

Víctor Suárez FernándezBeca DevOpsThe Cocktail
Wdrażanie środowisk bez duplikowania kodu
Sprawdź, jak stworzyć środowisko, które pozwoli na wdrażanie innych bez potrzeby duplikowania kodu.
Przychodzisz wcześnie do biura i jesteś nad wyraz chętny do pracy. Do zrobienia jest dużo fajnych rzeczy, no i możesz pracować z nowymi technologiami. Twoim pierwszym zadaniem jest skonfigurowanie wielu środowisk: nowego środowiska produkcyjnego oraz niektórych środowisk przedprodukcyjnych dla programistów i dla Ciebie. Jest tylko jeden warunek: musisz używać infrastruktury jako kodu.
Zbyt duża optymalizacja kosztów
Architektura ta jest bardzo prosta: klasyczna trójwarstwowa architektura z frontendem, backendem i bazami danych oraz równoważeniem obciążenia pomiędzy warstwami.
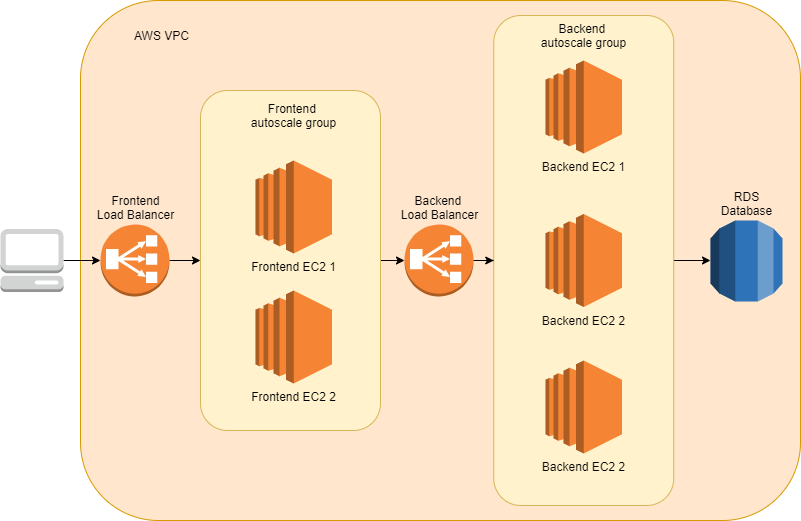
Architektura do wdrożenia
Konfiguracja posuwa się do przodu, a za kilka godzin całość powinna być gotowa. Czas skonfigurować inne środowiska, ale widzimy tutaj, że niektóre koszty ponosimy niepotrzebnie. Czy mój zespół potrzebuje czterech replik backendu w środowisku testowym? A co z bazą danych? Nie potrzebujemy t3.xlarge, ponieważ t3.medium w zupełności wystarcza. Na samym końcu zdajemy sobie sprawę, że w środowiskach nieprodukcyjnych nie ma potrzeby oddzielania warstw. W ten sposób łączymy infrastrukturę dla frontendu oraz backendu.
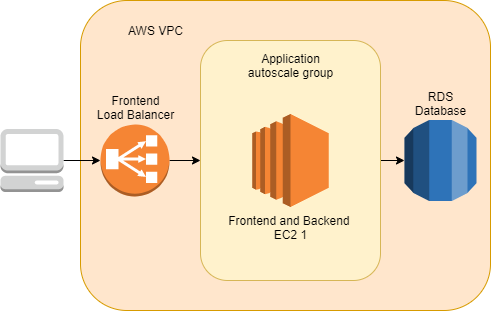
Architektura w środowisku testowym
Tutaj pojawiają się obawy. Czy naprawdę chcemy zmieniać wymuskaną architekturę dostarczoną przez nasz zespół architektów (albo, co gorsza, przez nas samych) ze względu na nadmierne obawy o koszty? Dobrze, już dość. Przeskoczmy trochę do przodu.
Czy opłaca się oszczędzać?
Produkt został dostarczony, więc programowanie ogranicza się teraz do naprawiania błędów i sporadycznego rozwijania nowych funkcji. Infrastrukturę trzeba utrzymywać. W wyniku naszych zmian w architekturze otrzymujemy następującą strukturę kodu:
terraform/
├── production/
│ ├── main.tf
│ ├── frontend.tf
│ ├── backend.tf
│ ├── database.tf
├── staging/
│ ├── main.tf
│ ├── app.tf
│ ├── database.tf
Oprócz oczywistej zmiany w architekturze istnieje również duży problem z kodem: duplikacja. W wyniku naszych potrzebujemy dwóch różnych katalogów z tym samym kodem (w większości). Ale dlaczego? Po pierwsze, ma to na celu utrzymanie stanu każdego środowiska, ponieważ nie są one zarządzane przez ten stan w terraform.
Po drugie, ponieważ zmieniła się integracja między warstwami, a zatem niektóre fragmenty kodu, takie jak grupy zabezpieczeń między warstwami lub grupy skalowania automatycznego, mogą nie być konieczne. W wyniku powielania kodu pojawia się duży problem, polegający na tym, jak wprowadzamy zmiany na platformie. To bardzo łatwe w przypadku takich prostych zmian, jak konfiguracja — musimy tylko przejść do odpowiedniego pliku i zmienić wartość.
Ale co, jeśli infrastruktura wymaga nowych funkcji? Skończy się na tym, że będziemy pisać nowy kod, a następnie go testować. Testujemy go w środowisku testowym, a jeśli tam działa idealnie, to powinien również na produkcji. Jest tutaj jednak jedno „ale”: nowa funkcja będzie poprawnie działać w środowisku produkcyjnym tylko wtedy, gdy integracja i inne procesy są tam takie same, jak w środowisku testowym. Czy możemy przyjąć takie założenie? Niestety nie.
Nasz kod jest inny dla każdego środowiska. Wdrożenie nowych funkcji w takiej infrastrukturze będzie zatem wielkim wyzwaniem, ponieważ wymaga to zarówno kodowania, jak i testowania funkcji w każdym z tych środowisk.
Jedno, by wszystkimi rządzić
Co można zrobić, aby tego uniknąć? Programiści mają do dyspozycji coś, co nazywa się programowaniem obiektowym, w którym definiują klasę, a następnie tworzą instancje tej klasy (i jej obiektów) o różnych wartościach. Potem muszą tylko przetestować daną klasę za pomocą jednego obiektu i mogą być pewni, że test przejdzie też dla innych obiektów tej samej klasy. Czy nie można tego pomysłu zaadaptować dla infrastruktury jako kodu?
Aby to zrobić, musimy użyć kodu do ścisłego zdefiniowania architektury, pozostawiając wartości konfiguracyjne jako zmienne. W ten sposób możemy zdefiniować konfigurację w plikach dla każdego środowiska, podczas gdy integrację między częściami można wtedy przetestować tylko raz.
Być może nie zagwarantuje to, że to, co działa podczas testów, zadziała również w środowisku produkcyjnym (bo mamy jeszcze zależności konfiguracyjne), ale sprawi, że niezwykle łatwo będzie wdrażać, testować i debugować zmiany w środowiskach.
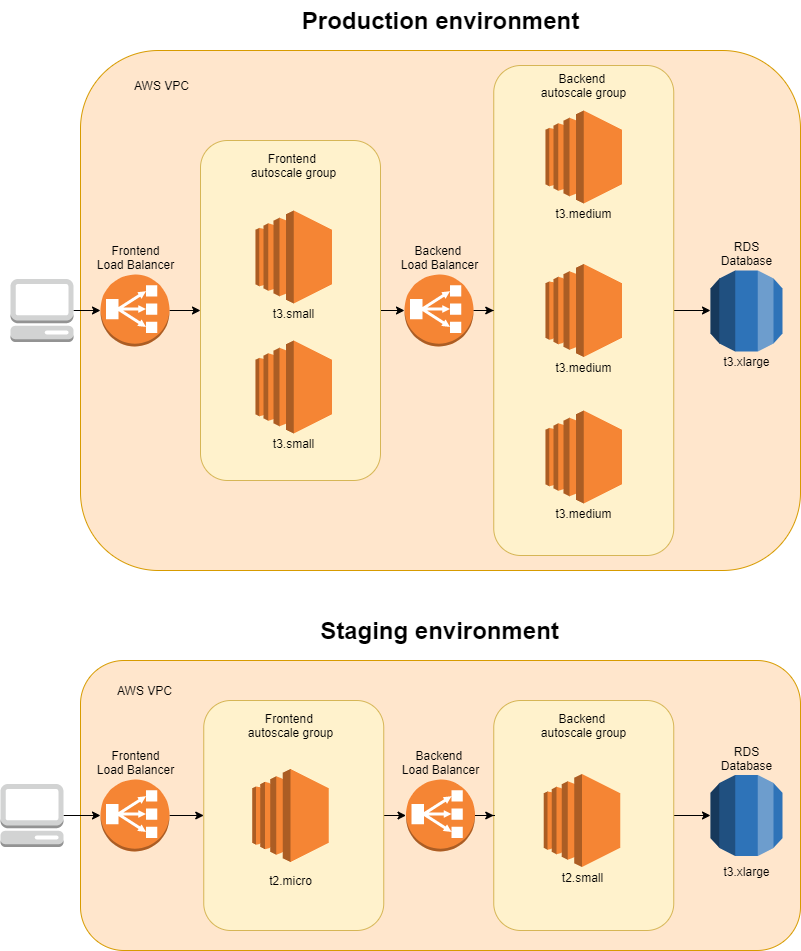
Środowiska korzystające z szablonu środowiska
Na koniec dostajemy nową strukturę kodu:
terraform/
├── variables/
│ ├── production.tfvars
│ ├── staging.tfvars
├── main.tf
├── frontend.tf
├── backend.tf
├── database.tf
Dzięki temu stworzyliśmy szablon środowiska, którego możemy użyć do wdrożenia innych środowisk. Każde nowe środowisko będzie mieć niezależny stan, bez potrzeby duplikowania kodu.
