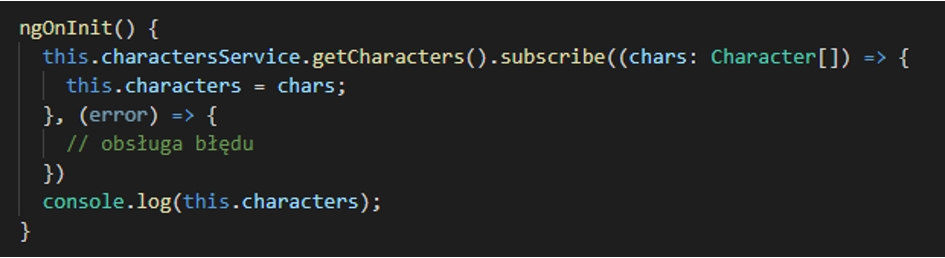
Najpierw jednak należy zrozumieć strukturę samej subskrypcji. Przykład powyżej prezentuje sposób asynchronicznego pobrania danych będących w tym przypadku listą postaci. Lista ta może być pobierana wewnątrz serwisu z zewnętrznych usług REST-owych, przez co zwyczajne odwołanie się do zmiennej przechowującej te dane w serwisie może zwrócić nam pustą listę lub błąd, gdyż może ona jeszcze nie istnieć.
Przekazywanie jej w postaci strumienia danych gwarantuje, że lokalna zmienna this.characters zostanie wypełniona danymi, jak tylko zostaną one odebrane z serwera. Należy tu również pamiętać, że wykonanie jakichkolwiek działań na odebranych strumieniu poza wnętrzem subskrypcji może nie zadziałać. W naszym przypadku console.log() wyświetli pustą listę, ponieważ zostanie wywołany przed zakończeniem pobierania danych.
Warto również pilnować deklarowania typów danych, jakie przychodzą z subskrypcji, zdecydowanie ułatwia to pracę, gdy próbujemy się odwoływać do konkretnych pól przychodzących obiektów, a i będziemy mieli pewność, że pracujemy na właściwych obiektach.
Niestety, wskazany przykład jest pierwszym krokiem do wspomnianego już wycieku danych. Może to być niezauważalne przy niewielkiej ilości subskrypcji i strumieni, ale w miarę rozwoju aplikacji ich liczba będzie się zwiększać, a takie zaniedbania zaczną powodować poważne problemy. Najprostszym sposobem jest zakończenie subskrypcji przed zniszczeniem komponentu.
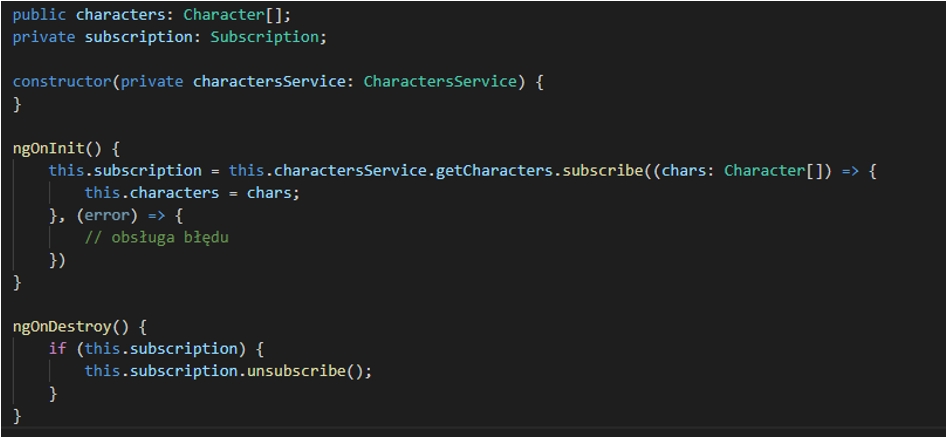
W tym rozwiązaniu konieczne jest utworzenie zmiennej komponentu o typie Subscription (lub ich listę, jeśli dany komponent odwołuje się do kilku strumieni), przypisanie do niej całej subskrypcji i w ostatnim cyklu życia komponentu onDestroy(kod zaimplementowany w tym cyklu wywoływany jest tuż przed ostatecznym unicestwieniem) odwołanie się do metody unsubscribe(), która kończy subskrypcję i chroni naszą aplikację przed niepotrzebnymi tarapatami.
RxJS na ratunek
Zdarzają się sytuacje, gdy jesteśmy zainteresowani jedynie pierwszą wartością przychodzącą ze strumienia i nie chcemy otrzymywać kolejnych. Mamy wówczas nieco ułatwione zadanie, ponieważ z pomocą przychodzi nam rozbudowana biblioteka RxJS, dostarczająca wiele operatorów pozwalających manipulować danymi odbieranymi ze strumieni. Przykładami takich operatorów są first() oraz take(number).
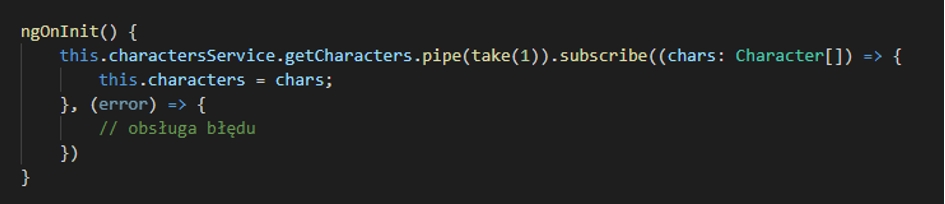
Oba operatory pozwalają uniknąć konieczności manualnego zamykania subskrypcji , ponieważ mają wbudowane automatyczne odsubskrybowanie po otrzymaniu pierwszej (lub wskazanej liczby w przypadku operatora take()) wartości ze strumienia.
Możemy również natknąć się na sytuację, gdy wykonanie jakiś działań będzie zależało od danych otrzymanych z dwóch różnych strumieni. Wracając do naszego początkowego przykładu z zamawianiem pizzy wyobraźmy sobie, że oprócz głównego dania mamy ochotę również na deser, ale z innej lokalizacji. Gdy już dociera do nas dostawa okazuje się, że jako pierwsze dotarło tiramisu zamiast pizzy i mimo wielkiej chęci na skosztowanie tego smakołyku trzeba niestety poczekać, bo przecież wszyscy wiedzą, że nie powinno się jeść deseru przed daniem głównym.
W programowaniu reaktywnym jest to całkiem prawdopodobna sytuacja, ponieważ wystarczy że pierwsza paczka danych jest większa i wymaga dodatkowej obróbki, żeby powstało opóźnienie i drugi strumień dostarczył dane wcześniej.
Na pomoc tu może ruszyć nam operator combineLatest(), który jest właśnie przeznaczony do radzenia sobie ze strumieniami, które w jakiś sposób są od siebie zależne. Zastosowanie tego operatora sprawi, że nie zostaną wyemitowane żadne dane, dopóki wszystkie zadeklarowane w nim strumienie nie wyemitują przynajmniej po jednej wartości.
RxJS ma jeszcze wiele innych operatorów, które mogą okazać się niezastąpione w przeróżnych sytuacjach. Zachęcam do zapoznania się z artykułem RxJS – 7 dobrych praktyk, gdzie są opisane w nieco większym zakresie.
Dane na front!
Tymczasem warto jeszcze pochylić się nieco nad możliwościami wykorzystania danych asynchronicznych w szablonach html i w jaki sposób uniknąć czerwonej grozy w konsoli przeglądarki. Tu również możemy zastosować dwa podejścia w zależności od potrzeb. Jeśli dane, które otrzymujemy ze strumienia, nie potrzebują dodatkowej obróbki oraz na froncie będą wołane tylko w jednym miejscu, możemy śmiało sięgnąć po prosty, ale potężny AsyncPipe.
Dużą zaletą AsyncPipe jest brak konieczności pamiętania o zakończeniu subskrypcji, jako że pipe zajmuje się jej obsługą za nas. Dzięki temu do zmiennej komponentu możemy przypisać całego Observable zwracanego przez metodę zamiast tworzyć subskrypcję i manualnie ją kończyć.

Wykorzystanie takiego tworu później w szablonie jest równie proste ponieważ jedyne co musimy zrobić, to wywołać pipe przy zmiennej i już możemy śmiało korzystać z danych, które otrzymamy w tym miejscu od serwera.

Zdarzają się jednak przypadki, gdy zastosowanie tego pipe’a staje się niemożliwe albo niewskazane. Drugi przypadek może wynikać z konieczności odwołania się do strumienia w kilku miejscach w szablonie. Każde takie wywołanie AsyncPipe powoduje otwarcie nowej subskrypcji w tle i może to spowodować niepotrzebne otwieranie nowych zawołań do tego samego strumienia po te same dane. Natomiast niemożliwe będzie wykorzystanie tej metody w sytuacji, gdy dane wymagają jakiejś dodatkowej obróbki przed wyświetleniem ich użytkownikowi, np. posortowania czy przefiltrowania. Wówczas konieczne jest zastosowania klasycznej subskrypcji w logice komponentu i odwołanie się bezpośrednio do zmiennych w szablonie.
Niestety, wołanie „w ciemno” atrybutów obiektów w szablonie może skończyć się nieprzyjemną niespodzianką w konsoli przeglądarki w najlepszym przypadku, błędami z wyświetlaniem danych w gorszym. Ale i tutaj Angular nie pozostawia nas samych sobie i daje nam proste i przyjemne narzędzie w postaci Elvisa.
Operator Elvis to nic innego jak znany już z Javascript Optional Chaining – w najnowszej wersji Typescriptu (3.7) jest wprowadzony również do części logicznej komponentów. Jego użycie jest banalnie proste, ponieważ ogranicza się do dodania znaku zapytania pomiędzy zmienną zawierającą obiekt, a odwołaniem się do jego atrybutu.

Jego działanie zaś polega na tym, że umieszczając w takim wrażliwym miejscu kolegę Elvisa zapewniamy szablon, że nie musi się denerwować, że nie będzie mógł dostać się do atrybutów obiektu, ponieważ ten operator pozwala sprawdzić, czy obiekt faktycznie istnieje, zanim pozwoli odwołać się do atrybutów.
Asynchroniczość kryje w sobie jeszcze wiele pułapek i niespodzianek, ale znajomość opisanych tu podstaw stanowi już pewną bazę, z którą można śmiało zaczynać swoją przygodę ze strumieniami danych. Należy jednak zawsze pamiętać, żeby zachować ostrożność przy działaniu z takimi danymi oraz upewnić się, że każda subskrypcja zostanie zakończona w kontrolowany sposób.