

Dexter DarwichComputer EngineerYardi
Porównanie Javy, Go i Rusta
Poznaj różnice między Javą, Go oraz Rustem pod kątem zużycia pamięci i procesora przez programy napisane w tych językach.
W tym artykule porównam Javę, Go i Rusta. Nie będę tutaj robić wielkich testów porównawczych - zestawię raczej wielkości wyjścia pliku wykonywalnego, zużycie pamięci, procesora oraz wymagania dotyczące czasu wykonywania. Zrobię tylko mały test porównawczy, aby mieć trochę wyników - potem spróbuję je przeanalizować i zrozumieć. Porównujemy tutaj bardzo podobne rzeczy, dlatego napisałem usługę webową w każdym z tych języków. Usługa ta jest bardzo prosta i obsługuje trzy punkty końcowe REST.
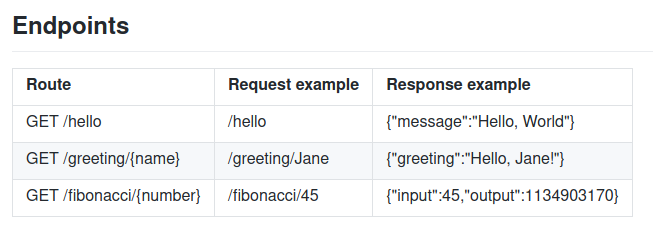
Punkty końcowe obsługiwane przez usługę webową w Javie, Go oraz Rust
Repozytorium znajduje się tutaj.
Rozmiar artefaktu
W przypadku Javy zbudowałem wszystko jako jeden jar za pomocą wtyczki maven-shade-plugin i zastosowałem mvn packagetarget. W przypadku Go użyłem go build, a dla Rust zastosowałem cargo build --release.
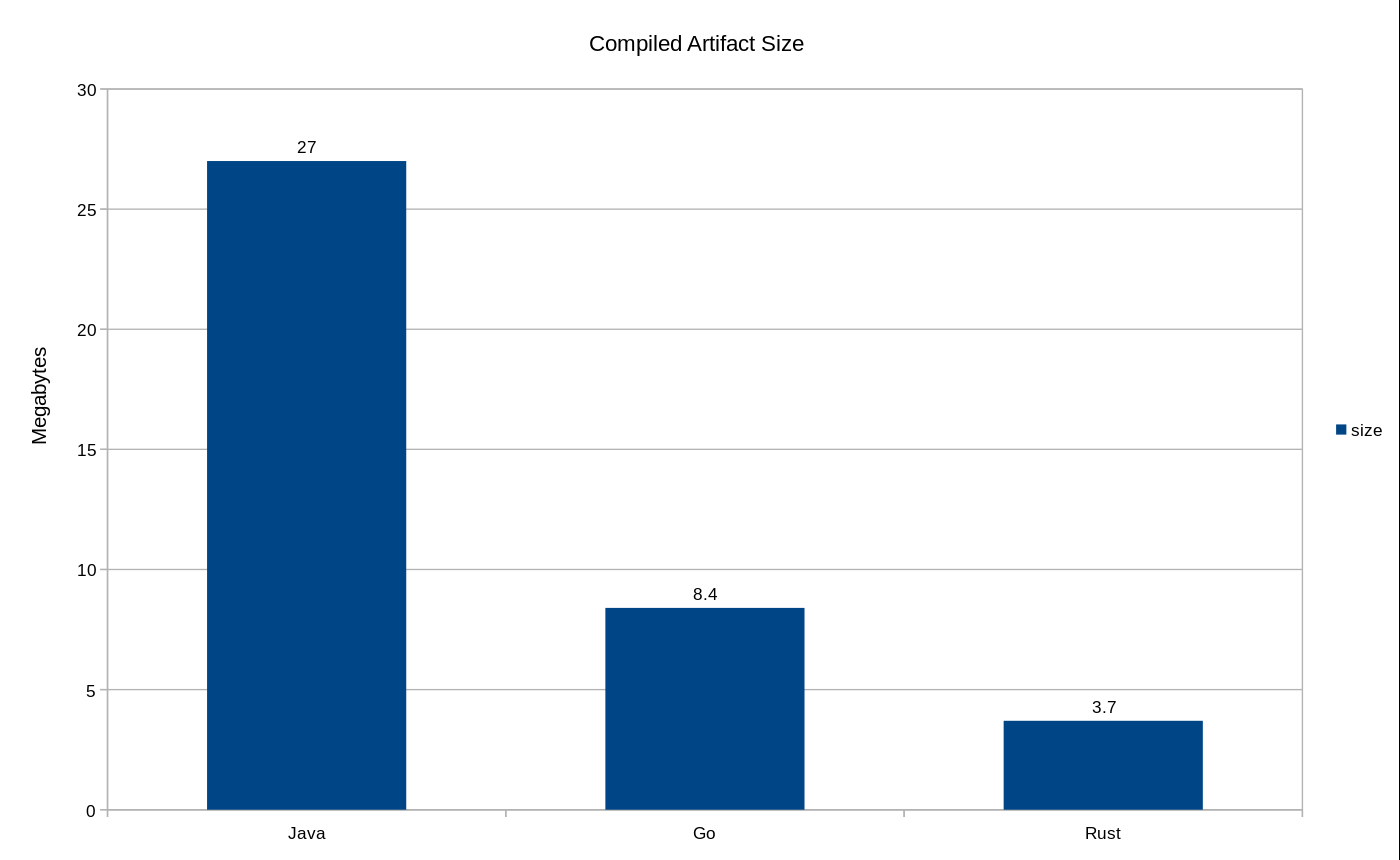 Skompilowany rozmiar każdego programu w megabajtach
Skompilowany rozmiar każdego programu w megabajtach
Rozmiar skompilowanego artefaktu zależy również od wybranych bibliotek/zależności, więc jeśli są one rozdęte, to taki będzie też Twój program. W moim przypadku, dla bibliotek, które wybrałem, rozmiar skompilowanych programów znajduje się powyżej. Zbuduję też i spakuję wszystkie trzy programy jako obrazy Dockera, a także podzielę się ich rozmiarami, aby pokazać narzut związany z uruchomieniem każdego z tych języków. Więcej szczegółów poniżej.
Zużycie pamięci
Na biegu jałowym
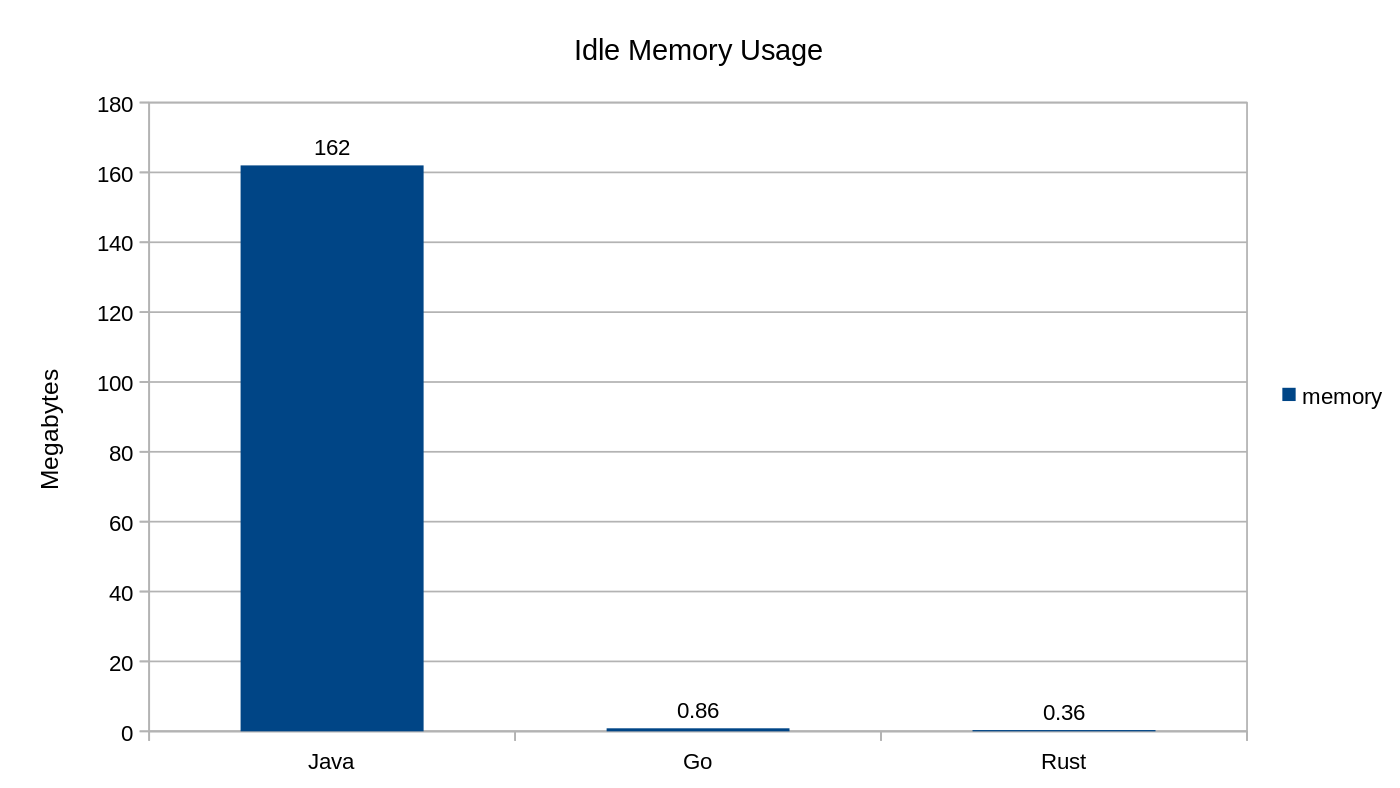 Zużycie pamięci każdej aplikacji podczas bezczynnego działania
Zużycie pamięci każdej aplikacji podczas bezczynnego działania
Gdzie się podziały paski dla wersji Go i Rust, które pokazują ślad pamięci podczas pracy w trybie bezczynności? Otóż nigdzie nie zniknęły, tyle że Java zużywa 160 MB więcej, gdy JVM uruchamia program i siedzi bezczynnie. W przypadku Go program wykorzystuje 0,86 MB, a w przypadku Rust 0,36 MB. To spora różnica! Java wykorzystuje tutaj o dwa rzędy wielkości więcej pamięci niż odpowiedniki w Go i Rust na biegu jałowym. To ogromne marnotrawstwo zasobów.
Obsługa żądań REST
Zarzućmy nasze API żądaniami przy użyciu wrk. Obserwujemy zużycie pamięci oraz procesora wraz z liczbą żądań na sekundę osiągniętych na moim komputerze dla każdego punktu końcowego trzech wersji programu.
wrk -t2 -c400 -d30s http://127.0.0.1:8080/hello
wrk -t2 -c400 -d30s http://127.0.0.1:8080/greeting/Jane
wrk -t2 -c400 -d30s http://127.0.0.1:8080/fibonacci/35
Oto, co mówią powyższe polecenia wrk: używaj dwóch wątków (dla wrk), utrzymuj 400 otwartych połączeń w puli i wywołuj punkt końcowy GET ciągle przez 30 sekund. Używam tutaj tylko dwóch wątków, ponieważ zarówno wrk, jak i testowany program, działają na tej samej maszynie. Nie chcę zatem, aby za bardzo konkurowały ze sobąo dostępne zasoby, a zwłaszcza o procesor.
Każda usługa webowa była testowana osobno i restartowana między każdym uruchomieniem. Poniżej przedstawiono najlepszy wynik z serii trzech uruchomień dla każdej wersji programu.
/hello
Endpoint ten zwraca wiadomość Hello, World!, alokuje ciąg znaków „Hello, World!” oraz serializuje i zwraca go w JSON-ie.
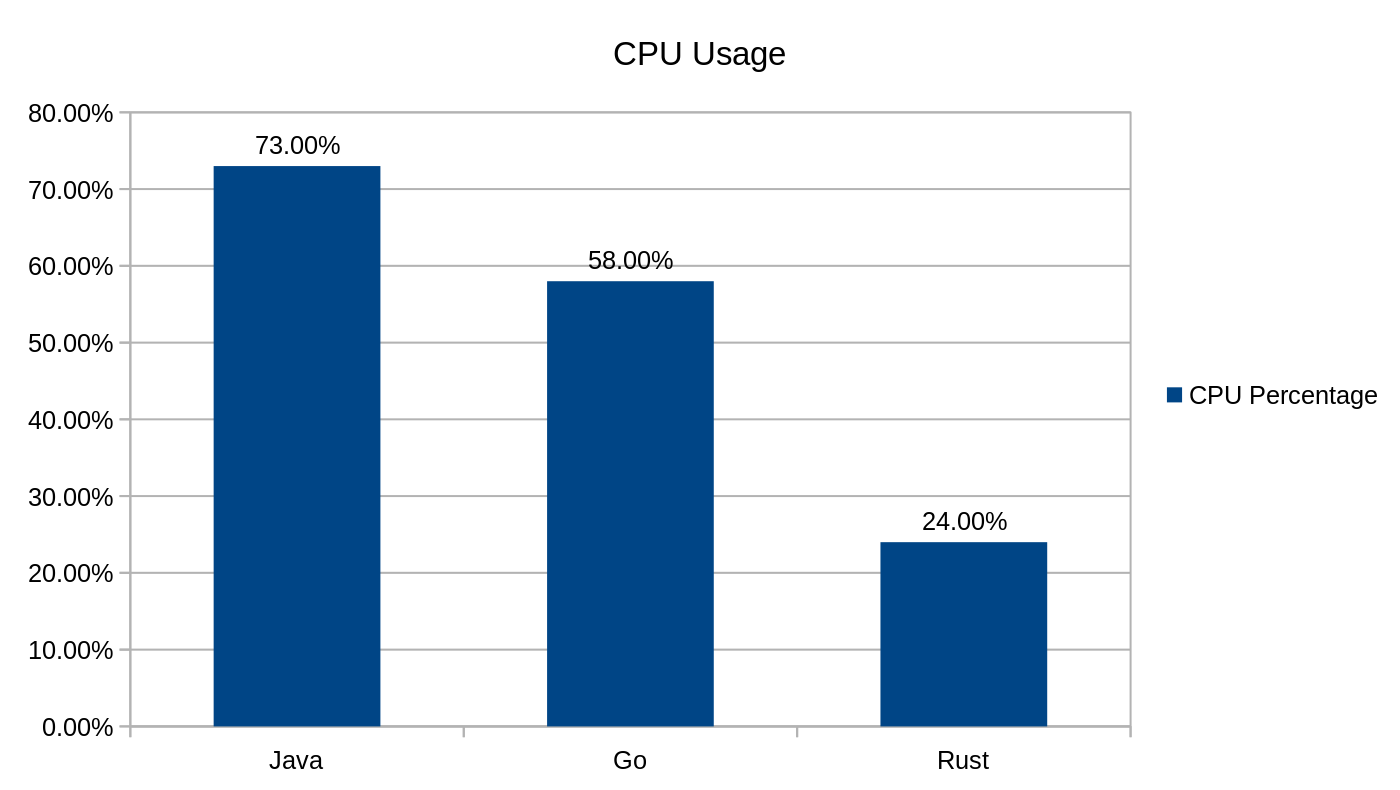 Zużycie procesora podczas użycia punktu końcowego /hello
Zużycie procesora podczas użycia punktu końcowego /hello
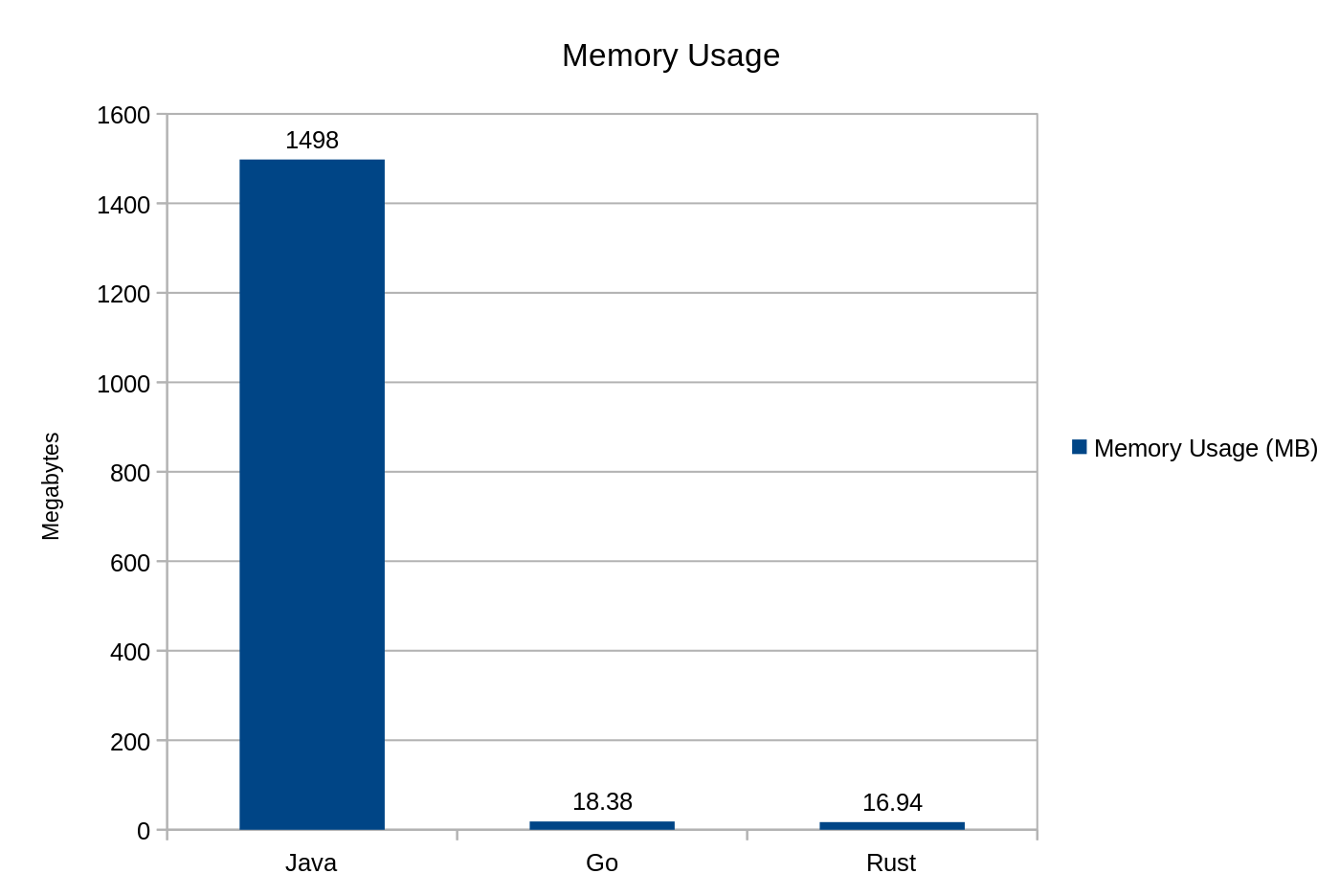 Zużycie pamięci podczas użycia punktu końcowego /hello
Zużycie pamięci podczas użycia punktu końcowego /hello
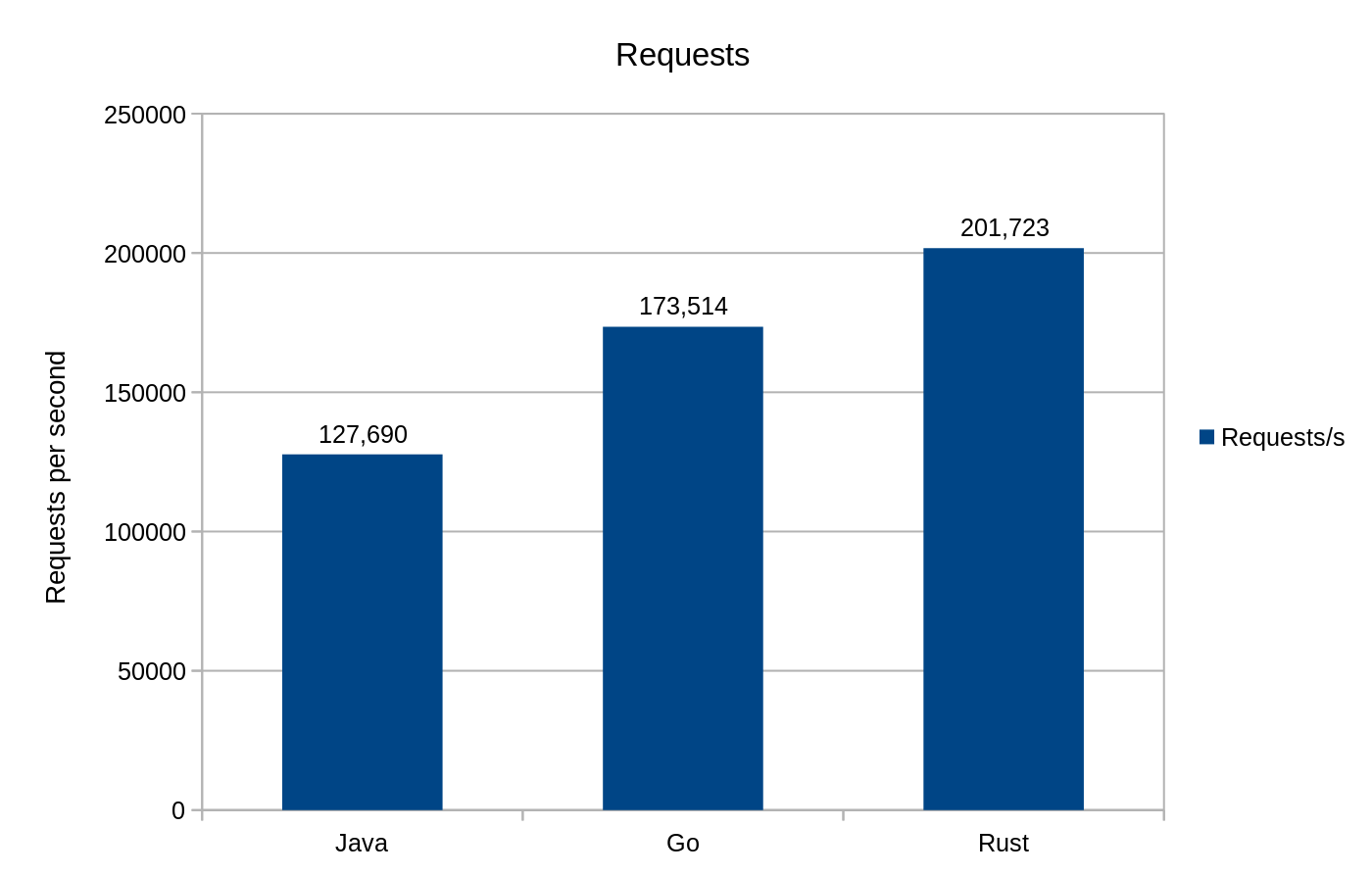 Żądania na sekundę podczas używania punktu końcowego /hello
Żądania na sekundę podczas używania punktu końcowego /hello
/greeting/{name}
Ten punkt końcowy akceptuje parametr w segmencie {name} ścieżki, a następnie formatuje ciąg znaków „Hello, {name}!”. Podobnie jak wcześniej, serializuje wiadomość i zwraca ją w JSON-ie.
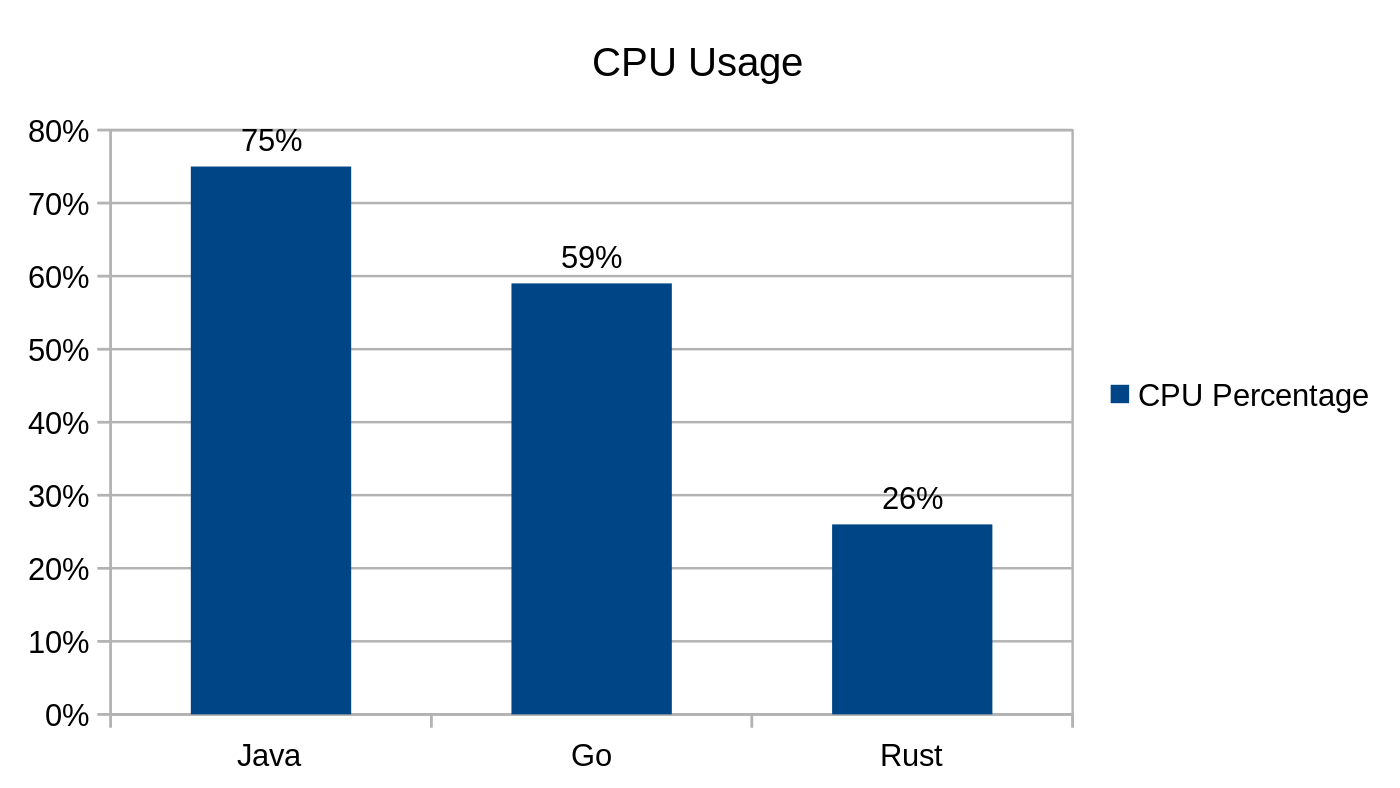 Zużycie procesora podczas użycia punktu końcowego /greeting
Zużycie procesora podczas użycia punktu końcowego /greeting
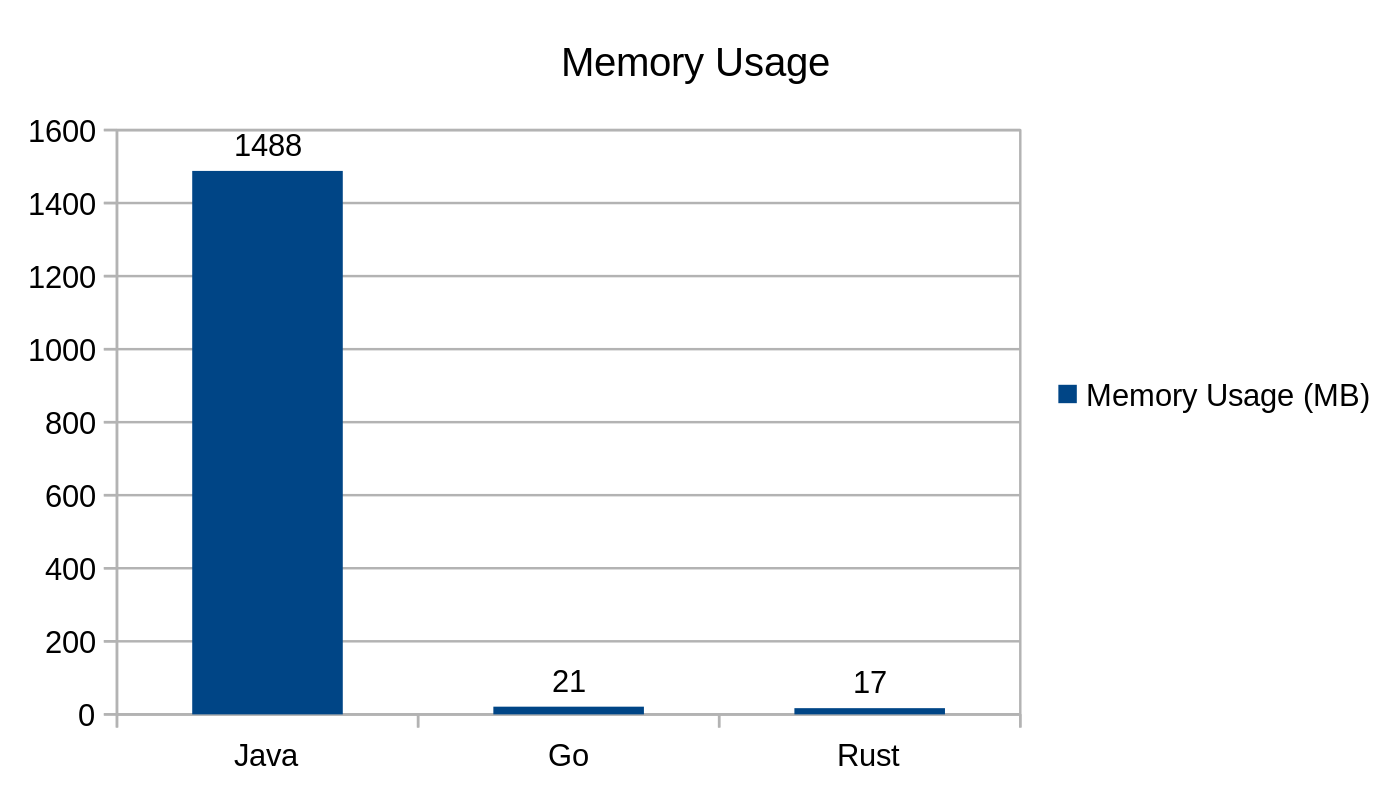 Zużycie pamięci podczas użycia punktu końcowego /greeting
Zużycie pamięci podczas użycia punktu końcowego /greeting
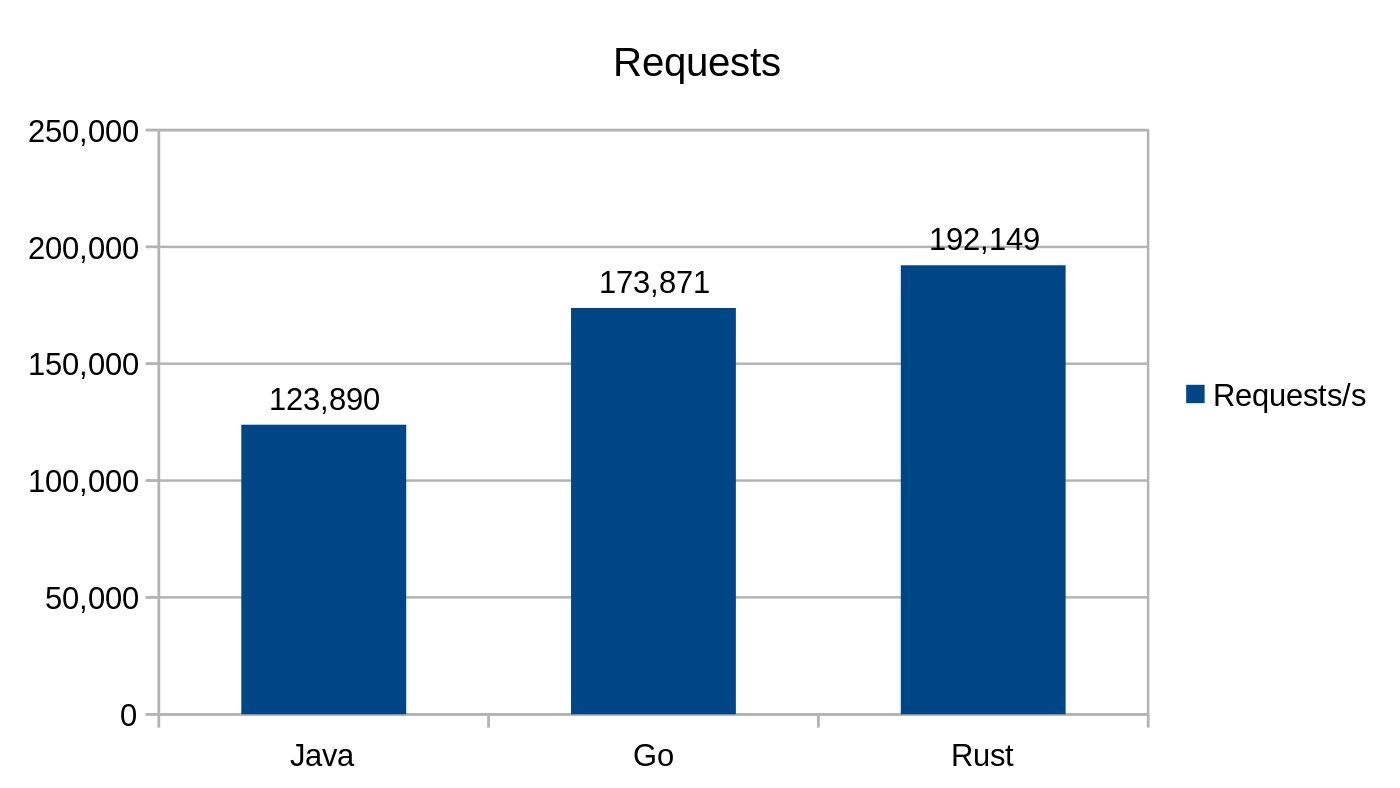 Żądania na sekundę podczas używania punktu końcowego /greeting
Żądania na sekundę podczas używania punktu końcowego /greeting
/fibonacci/{number}
Ten punkt końcowy akceptuje w ścieżce parametr {number} i zwraca w JSON-ie liczbę wejściową oraz wyliczoną liczbę Fibonacciego.
Zdecydowałem, że użyję tu rekurencji. Wiem, że implementacja iteracyjna byłaby znacznie bardziej wydajna i tego należałoby się trzymać w produkcyjnych zastosowaniach, zdarza się jednak, że rekurencja występuje w produkcyjnym kodzie (i to niekoniecznie do obliczania liczb Fibonacciego). Dlatego chciałem, aby implementacja mocno obciążała procesor.
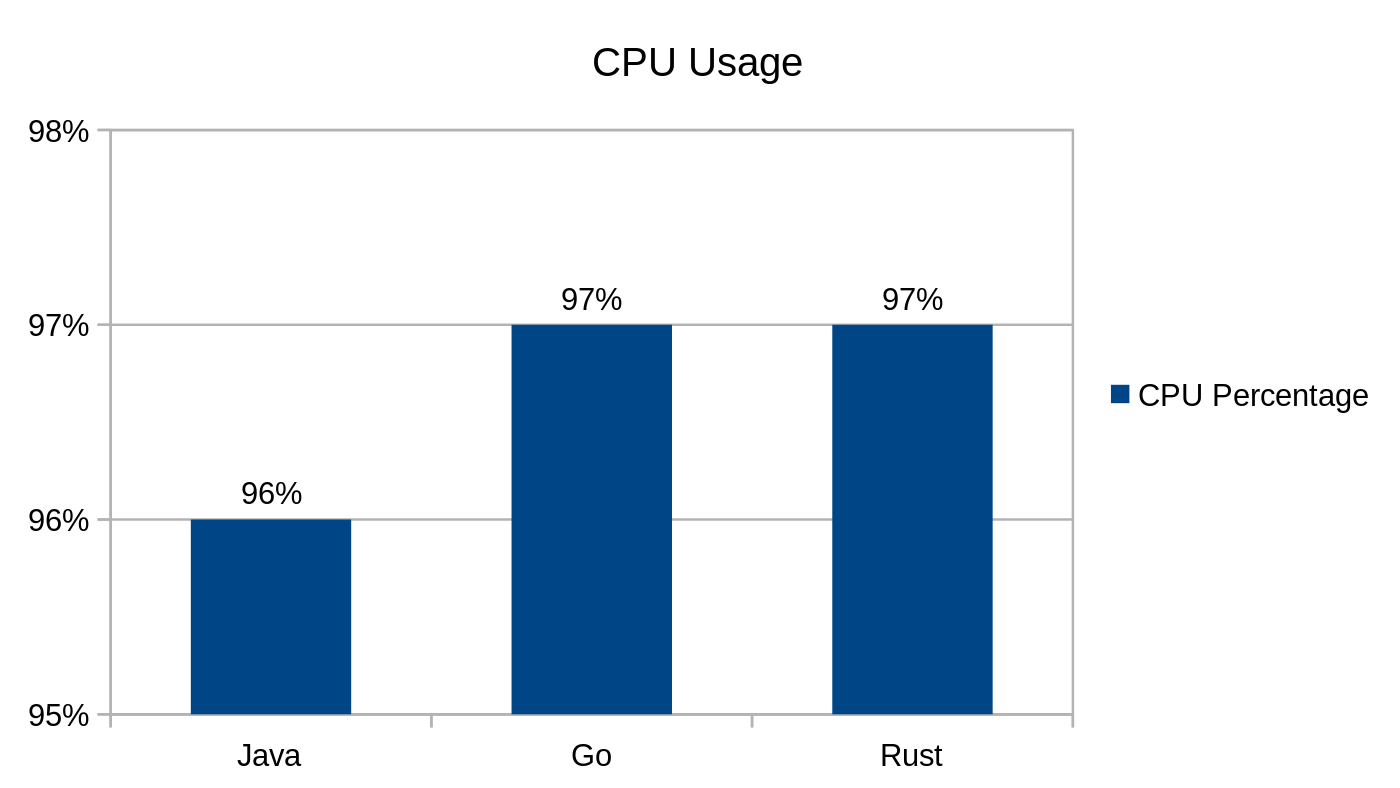 Zużycie procesora podczas użycia punktu końcowego /fibonacci
Zużycie procesora podczas użycia punktu końcowego /fibonacci
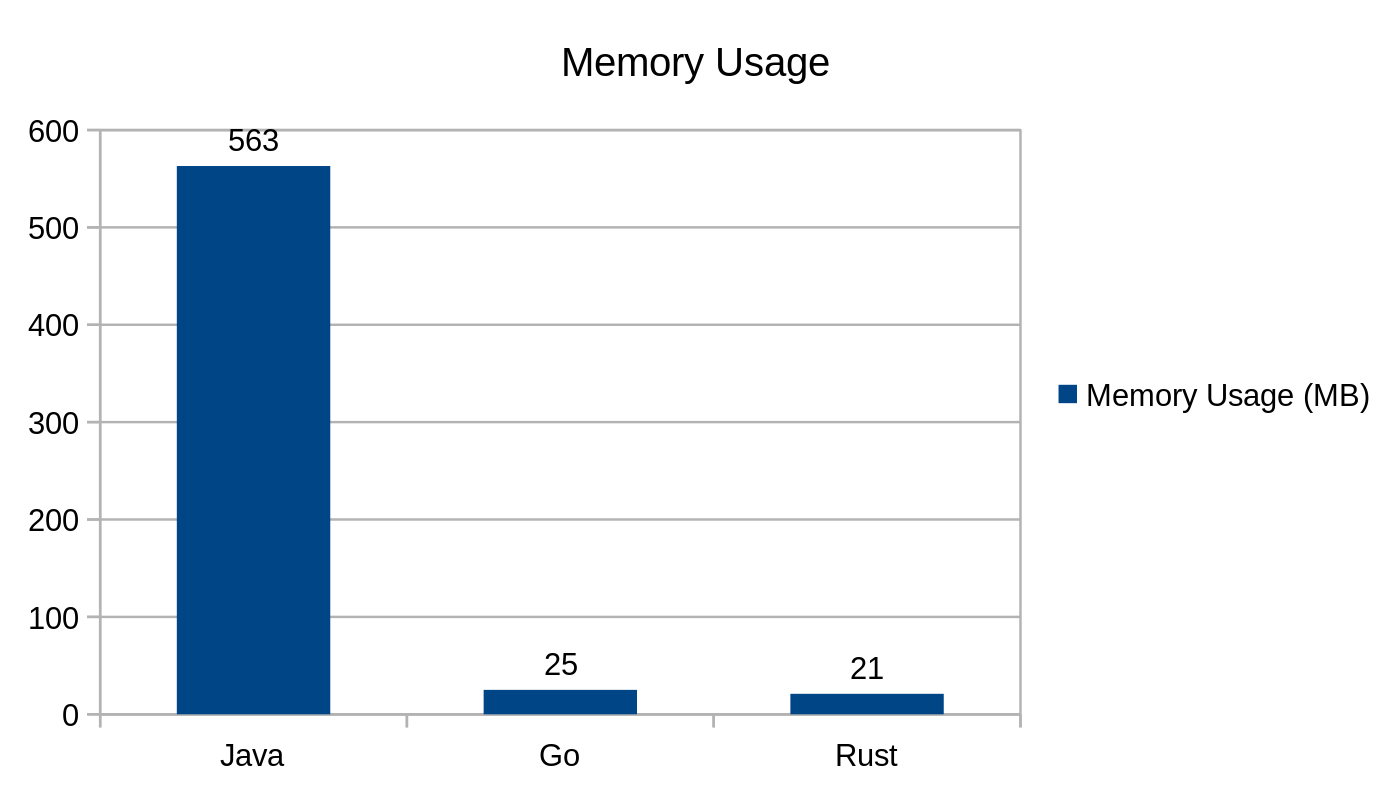 Zużycie pamięci podczas użycia punktu końcowego /fibonacci
Zużycie pamięci podczas użycia punktu końcowego /fibonacci
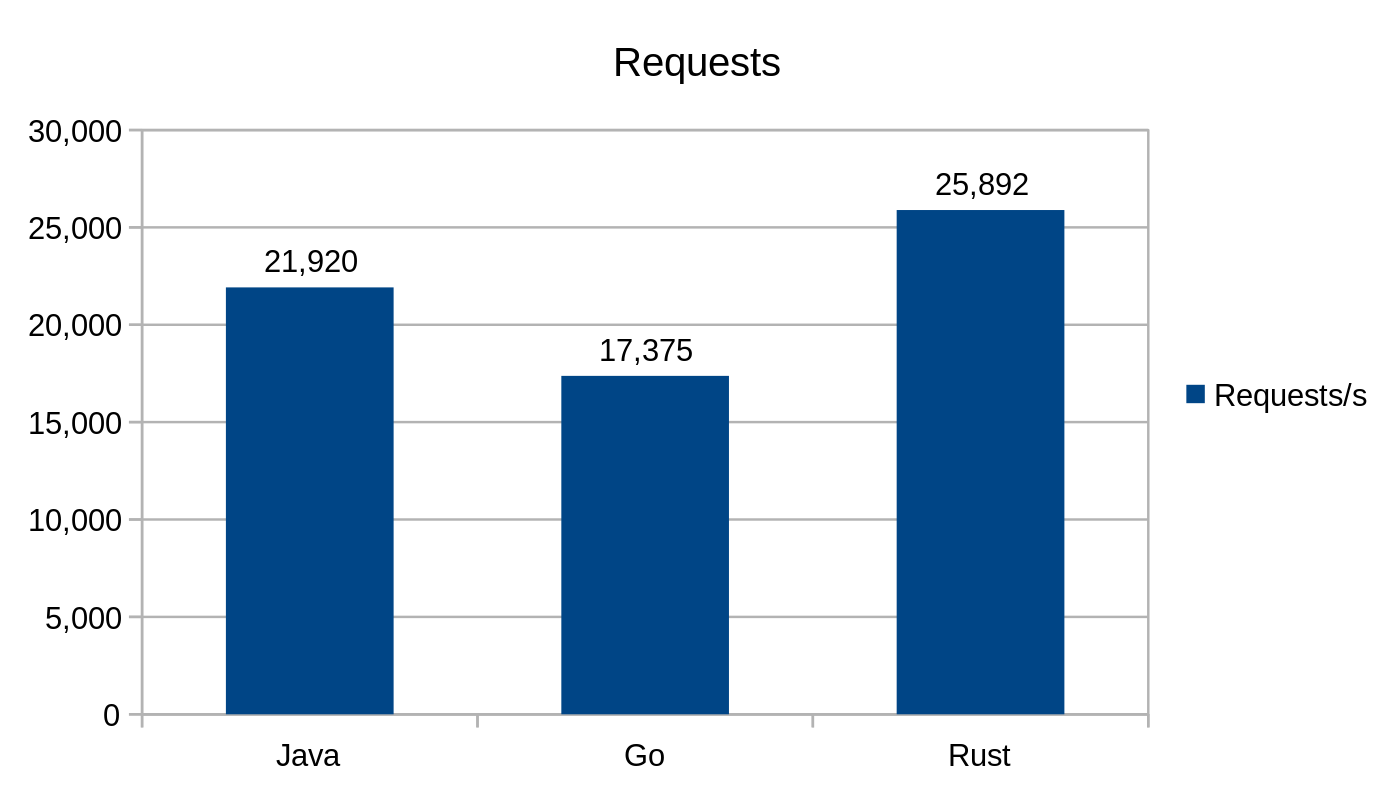 Żądania na sekundę podczas użycia punktu końcowego /fibonacci
Żądania na sekundę podczas użycia punktu końcowego /fibonacci
Podczas testu punktu końcowego Fibonacciego, implementacja Javy była jedyną, która przekroczyła limit czasu żądania (i to 150 razy), co widać na danych z wrk.
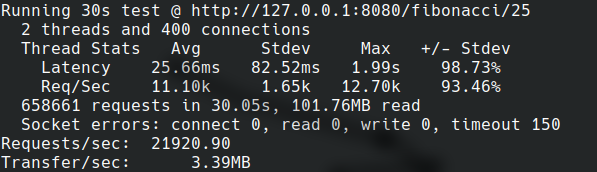
Przekroczenie limitu czasu żądania
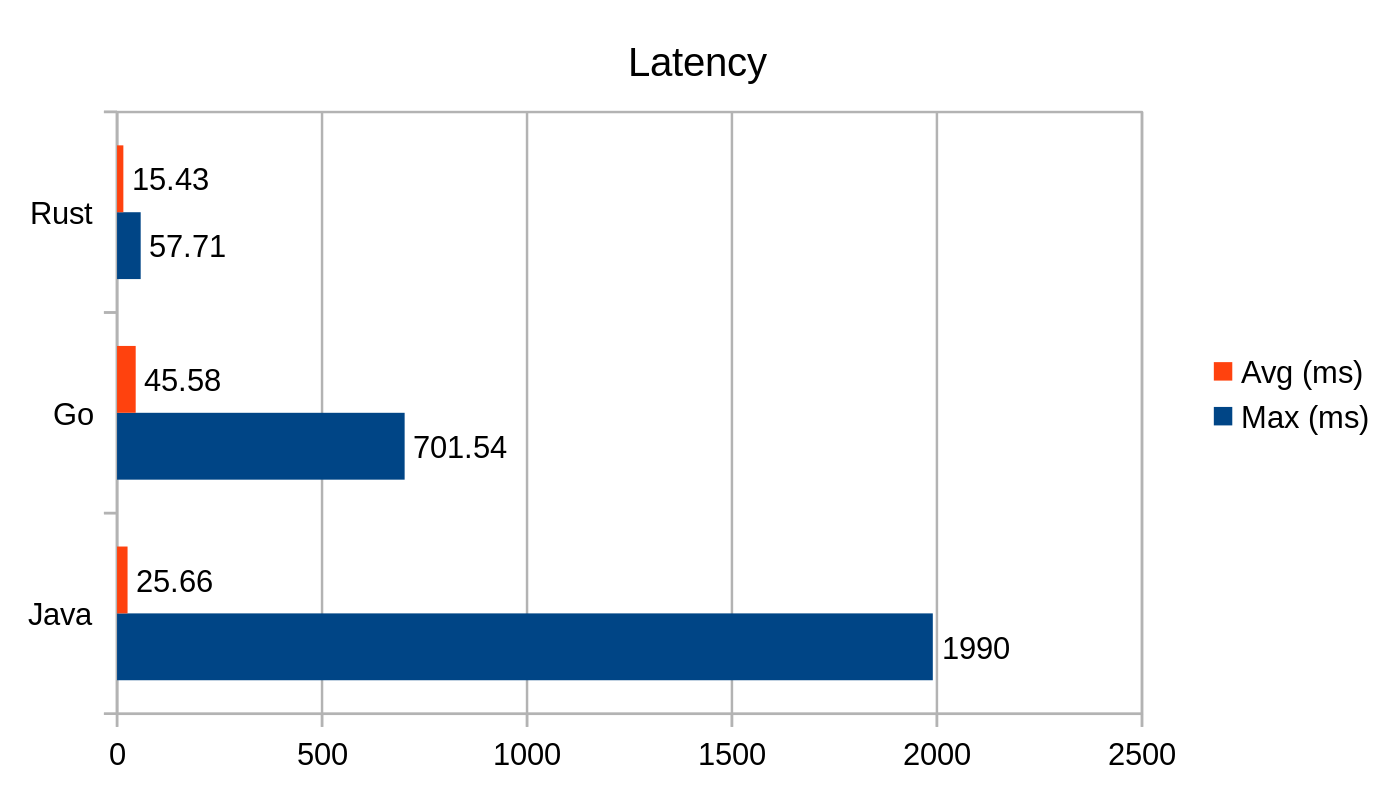 Latencja punktu końcowego /fibonacci
Latencja punktu końcowego /fibonacci
Rozmiar środowiska wykonawczego
Aby naśladować natywną aplikację chmury w świecie rzeczywistym i uniknąć „to działa na moim komputerze!”, stworzyłem obraz Dockera dla każdej z trzech aplikacji. Źródło plików Dockera znajduje się w repozytorium w folderze odpowiedniego programu.
Jako podstawowy obraz środowiska wykonawczego dla aplikacji Java, użyłem openjdk: 8-jre-alpine, który jest znany jako jeden z najmniejszych obrazów pod względem wielkości. Ma on jednak kilka wad, które mogą, ale nie muszą dotyczyć Twojej aplikacji - głównie chodzi tutaj o obraz alpine, który nie jest zgodny z posix pod względem obsługi nazw zmiennych środowiskowych, więc nie można używać znaku . (kropka) w ENV w pliku dockera (chociaż to nic takiego).
Inną wadą może być to, że obraz alpine Linuksa jest kompilowany z musl libc, a nie glibc. Oznacza to, że jeśli Twoja aplikacja zależy od czegoś, co wymaga obecności glibc (lub temu podobnych), to po prostu nie zadziała. W moim przypadku alpine działa dobrze.
Jeśli chodzi zarówno o wersję napisaną w Go, jak i Rust, to skompilowałem je statycznie, co oznacza, że nie spodziewają się obecności biblioteki libc (glibc, musl… itp.) w obrazie środowiska wykonawczego. Oznacza to również, że nie potrzebują obrazu bazowego z systemem operacyjnym do uruchomienia.
Użyłem więc obrazu Dockera scratch, który jest pustym obrazem, dzięki czemu nie ma narzutu przy uruchamianiu pliku wykonywalnego. Konwencja nazewnictwa dla obrazów Dockera, której użyłem, to {lang}/webservice. Rozmiar obrazu dla aplikacji Java, Go i Rust wynosi odpowiednio 113, 8,68 oraz 4,24 MB.
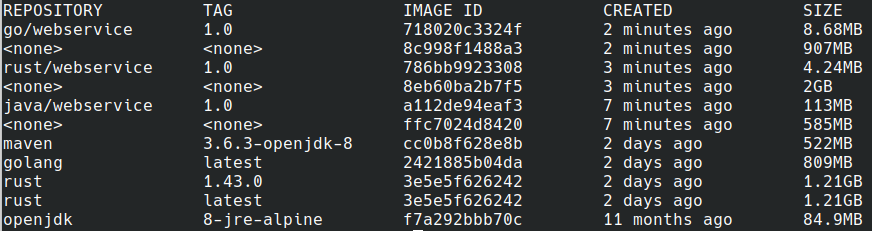
Finalne rozmiary obrazów Dockera
Podsumowanie
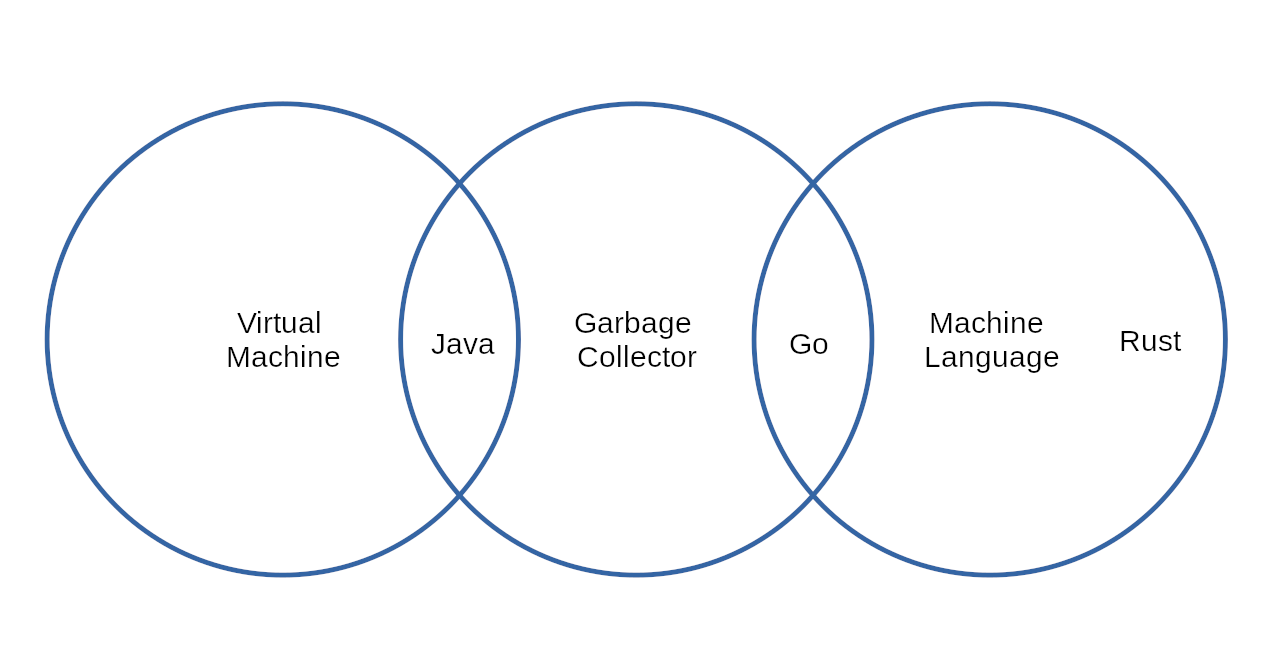 Porównanie Java, Go oraz Rust
Porównanie Java, Go oraz Rust
Przed wyciągnięciem jakichkolwiek wniosków chciałbym zwrócić uwagę na związek (lub jego brak) między tymi trzema językami. Zarówno Java, jak i Go, to języki używające garbage collectora, jednak Java jest kompilowana z wyprzedzeniem (ang. ahead-of-time lub AOT) do kodu bajtowego działającego w wirtualnej maszynie Javy (JVM). Po uruchomieniu aplikacji Javy wywoływany jest kompilator Just-In-Time (JIT). Dzieje się to, ponieważ chcemy zoptymalizować kod bajtowy poprzez kompilację go do kodu natywnego w dowolnym miejscu i czasie, aby zwiększyć wydajność aplikacji.
Zarówno Go, jak i Rust, są kompilowane do kodu natywnego z wyprzedzeniem i nie jest wymagana dalsza optymalizacja w czasie wykonywania. Zarówno Java, jak i Go, to języki z odśmiecaniem pamięci i efektem ubocznym stop-the-world. Oznacza to, że za każdym razem, gdy garbage collector działa, to zatrzyma aplikację, wykona czyszczenie pamięci, a po zakończeniu wznowi aplikację od miejsca, w którym została ona przerwana.
Większość garbage collectorów musi zatrzymywać działanie aplikacji (stop the world), jednak niektóre implementacje tego nie wymagają. Kiedy Java została utworzona w latach 90., jednym z jej największych atrybutów było "Write once, Run anywhere" (co oznacza napisz raz i odpalaj gdzie chcesz). Super, jak na tamte czasy, ponieważ na rynku nie było wtedy wielu rozwiązań do wirtualizacji.
Obecnie większość procesorów obsługuje wirtualizację, co sprawia, że wybieranie języka tylko dlatego, że wspiera on wiele platform, nie jest już tak kuszące (w każdym razie na dowolnej obsługiwanej platformie). Docker i inne rozwiązania oferują wirtualizację za niską cenę. Podczas testów wersja aplikacji w Javie zużywała więcej pamięci niż odpowiedniki Go lub Rust. W pierwszych testach Java zużywała o 8000% więcej pamięci. Oznacza to, że w przypadku aplikacji w świecie rzeczywistym koszty hostowania Javy będą wyższe.
W pierwszych dwóch testach aplikacja Go zużywała około 20% mniej procesora niż Java, obsługując przy tym 38% więcej żądań. Z drugiej strony wersja Rust zużywała 57% mniej procesora niż Go, a jednocześnie obsługiwała 13% więcej żądań. Trzeci test z założenia wymaga dużej mocy obliczeniowej, więc chciałem wycisnąć z niego tyle, ile mogłem. Zarówno Go, jak i Rust, zużywały 1% procesora więcej niż Java. I myślę, że gdyby wrk nie działał na tym samym komputerze, wszystkie trzy wersje ograniczałyby procesor, wysycony w 100%.
Jeśli chodzi o pamięć, Java zużywała ponad 2000% więcej pamięci niż Go i Rust. Java była jednak w stanie obsłużyć około 20% więcej żądań niż Go, a Rust obsłużył około 15% więcej żądań niż Java. W momencie pisania tego artykułu Java istniała już prawie trzy dekady, co sprawia, że stosunkowo łatwo jest znaleźć na rynku “jej” programistów.
Z drugiej strony zarówno Go, jak i Rust są względnie nowymi językami, więc naturalnie liczba programistów będzie mniejsza. Zarówno Go, jak i Rust, zyskują jednak na popularności, a wielu programistów używa ich w nowych projektach. Produkcyjnie działa już wiele projektów korzystających z Go i Rust, ponieważ są one bardziej wydajne niż Java pod względem potrzeby zużycia zasobów.
Przygotowując się do napisania tego artykułu, uczyłem się zarówno Go, jak i Rusta. W moim przypadku krzywa uczenia się dla Go była krótka, ponieważ jest to język łatwy do opanowania, a jego składnia nie jest rozbudowana. Napisanie programu w Go zajęło mi tylko kilka dni. Należy tutaj zwrócić uwagę na szybkość kompilacji Go. Muszę przyznać, że jest ona szybsza w porównaniu do innych języków, takich jak Java, C, C++, czy Rust.
Wersja programu napisana w Rust zajęła mi około tygodnia i muszę powiedzieć, że większość tego czasu spędziłem na zastanawianiu się, czego chce ode mnie borrow checker. Rust ma ścisłe reguły własności, ale gdy tylko zrozumie się pojęcia własności i pożyczania w Rust, komunikaty o błędach kompilatora będą miały o wiele więcej sensu. Powodem, dla którego kompilator Rust się denerwuje, gdy zasady borrow checkera są naruszane, jest to, że kompilator chce udowodnić w momencie kompilacji, że nie będzie problemów z naruszeniem własności przydzielonej pamięci.
W ten sposób gwarantuje bezpieczeństwo programu (np. brak zwisających wskaźników, chyba że chodzi o kod oznaczony jako unsafe), a dealokacja jest określana w czasie kompilacji, eliminując w ten sposób potrzebę korzystania z garbage collectora i koszty z tym związane. By to wszystko pogodzić, trzeba nauczyć się systemu własności Rusta. Jeśli chodzi o konkurencję, moim zdaniem Go jest bezpośrednim konkurentem dla Javy (i ogólnie dla języków JVM), ale nie dla Rust. Z drugiej strony Rust jest poważnym konkurentem dla Javy, Go, C oraz C++.
Ze względu na ich wydajność, będę pisał jeszcze więcej programów w Go oraz Rust, ale więcej w Rust. Oba są świetne do tworzenia usług webowych, CLI oraz programów systemowych itp. Rust ma jednak zasadniczą przewagę nad Go - nie jest to język używający garbage collectora, a jego założeniem jest pisanie bezpiecznego kodu (w przeciwieństwie do C i C++).
Na przykład Go nie jest odpowiedni do pisania jądra systemu operacyjnego - tutaj znowu pojawia się Rust, który w tym aspekcie również konkuruje z C oraz C++. Są to już języki wiekowe, ale mimo wszystko przeznaczone de facto do pisania systemów operacyjnych.
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.
