W jaki sposób DPDK może uzyskać dostęp do sprzętu z przestrzeni użytkownika?

DPDK (Data Plane Development Kit) to zestaw bibliotek do implementacji sterowników przestrzeni użytkownika dla kart sieciowych (ang. NIC — Network Interface Controller). Zapewnia zestaw abstrakcji, który umożliwia zaprogramowanie zaawansowanego potoku przetwarzania pakietów. Jak to wszystko się odbywa w praktyce? W jaki sposób DPDK uzyskuje bezpośredni dostęp do sprzętu? Jak się z nim komunikuje? Dlaczego wymagany jest moduł UIO (wejście/wyjście przestrzeni użytkownika)? Czym są hugepages i dlaczego mają takie znaczenie?
W tym wpisie na blogu postaram się wyjaśnić w klarowny sposób, jak działa standardowy sterownik karty sieciowej pracujący w jądrze systemu operacyjnego, jak program z przestrzeni użytkownika może uzyskać dostęp do sprzętu i co dzięki temu można zyskać.
Stos oprogramowania sieciowego Linux
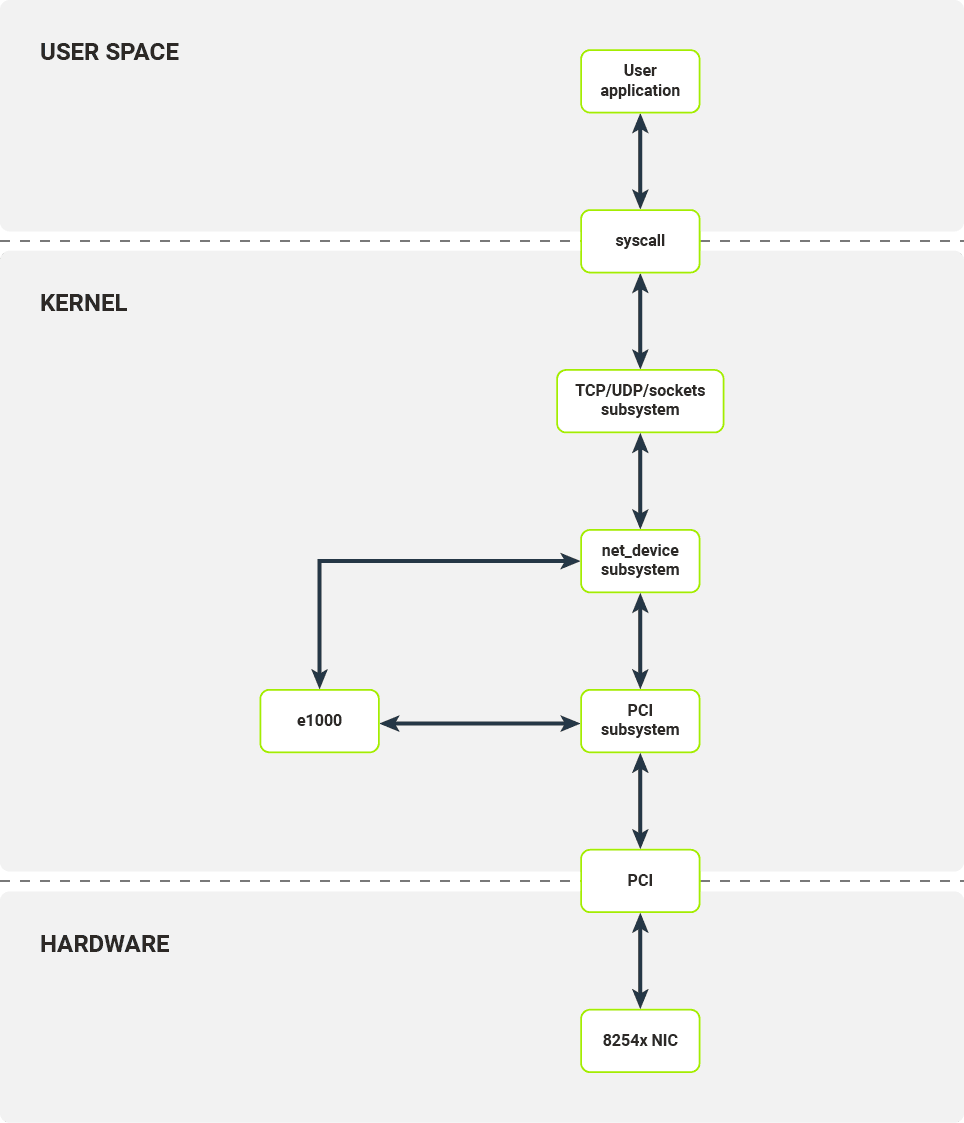 Warstwy stosu sieciowego w systemie Linux
Warstwy stosu sieciowego w systemie Linux
Zanim przejdziemy do niskopoziomowych szczegółów, przyjrzyjmy się, jak działa standardowy stos oprogramowania sieciowego w systemie Linux.
Każda aplikacja użytkownika, która chce nawiązać połączenie TCP lub wysłać pakiet UDP, musi korzystać z interfejsu socketów udostępnianego przez bibliotekę libc. W przypadku protokołu TCP interfejs ten stosuje wewnętrznie kilka wywołań systemowych:
- socket() — przydziela socket i deskryptor pliku;
- bind() — łączy socket z adresem IP i/lub parą portów protokołu (aplikacja określa oba =lub pozwala jądru wybrać adres i/lub port);
- listen() — inicjalizuje kolejkę połączeń (tylko dla TCP);
- accept4() — przyjmuje ustanowione połączenie;
- recvfrom() — odbiera bajty oczekujące na sockecie (jeśli takie istnieją; w przypadku pustego bloku bufora odczytu zwraca pusty ciąg);
- sendmsg() — wysyła bufor przez socket.
Wywołanie każdej z tych funkcji po stronie jądra wywołuje przełączenie kontekstu, które zużywa cenne zasoby obliczeniowe. Podczas przełączania kontekstu wykonywane są następujące kroki:
- Oprogramowanie przestrzeni użytkownika wywołuje funkcję po stronie jądra;
- Stan procesora (aplikacja użytkownika) jest zapisywany w pamięci;
- Tryb uprawnień procesora zostaje zmieniony z nieuprzywilejowanego na uprzywilejowany — z pierścienia (ang. ring) 3 na pierścień 0; tryb uprzywilejowany pozwala na większą kontrolę nad systemem, np. dostęp do portów IO, konfigurację tabel stron;
- Stan procesora (jądro) jest odzyskiwany z pamięci;
- Wywoływany jest kod jądra (dla danego kodu).
Załóżmy, że nasza aplikacja chce wysłać pewne dane. Zanim dane aplikacji zostaną wysłane, przechodzą przez kilka warstw oprogramowania jądra.
Interfejs socketów udostępniany przez jądro przygotowuje strukturę sk_buff, która jest kontenerem na dane pakietu i jego metadane. W zależności od protokołów niższej warstwy (warstwa sieciowa — IPv4/ IPv6 i warstwa transportowa — TCP/UDP) interfejs socketów przesyła strukturę sk_buff do modułu implementującego odpowiedni protokół. Implementacje te dodają dane niższych warstw, takie jak numery portów i/lub adresy sieciowe.
Po przejściu przez warstwy protokołu wyższego poziomu przygotowane sk_buff są przekazywane do podsystemu netdev. Urządzenie sieciowe wraz z odpowiednią strukturą netdev odpowiedzialną za wysłanie tego pakietu wybierane są na podstawie reguł routingu IP w jądrze Linuksa. Następnie wywoływane są wywołania zwrotne TX struktury netdev.
Interfejs netdev umożliwia dowolnemu modułowi zarejestrowanie się jako urządzenie sieciowe warstwy drugiej (modelu OSI) w jądrze Linuksa. Każdy moduł powinien umożliwiać konfigurację odciążania hosta (np. liczenie sum kontrolnych), sprawdzanie statystyk i przesyłanie pakietów. Odbiór pakietów jest obsługiwany przez oddzielny interfejs. Gdy przygotowany sk_buff jest gotowy do transmisji przez interfejs sieciowy, jest on przekazywany do wywołania zwrotnego TX danego modułu netdev.
W ostatnim kroku przechodzimy już do konkretnych sterowników urządzeń. W naszym przykładzie tym urządzeniem jest sterownik e1000 dla rodziny kart sieciowych 8254x.
Po otrzymaniu żądania wysłania pakietu od górnych warstw sterowników, sterownik e1000 konfiguruje bufor pakietów, sygnalizuje urządzeniu, że jest nowy pakiet do wysłania i powiadamia górną warstwę po przesłaniu pakietu (należy pamiętać, że nie oznacza to automatycznie, że pakiet został odebrany w punkcie końcowym).
Obecnie najczęściej używanym interfejsem do komunikacji między sterownikami jądra a urządzeniami sieciowymi jest magistrala PCI, np. PCI Express.
Aby komunikować się z urządzeniem PCI, moduł jądra e1000 musi zarejestrować się jako sterownik PCI w podsystemie PCI Linuksa. Podsystem PCI obsługuje wszystkie czynności wymagane do prawidłowej konfiguracji urządzeń PCI: enumeracja urządzeń na magistrali, mapowanie pamięci urządzeń i konfiguracja przerwań. Moduł jądra e1000 rejestruje się jako sterownik dla określonego urządzenia (identyfikowanego przez identyfikator dostawcy i identyfikator urządzenia). Kiedy odpowiednie urządzenie jest podłączone do systemu, moduł e1000 jest wywoływany w celu zainicjowania urządzenia, to znaczy w celu skonfigurowania samego urządzenia i zarejestrowania nowego netdev.
W następnych dwóch sekcjach zostanie wyjaśnione, w jaki sposób karta sieciowa i moduł jądra komunikują się ze sobą poprzez magistralę PCI.
Interfejsy między kartą sieciową a jądrem
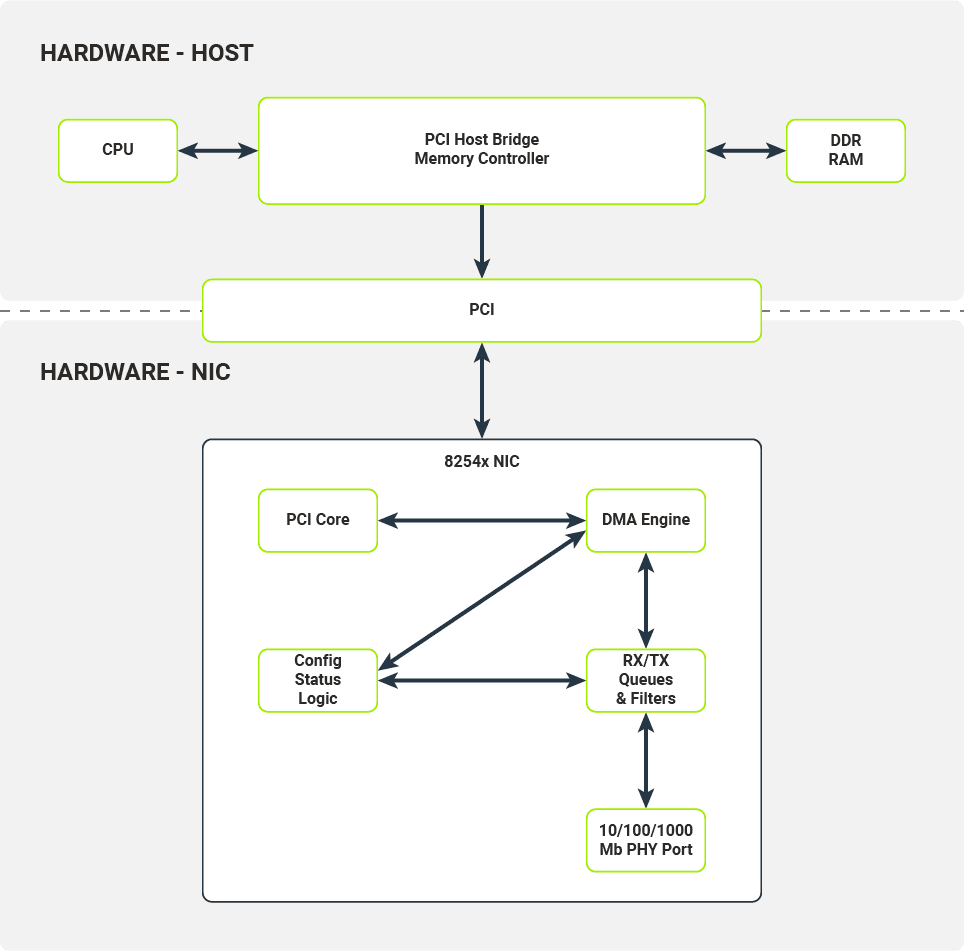 Relacje między komponentami sprzętowymi karty sieciowej i hosta
Relacje między komponentami sprzętowymi karty sieciowej i hosta
Na rysunku przedstawiono architekturę sprzętową typowego systemu komputerowego z urządzeniem sieciowym podłączonym do magistrali PCI. Użyjemy rodziny NIC 8254x, a dokładniej ich wariantów z jednym portem, jak w przykładzie.
Najważniejszymi elementami karty sieciowej są:
- Port PHY 10/100/1000 Mb
- Kolejki i filtry RX/TX
- Rejestry Config/Status/Logic
- PCI Core
- Silnik DMA
Port PHY 10/100/1000 Mb
Element sprzętowy odpowiedzialny za kodowanie/dekodowanie pakietów podczas przesyłania.
Kolejki i filtry RX / TX
Zazwyczaj realizowane jako sprzętowe FIFO (kolejki typu first in-first out), kolejki RX/TX łączą się bezpośrednio z portami PHY (fizyczne porty Ethernet). Ramki dekodowane przez port PHY są umieszczane w kolejkach RX (pojedyncza kolejka na kartach sieciowych 8254x), a następnie przetwarzane przez silnik DMA (silnik bezpośredniego dostępu do pamięci hosta). Ramki gotowe do przesłania są umieszczane w kolejkach TX, a następnie przetwarzane przez port PHY. Przed wypchnięciem do kolejek RX odebrane ramki są przetwarzane przez zestaw konfigurowalnych filtrów (np. docelowy filtr MAC, filtr VLAN, filtr multiemisji). Po przejściu przez filtr ramka jest umieszczana w kolejce RX z dołączonymi odpowiednimi metadanymi (np. nagłówkiem VLAN).
Rejestry Config/Status/Logic
Moduł Config/Status/Logic składa się ze układów sprzętowych, które konfigurują i kontrolują zachowanie karty sieciowej. Sterownik jądra może wchodzić w interakcje z tym modułem za pośrednictwem zestawu rejestrów konfiguracji odwzorowanych w fizycznej pamięci RAM. Zapisy i odczyty z niektórych lokalizacji w fizycznej pamięci RAM będą propagowane do karty sieciowej. Moduł Config/Status/Logic kontroluje zachowanie kolejek i filtrów RX/TX oraz zbiera z nich statystyki ruchu. Nakazuje także silnikowi DMA wykonywanie transakcji DMA (np. przesyłanie pakietów danych z kolejki RX do pamięci hosta).
PCI Core
Moduł PCI Core zapewnia interfejs między kartą sieciową a hostem za pośrednictwem magistrali PCI. Obsługuje wszystkie niezbędne połączenia magistrali, odwzorowanie pamięci i wysyła przerwania odbierane przez procesor hosta.
Silnik DMA
Moduł silnika DMA obsługuje i koordynuje transakcje DMA z pamięci karty sieciowej (kolejki pakietów) do pamięci hosta za pośrednictwem magistrali PCI.
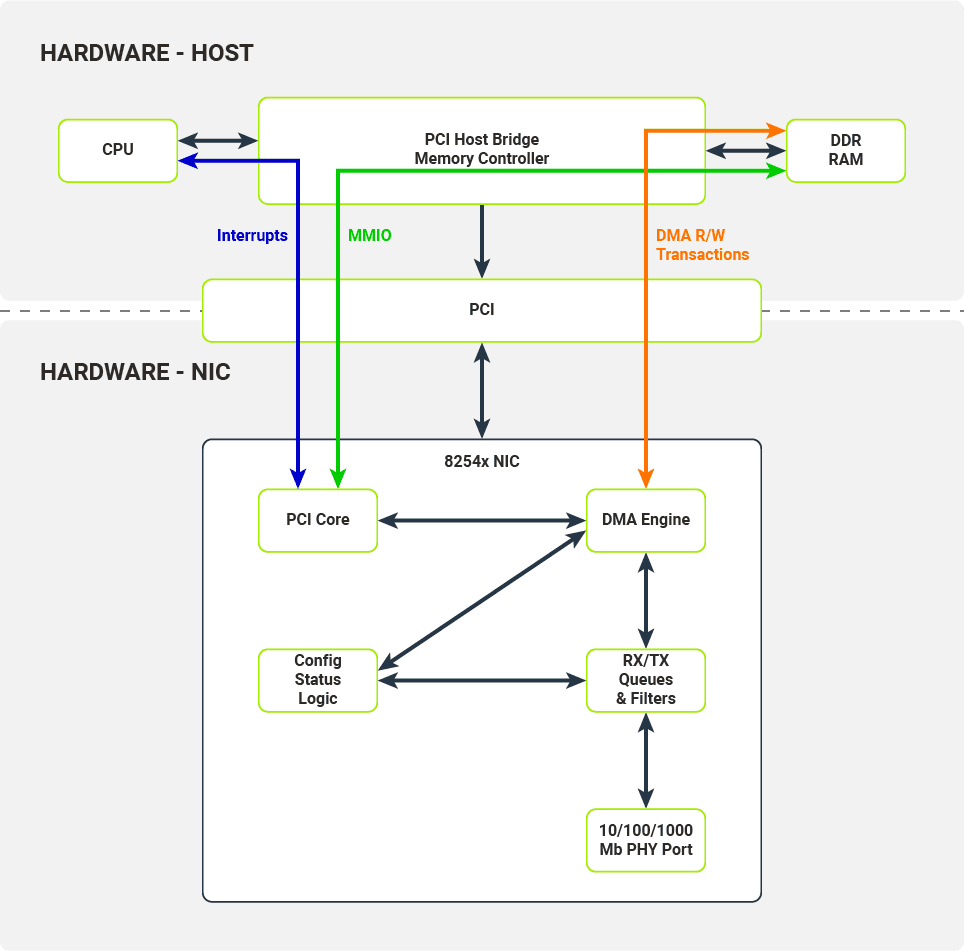 Interfejsy komunikacyjne udostępniane przez kartę sieciową i wykorzystywane przez sprzęt hosta
Interfejsy komunikacyjne udostępniane przez kartę sieciową i wykorzystywane przez sprzęt hosta
Host i karta sieciowa komunikują się przez kilka interfejsów za pośrednictwem magistrali PCI. Interfejsy te są używane przez sterowniki jądra do konfigurowania karty sieciowej i odbierania/przesyłania danych z i do kolejek pakietów.
MMIO (mapowane do pamięci wejścia-wyjścia)
Rejestry konfiguracyjne są mapowane do pamięci hosta.
Przerwania
Karta sieciowa wysyła przerwania przy określonych zdarzeniach, np. zmiana statusu łącza lub odbiór pakietu.
Transakcje R/W DMA (transakcje DMA odczytu/zapisu)
Dane pakietu są kopiowane do pamięci hosta z kolejki pakietów karty sieciowej (po odebraniu) lub kopiowane do kolejki pakietów karty sieciowej z pamięci hosta (po przesłaniu). Te transfery danych są przeprowadzane bez ingerencji procesora hosta i są kontrolowane przez silnik DMA.
Karta sieciowa do przepływu danych jądra
Aby lepiej zrozumieć przepływ danych między kartą sieciową a jądrem, omówmy teraz przepływ danych przy wysyłaniu pakietu. Krok po kroku omówione zostaną struktury danych wymagane przez kartę sieciową i sterownik jądra w celu otrzymania pakietów.
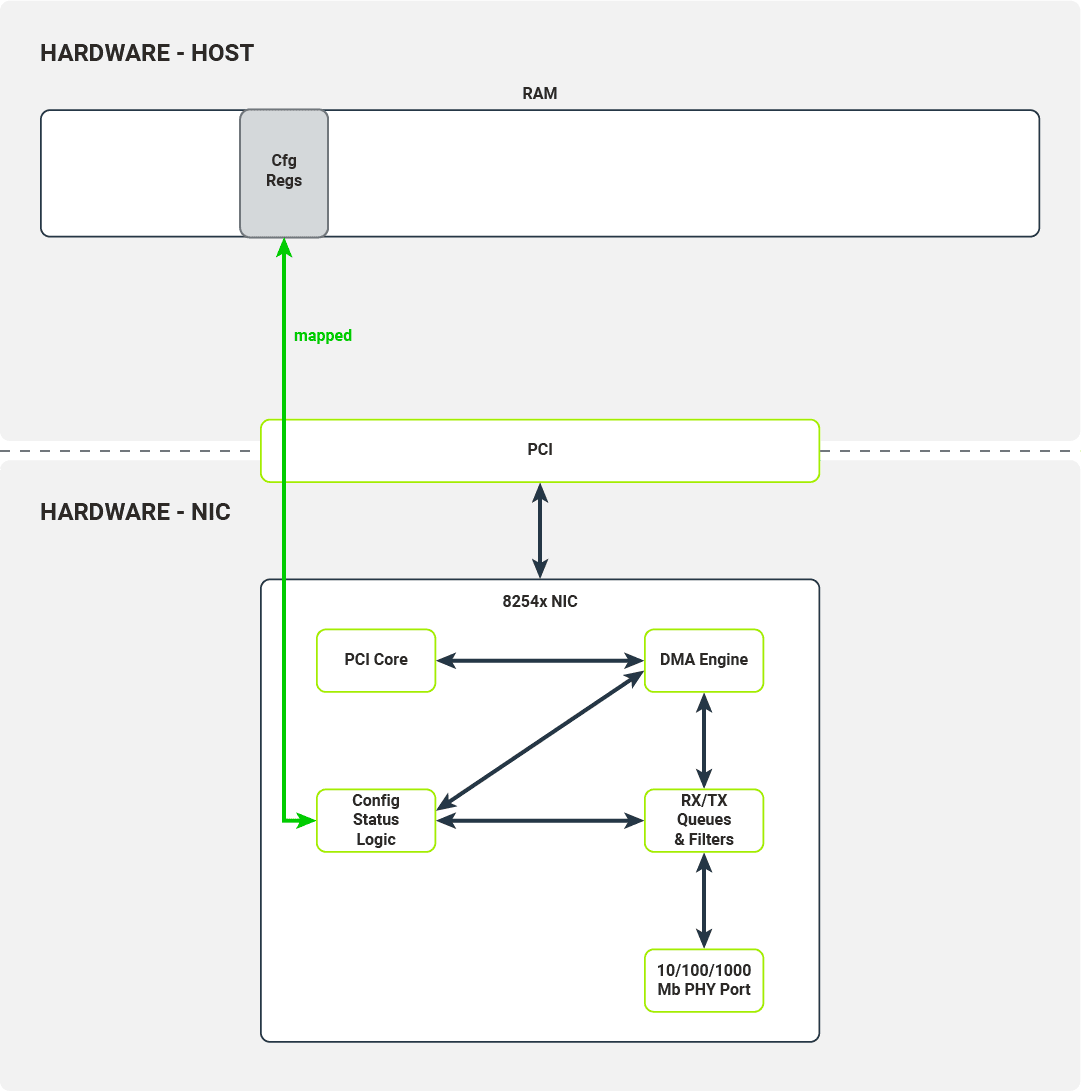 Rejestry konfiguracyjne są mapowane do pamięci hosta
Rejestry konfiguracyjne są mapowane do pamięci hosta
Po zarejestrowaniu karty sieciowej przez podsystem PCI jądra sterownik włącza MMIO dla tego urządzenia poprzez odwzorowanie regionów pamięci IO na przestrzeń adresową jądra. Sterownik użyje tego obszaru pamięci, aby uzyskać dostęp do rejestrów konfiguracyjnych karty sieciowej i kontrolować jej działanie. Sterownik może na przykład:
- sprawdzić status łącza
- włączyć lub wyłączyć przerwania
- zmienić opcje automatycznej negocjacji Ethernet
- wykonać odczyt/zapis do pamięci Flash/EEPROM na karcie sieciowej
Gdy sterownik chce skonfigurować odbiór pakietów, uzyskuje dostęp do następującego zestawu rejestrów konfiguracji:
- Receive Control Register — włącza/wyłącza odbiór pakietów, konfiguruje filtry RX,
- Receive Descriptor Base Address — adres podstawowy bufora deskryptora odbioru
- Receive Descriptor Length — maksymalny rozmiar bufora deskryptora odbioru
- Receive Descriptor Head/Tail — przesunięcia od początku bufora deskryptora odbioru wskazują na początek/koniec kolejki deskryptorów odbioru
- Interrupt Mask Set/Read — włączanie/wyłączanie przerwań odbierania pakietów
Większość z tych rejestrów konfiguracyjnych służy do konfigurowania bufora deskryptora odbioru.
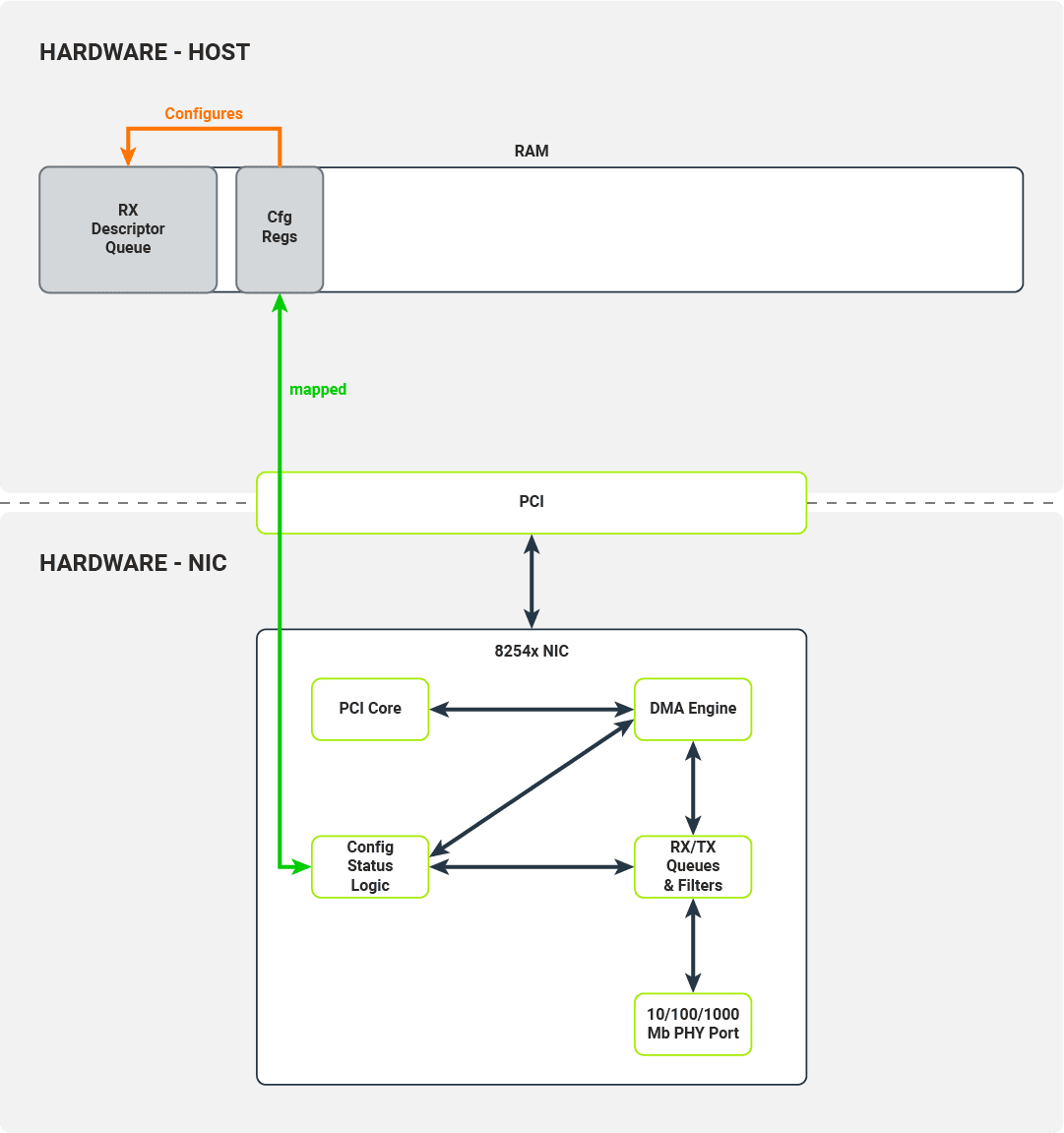 Rejestry konfiguracji opisują lokalizację kolejki buforów deskryptorów RX
Rejestry konfiguracji opisują lokalizację kolejki buforów deskryptorów RX
Bufor odebranych deskryptorów to ciągła tablica deskryptorów pakietów. Każdy deskryptor opisuje fizyczne lokalizacje pamięci, w których dane pakietu będą zapisywane przez kartę sieciową i zawiera pola statusu określające, które pakiety przeszły pomyślnie przez filtry. Sterownik jądra jest odpowiedzialny za alokację buforów pakietów, do których może pisać silnik DMA karty sieciowej. Po pomyślnej alokacji pamięci sterownik umieszcza adresy fizyczne tych buforów w deskryptorach pakietów.
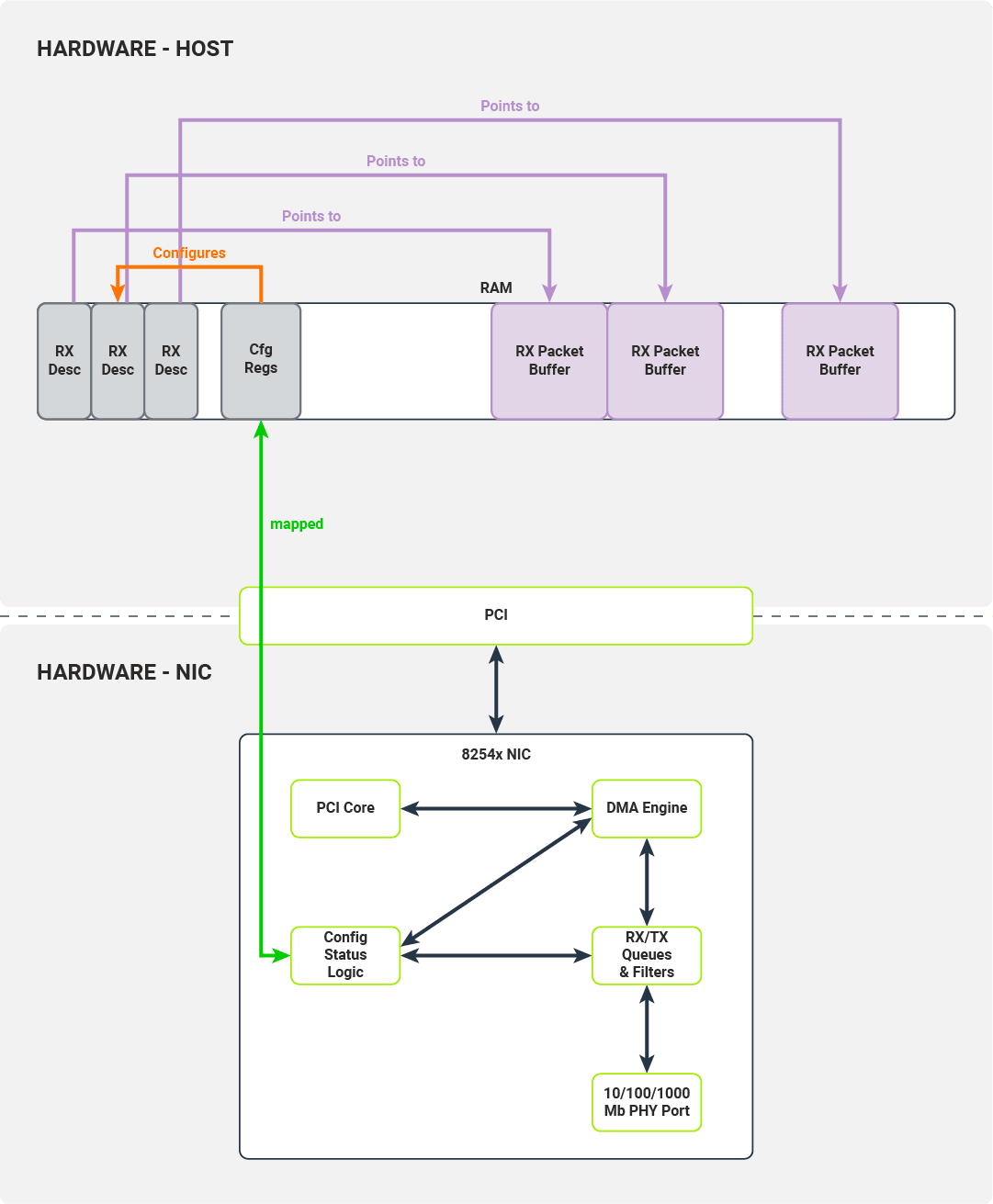 Każdy deskryptor RX ma wskaźnik opisujący lokalizację odpowiedniego bufora pakietów
Każdy deskryptor RX ma wskaźnik opisujący lokalizację odpowiedniego bufora pakietów
Sterownik zapisuje adres początku bufora deskryptora pakietów do rejestru konfiguracji, inicjuje kolejkę deskryptorów odbioru (inicjując rejestry Receive Descriptor Head/Tail) i włącza odbiór pakietów. Gdy port PHY otrzyma pakiet, umieszcza go w kolejce RX karty sieciowej, przechodząc przez skonfigurowany filtr. Pakiety gotowe do przesłania do hostów są przesyłane przez silnik DMA do pamięci hostów. Docelowa lokalizacja pamięci jest pobierana z końca kolejki deskryptorów.
Silnik DMA aktualizuje pola stanu w ostatnim deskryptorze kolejki, a po zakończeniu operacji karta sieciowa inkrementuje wskaźnik końca kolejki. Na końcu PCI Core generuje przerwanie dla hosta, sygnalizując, że inny pakiet jest gotowy do przetworzenia przez sterownik.
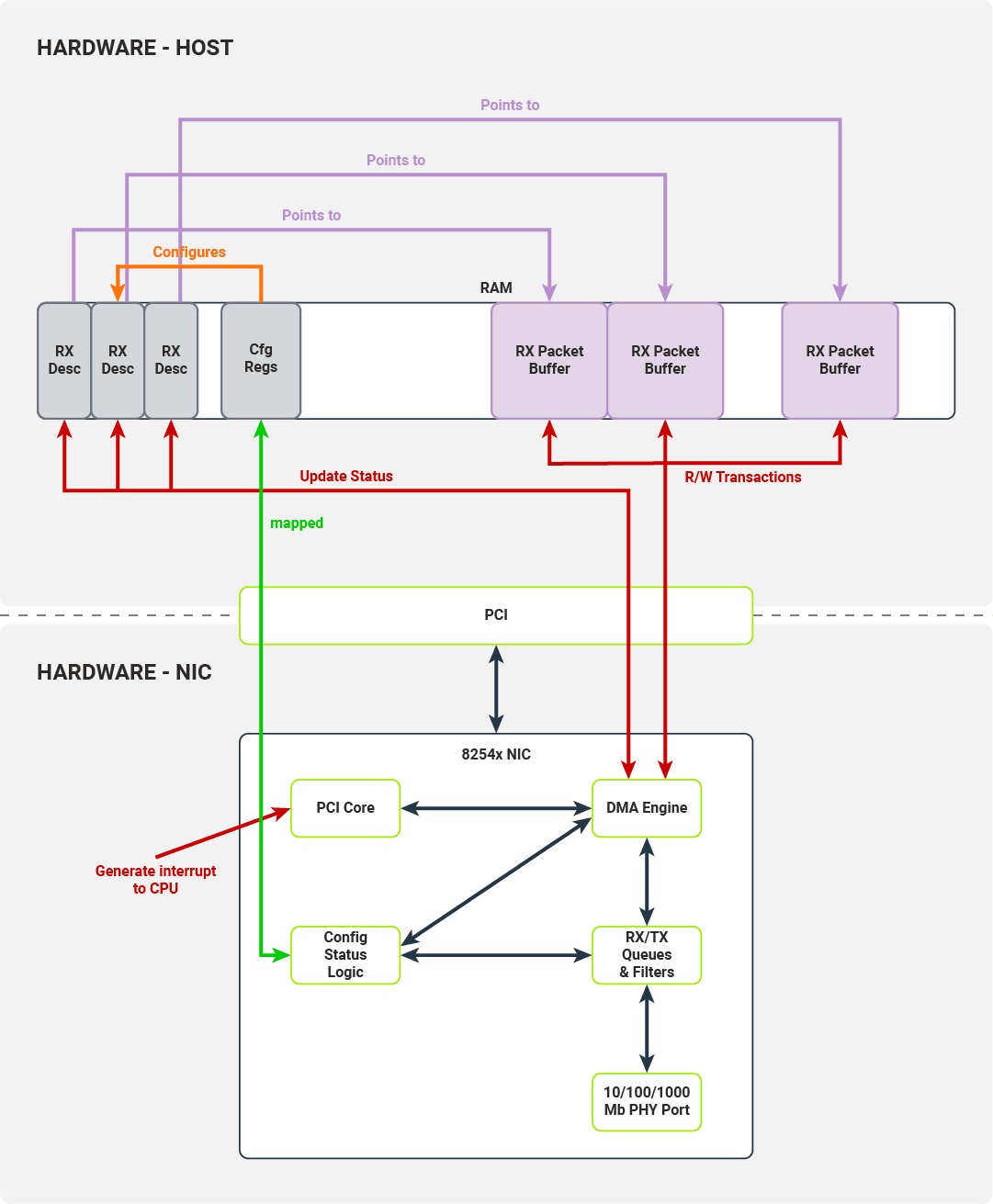 Interfejsy wykorzystywane do przesyłania pakietu do pamięci hosta i sygnalizowania hostowi, że pakiet został odebrany
Interfejsy wykorzystywane do przesyłania pakietu do pamięci hosta i sygnalizowania hostowi, że pakiet został odebrany
W przypadku ścieżki transmisji pakietu przeprowadzany jest podobny proces. Sterownik jądra umieszcza dane pakietu w buforze pakietów wskazanym przez pole lokalizacji pamięci w deskryptorze pod wskaźnikiem końca kolejki. Sterownik jądra oznacza pakiet jako gotowy do przesłania i inkrementuje wskaźnik końca kolejki.
Gdy wskaźniki początku i końca kolejki deskryptorów różnią się, karta sieciowa sprawdza deskryptor pakietu pod wskaźnikiem początku kolejki i inicjuje transakcję DMA w celu przesłania danych pakietu z pamięci hosta do kolejki pakietów TX. Po zakończeniu transakcji karta sieciowa inkrementuje wskaźnik początku kolejki.
Sterowniki przestrzeni użytkownika
Omówiliśmy sposób, w jaki sterowniki przestrzeni jądra komunikują się ze sprzętem. DPDK jest jednak programem przestrzeni użytkownika, a taki program nie może bezpośrednio korzystać ze sprzętu. Stanowi to źródło kilku problemów:
- Jak uzyskać dostęp do rejestrów konfiguracyjnych;
- Jak uzyskać adresy pamięci fizycznej dla przydzielonej programowi pamięci;
- Jak zapobiegać zrzucaniu pamięci procesu na dysk lub zmianie jej lokalizacji w pamięci w trakcie działania?
- Jak odbierać przerwania.
W tej części omówimy mechanizmy dostępne w jądrze Linuxa, które umożliwiają przezwyciężenie tych przeszkód.
Dlaczego przestrzeń użytkownika?
Istnieją trzy główne powody uzasadniające przeniesienie sterowników z jądra do przestrzeni użytkownika:
- Zmniejszenie liczby przełączeń kontekstu wymaganych do przetworzenia pakietów — każde wywołanie systemowe powoduje przełączenie kontekstu, co zajmuje czas i zasoby.
- Zmniejszenie ilości oprogramowania w stosie — jądro Linuksa dostarcza abstrakcje ogólnego zastosowania, które mogą być wykorzystane przez dowolny program; Zaimplementowanie stosu sieciowego tylko dla określonych przypadków użycia pozwala nam na usunięcie niepotrzebnych abstrakcji, co upraszcza rozwiązanie i może poprawić jego wydajność.
- Sterowniki przestrzeni użytkownika są łatwiejsze do opracowania niż sterowniki jądra — jeśli chcesz opracować sterownik jądra dla bardzo konkretnego urządzenia, jego utrzymanie i rozwój mogą być trudne. W przypadku Linuksa korzystne byłoby włączenie sterownika do głównej gałęzi rozwojowej Linuksa (do upstreamu), co zajmuje sporo czasu i wysiłku. Co więcej, jesteśmy ograniczeni harmonogramem wydań Linuksa. Poza tym błędy w sterowniku mogą spowodować awarię jądra.
UIO
Przypomnijmy sobie na chwilę stos sieciowy Linuksa. Interfejsy używane do bezpośredniej komunikacji ze sprzętem są udostępniane przez podsystem PCI jądra i jego podsystem zarządzania pamięcią (mapowanie obszarów pamięci IO). Aby nasz sterownik przestrzeni użytkownika miał bezpośredni dostęp do urządzenia, interfejsy te muszą zostać w jakiś sposób udostępnione procesom. Linux może je udostępnić, korzystając z podsystemu UIO.
UIO (Wejście/wyjście przestrzeni użytkownika) to osobny moduł jądra odpowiedzialny za konfigurację abstrakcji dla przestrzeni użytkownika wykorzystywanych przez procesy użytkownika do komunikacji ze sprzętem. Ten moduł konfiguruje wewnętrzne interfejsy jądra do przekazywania urządzeń do przestrzeni użytkownika.
Aby użyć UIO dla urządzenia PCI, należy powiązać kartę sieciową ze sterownikiem uio_pci_generic (ten proces wymaga odpięcia dedykowanego sterownika urządzenia, np. E1000, i ręcznego powiązania sterownika uio_pci_generic). Ten sterownik to sterownik PCI, który współpracuje z modułem UIO, aby udostępnić interfejsy PCI urządzenia w przestrzeni użytkownika. Interfejsy udostępnione przez UIO są przedstawione na diagramie.
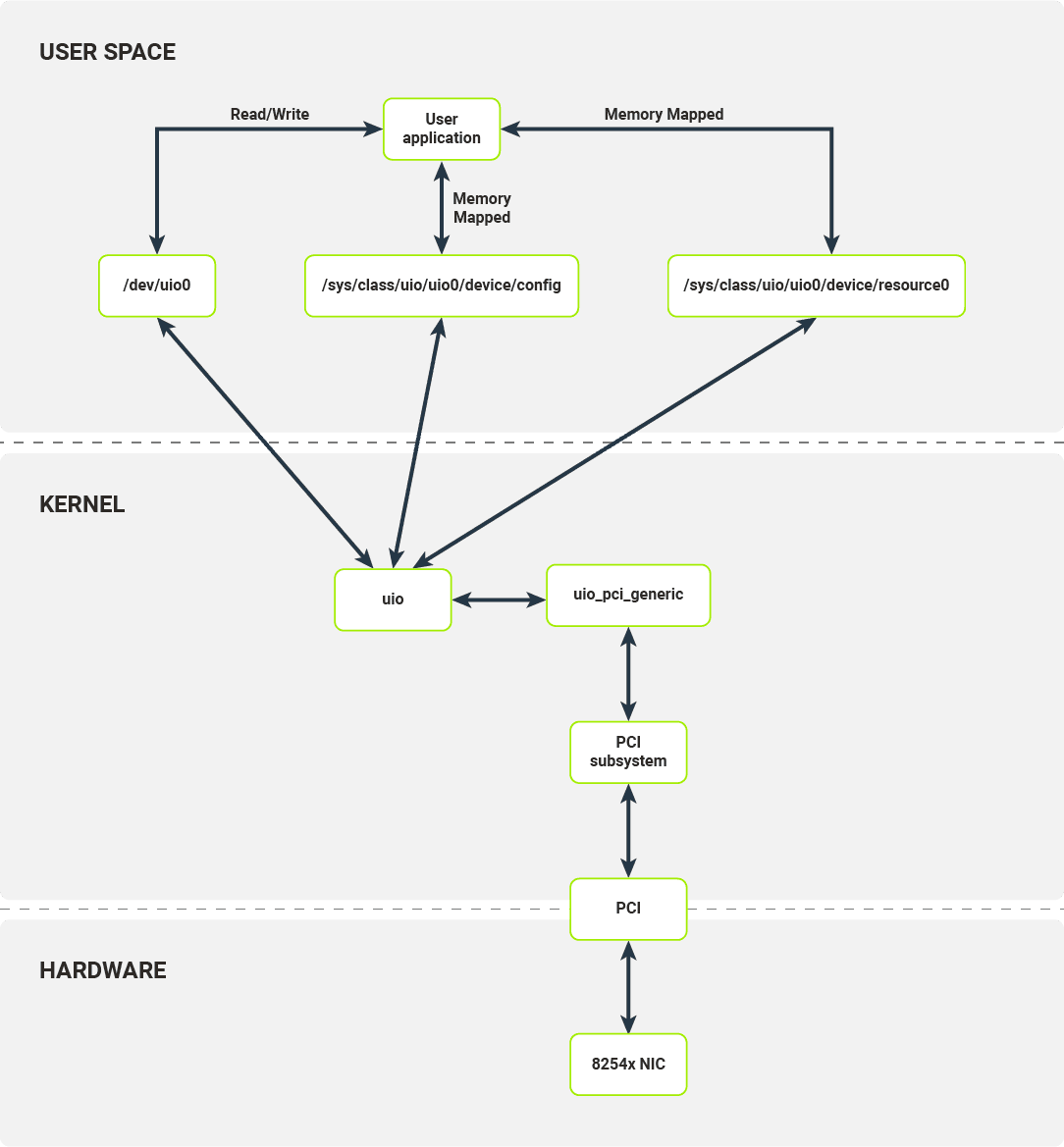 Warstwy oprogramowania stosu sieciowego w systemie Linux podczas korzystania z UIO
Warstwy oprogramowania stosu sieciowego w systemie Linux podczas korzystania z UIO
Dla każdego powiązanego urządzenia moduł UIO udostępnia zestaw plików, z którymi mogą współpracować aplikacje przestrzeni użytkownika. W przypadku karty sieciowej 8254x ujawnia on:
- /dev/uio0 — odczyty z tego pliku pozwalają programowi przestrzeni użytkownika odbierać przerwania; odczyt blokuje program do momentu otrzymania przerwania; wywołanie read() zwraca liczbę otrzymanych przerwań;
- /sys/class/uio/uio0/device/config — przestrzeń użytkownika może odczytać lub zmapować ten plik; jest on bezpośrednio mapowany do przestrzeni konfiguracyjnej urządzenia PCI, w której przechowywane są np. identyfikator urządzenia i dostawcy;
- /sys/class/uio/uio0/device/resource0 — przestrzeń użytkownika może mapować ten plik; umożliwia on programowi przestrzeni użytkownika dostęp do BAR0, pierwszego obszaru pamięci IO urządzenia PCI, a zatem program przestrzeni użytkownika może odczytywać z rejestrów konfiguracji urządzeń PCI i zapisywać do nich;
W pewnym sensie moduł UIO zapewnia tylko zestaw translacji pamięci, umożliwiając procesowi przestrzeni użytkownika konfigurację urządzenia i otrzymywanie powiadomień o przerwaniach urządzenia.
Aby poprawnie zaimplementować potok przetwarzania pakietów, musimy zdefiniować bufor deskryptorów RX/TX. Każdy bufor deskryptora ma wskaźnik (adres pamięci), który wskazuje na wcześniej przydzielone bufory pakietów. Karta sieciowa akceptuje tylko adresy fizyczne jako prawidłowe lokalizacje pamięci, na których można przeprowadzać transakcje DMA, ale procesy mają własną wirtualną przestrzeń adresową.
Możliwe jest znalezienie adresu fizycznego odpowiadającego każdemu adresowi wirtualnemu (przy użyciu interfejsu /proc/self/pagemap), ale nie można polegać na tym odwzorowaniu w trakcie działania procesu. Dzieje się tak z następujących powodów:
- Pamięć procesu może zostać zrzucona na dysk twardy, a następnie przywrócona co zmieni jego lokalizację(Uwaga: można tego uniknąć używając funkcji mlock().)
- Proces można przenieść do innego węzła NUMA, a jądro może przenieść jego pamięć(Jądro Linux nie gwarantuje, że fizyczne strony pozostaną w tym samym miejscu w trakcie działania procesu. W tym miejscu ważny staje się mechanizm hugepages.)
Hugepages
W architekturze x86 (zarówno wersje 32-, jak i 64-bitowe) standardowe fizyczne strony mają rozmiar 4 KB. Hugepages zostały wprowadzone do architektury, aby rozwiązać dwa problemy:
- Po pierwsze, aby zmniejszyć liczbę wpisów w tabeli stron wymaganych do reprezentowania ciągłych fragmentów pamięci większych niż 4KB. Zmniejsza to użycie TLB, a tym samym ogranicza przeładowanie TLB; (TLB — Translation Lookaside Buffer — jest wbudowanym cache'em dla wpisów w tablicy stron);
- Po drugie, aby zmniejszyć całkowity rozmiar tabeli stron.
W architekturze x86, w zależności od wsparcia sprzętowego, strony mogą mieć rozmiar 2 MB lub 1 GB. Podsystem zarządzania pamięcią jądra systemu Linux pozwala administratorowi zarezerwować pulę hugepages, która będzie wykorzystywana przez procesy przestrzeni użytkownika. Domyślnie, gdy jądro jest skonfigurowane do wstępnego przydzielania hugepages, proces przestrzeni użytkownika może utworzyć plik w katalogu /dev/hugepages. Ten katalog jest obsługiwany przez pseudosystem plików, hugetlbfs. Każdy plik utworzony w tym katalogu będzie znajdował się bezpośrednio w pamięci składającej się tylko i wyłącznie z hugepages.
Proces przestrzeni użytkownika może tworzyć pliki o wymaganym rozmiarze, a następnie mapować je do swojej przestrzeni adresowej. Proces przestrzeni użytkownika może następnie uzyskać adres fizyczny tego regionu pamięci z /proc/self/pagemap i użyć go do obsługi buforów pakietów w kolejce deskryptorów.
Bezpiecznie jest używać hugepages jako pamięci do obsługi kolejki deskryptorów i buforów pakietów, ponieważ jądro Linuksa gwarantuje, że fizyczna lokalizacja tych stron nie zmieni się podczas działania.
Poniższy rysunek ilustruje kolejkę pakietów RX ze zmianami pokazującymi, które interfejsy są wykorzystywane przez proces przestrzeni użytkownika.
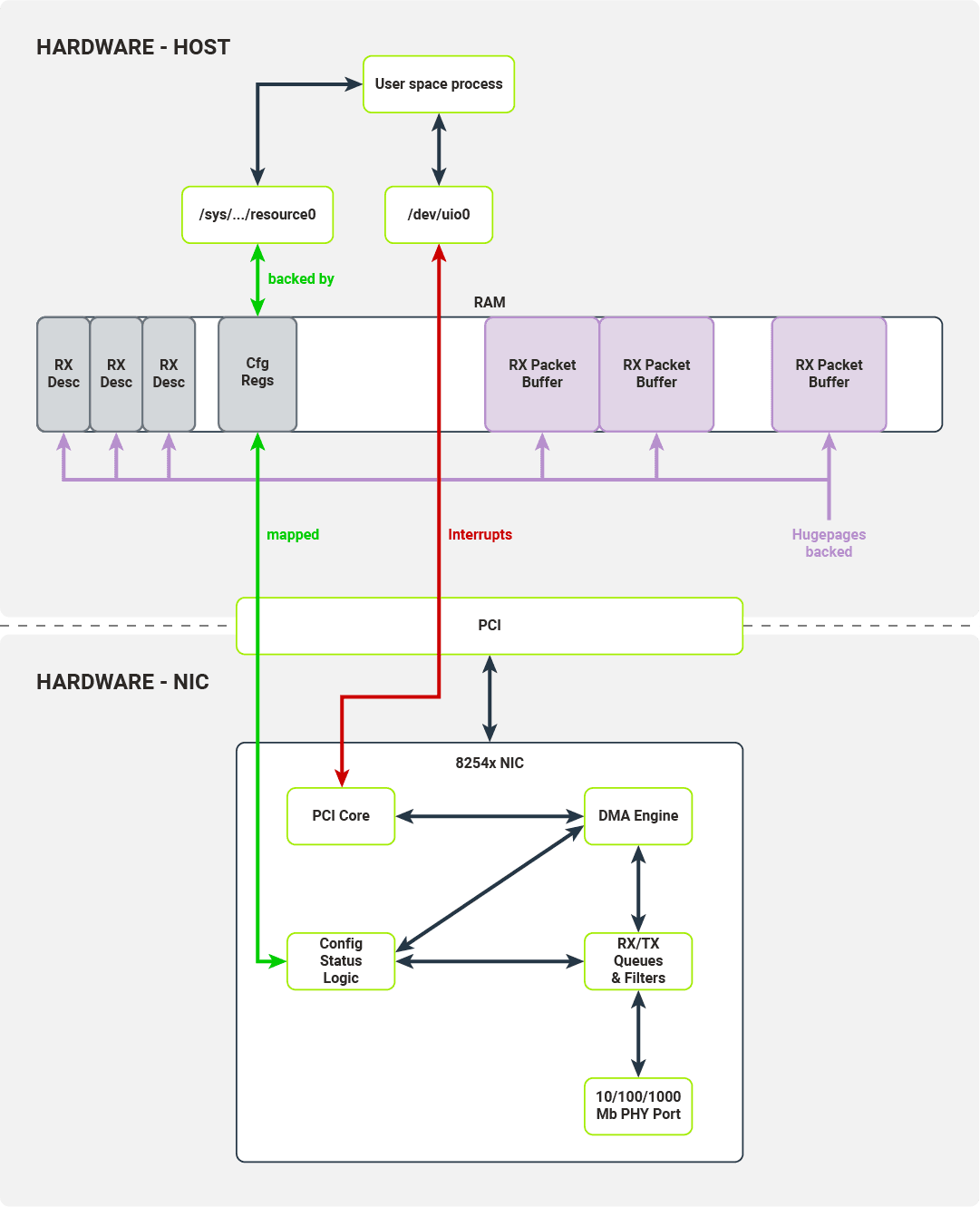 Interfejsy wykorzystywane do przesyłania pakietu do pamięci hosta i sygnalizowania hostowi, że pakiet został odebrany.
Interfejsy wykorzystywane do przesyłania pakietu do pamięci hosta i sygnalizowania hostowi, że pakiet został odebrany.
Podsumowanie
W tym artykule omówiliśmy:
- Standardowy potok przetwarzania pakietów w sterownikach jądra;
- Dlaczego procesy przestrzeni użytkownika nie mają bezpośredniego dostępu do sprzętu;
- Interfejsy udostępnione przez jądro Linuksa w przestrzeni użytkownika, które pozwalają użytkownikom tworzyć sterowniki przestrzeni użytkownika.
Sam temat jest bardzo obszerny, dlatego do omówienia zostają inne ciekawe zagadnienia związane z DPDK:
- Jak DPDK korzysta z przedstawionych przez nas interfejsów;
- Schemat działania typowej aplikacji DPDK;
- W jaki sposób przedstawione interfejsy i architektura aplikacji pozwalają DPDK poprawić wydajność przetwarzania pakietów.