

OLAP w Javie z biblioteką Mondrian
Sprawdź, jak w prosty sposób przedstawić wielowymiarowe dane, korzystając z biblioteki Mondrian, będącej javowym reprezentantem narzędzi typu OLAP.
Wyobraźmy sobie następującą sytuację – zostaliśmy właśnie zatrudnieni jako analitycy luksusowego sklepu z wieloma oddziałami w Polsce. Naszym pierwszym zadaniem jest przedstawić jaki odsetek odwiedzających oddziały naszej firmy to kupujący, z podziałem na dni.
Jednak w sercu jesteśmy programistami. Mimo że znamy SQL-a, to nie marzy nam się tworzenie skomplikowanych zapytań oraz późniejsze kopiowanie rezultatów i ręczne ich formatowanie. Najlepiej oczywiście jakby większość tego zadania wykonała za nas maszyna. Na szczęście, zanim zabraliśmy się za to nieszczęsne zadanie, przypomniał nam się artykuł, który widzieliśmy jakiś czas temu – który mówił coś o przetwarzaniu danych analitycznych.
OLAP
OLAP (skrót z angielskiego On-Line Analytical Processing) to narzędzia służące w większości do analizy trendów. Cechują się tym, że w przeciwieństwie do klasycznych narzędzi (np. wynik zapytania SQL), wyniki pochodzące z tych narzędzi są wielowymiarowe.
Klasyczne struktury znane nam z baz danych są w większości jednowymiarowe, a ich przegląd nie jest najprostszy. W celu analizy danych konieczne okazałoby się pisanie skomplikowanych zapytań do bazy danych – i nawet wtedy rezultaty nie byłyby przyjemne do analizy.
Na ratunek przybywa nam kostka OLAP-owa – podstawowa struktura danych w systemach OLAP. Normalnie, gdy myślimy o kostce, przychodzi nam na myśl struktura trójwymiarowa. Kostka OLAP-owa może jednak posiadać praktycznie dowolną liczbę wymiarów. Tymi wymiarami kostki mogą być różne rzeczy, przykładowo:
- dzień tygodnia
- oddziały firmy
- produkty
Drugą rzeczą znajdującą się w kostce są miary, którymi mogą być np.:
- liczba dostarczonych sztuk (jakiegoś produktu)
- liczba uszkodzonych sztuk
- liczba sprzedanych sztuk
Te miary nie muszą być agregowane sumą – mogą być również wartościami minimalnymi, średnimi czy maksymalnymi.
Jednym z bardziej popularnych typów narzędzii OLAP jest ROLAP – szczególna wersja OLAP, działająca na klasycznej, relacyjnej bazie danych, którą prawdopodobnie już w tym momencie posiadamy. Nie musimy zatem inwestować w nowe skomplikowane narzędzia do przechowywania danych.
Niektórzy uważają, że narzędzia ROLAP są znacznie wolniejsze od innych typów. Jest to jednak prawdopodobnie związane z tym, że przypadki, do których stosuje się narzędzia ROLAP, to te, gdzie istnieją już duże relacyjne bazy danych. Ich analiza również trwa dłużej niż mniejszych baz, takich, które od początku były tworzone z myślą o analizie OLAP.
Narzędzia
Dalej przedstawię podstawy biblioteki Mondrian oraz powiązaną z nią bibliotekę/standard Olap4j. Do powtórzenia przedstawionych tu wyników potrzebna będzie jeszcze zwykła, relacyjna baza danych oraz ulubione javowe środowisko.
Konfiguracja projektu
Mondriana możemy pobrać w najprostszy sposób z repozytorium za pomocą Mavena albo Gradle. Aby jak najszybciej zacząć pracę, przedstawiłem poniżej fragment Mavenowego pliku POM, z którego możecie skorzystać.
<dependencies>
<dependency>
<groupId>pentaho</groupId>
<artifactId>mondrian</artifactId>
<version>9.2.0.0-6</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>pentaho-releases</id>
<url>https://nexus.pentaho.org/content/groups/omni/</url>
</repository>
</repositories> Struktura bazy danych
Również dla przykładu przygotowałem prostą bazę danych, na której będzie bazowana reszta artykułu. Składa się ona z trzech tabel:
- department
- id
- name
- city
- visits
- id
- department_id
- day
- visitors
- sales
- id
- department_id
- client_surname
- seller_surname
- day
Dane są dostępne pod tym linkiem (przygotowane z myślą o bazie danych PostgreSQL). Nie jest to idealnie zaprojektowana baza, ale akurat taka przyda nam się do przykładu.
Jak korzystać z Mondriana?
Gdy mamy już gotowy szablon projektu oraz bazę danych, pozostają nam trzy główne elementy:
- kod programu w Javie
- schemat Mondrianowy
- zapytanie MDX
Rozwiążmy te sprawy po kolei.
Kod programu
Jeżeli chcielibyśmy uzyskać więcej niż proste wypisanie wyników, konieczne byłoby przeczytanie dokumentacji Olap4j - standardu oraz biblioteki skupionej na interfejsie, który jest implementowany przez Mondriana. Ten temat nie jest jednak poruszony w ramach tego wpisu.
Fragment specyfikacji, który wykorzystamy, silnie wzoruje się na rozwiązaniach znanych już z JDBC, tak więc osoby, które korzystały z tego API, powinny bez problemu rozpoznać analogie.
Pierwszym krokiem jest uzyskanie połączenia do bazy danych, poprzez Mondriana. Podobnie jak w wypadku JDBC, połączenie uzyskujemy za pomocą metody getConnection klasy DriverManager:
Connection connection = DriverManager.getConnection(
"jdbc:mondrian:"
+ "JdbcDrivers=" + driver + ";"
+ "Jdbc=" + jdbcString + ";"
+ "Catalog=" + catalog + ";"
+ "JdbcUser=" + username + ";"
+ "JdbcPassword=" + password + ";"
+ "PoolNeeded=true;" );
Teraz czas na szybkie wyjaśnienie każdej stałej, którą będziemy musieli przygotować:
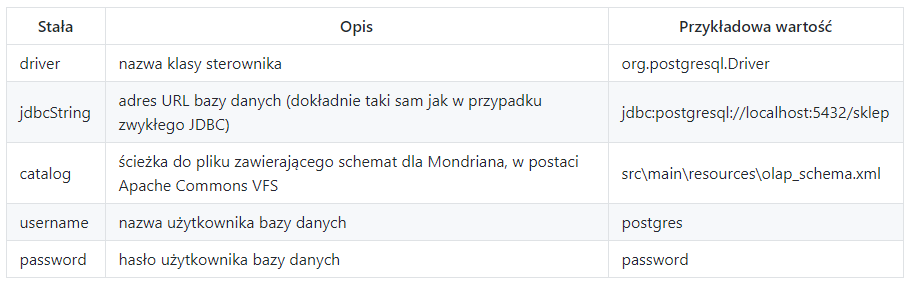
Następnie z obiektu typu Connection, który uzyskaliśmy w poprzednim kroku, konieczne jest uzyskanie obiektu typu OlapConnection:
OlapWrapper wrapper = (OlapWrapper) connection; OlapConnection olapConnection = wrapper.unwrap(OlapConnection.class);
po tym kroku możemy już wykonać nasze zapytanie, jednak jeszcze go nie przygotowaliśmy - to zrobimy dopiero później:
CellSet cellSet = olapConnection.createStatement().executeOlapQuery(
"ZAPYTANIE_MDX"
);
ze względu na to że chcemy uzyskać wynik w konsoli, możemy skorzystać z gotowego już narzędzia zawartego w bibliotece Olap4j:
PrintWriter pw = new PrintWriter(System.out); new RectangularCellSetFormatter(false).format(cellSet, pw); pw.flush();
W tym momencie stronę programistyczną mamy ukończoną. Jeżeli wstawiliśmy wszystkie dane bezbłędnie, to po utworzeniu schematu oraz zapytania, powinniśmy dostać wynik.
Schemat mondrianowy
Mondrian korzysta z plików schematów w celu zdefiniowania struktury kostek oraz relacji pomiędzy relacyjną bazą danych, a tymi kostkami. Pliki te są w formacie XML.
Najczęściej spotykanymi elementami w schemacie są wymiary (<Dimension>) oraz kostki (<Cube>).
Wszystkie elementy znajdują się pomiędzy znacznikami Schema:
<Schema name="Schema">
...
</Schema>
W pierwszym kroku warto zdecydować, co powinno być naszymi wymiarami. W naszym wypadku na pewno możemy wziąć pod uwagę poniższe wymiary:
- data
- miasto
- nazwa oddziału
- nazwiska sprzedających
Spróbujmy więc je zdefiniować.
Data
Jako że musimy znaleźć wszystkie dane w systemie, to nie możemy się opierać tylko na jednej tabeli jako źródle dat. Musimy najpierw znaleźć polecenie SQL, które pozwoli nam uzyskać wszystkie daty w systemie.
Zapytanie:
select distinct day from sales
union
select distinct day from visits;
pozwoli nam właśnie to osiągnąć. Oczywiście nasza baza danych to prosty przypadek – tutaj nie byłoby problemu z korzystaniem z dat tylko z jednej tabeli.
Teraz możemy wykorzystać to zapytanie do skonstruowania pierwszego wymiaru:
<Dimension name="Date">
<Hierarchy hasAll="false" primaryKey="day">
<View alias="Date_alias">
<SQL dialect="generic">
<![CDATA[
select distinct day from sales
union
select distinct day from visits
]]>
</SQL>
</View>
<Level name="Date" column="day"/>
</Hierarchy>
</Dimension>
W ten sposób zdefiniowaliśmy wymiar Date, z kluczem głównym day. Gdy będziemy definiowali kostkę, to właśnie za pomocą klucza głównego kostka będzie połączona z wymiarem.
Kolejną rzeczą, którą musimy zdefiniować, jest źródło danych – tabela lub "widok" (nie w sensie bazodanowym!) w postaci zapytania SQL. Warto zwrócić uwagę na to, że widoki muszą mieć różne nazwy. Zostaną one wykorzystane w końcowym zapytaniu SQL, wygenerowanym przez Mondriana.
Sekcja <![CDATA[ ... ]]> to specjalna sekcja w dokumentach XML, w której znajdują się dane tekstowe, interpretowane dosłownie. To właśnie w niej zawieramy zapytanie SQL, tworzące mondrianowy widok.
Ostatnią rzeczą, która jest zdefiniowana, to poziom. Każdy wymiar może mieć wiele poziomów, jednakże w tym przypadku jest to tylko jeden poziom – oparty na tej samej kolumnie, co klucz główny.
Nazwiska sprzedających
Rozwiązanie z nazwiskami jest analogiczne i nawet prostsze niż daty, ponieważ nazwiska sprzedających znajdują się w jednej tabeli. To pozwala nam na skorzystanie z <Table> zamiast z <View>. Powstaje nam więc poniższa definicja:
<Dimension name="Seller">
<Hierarchy hasAll="false" primaryKey="seller_surname">
<Table name="sales"/>
<Level name="Surname" column="seller_surname"/>
</Hierarchy>
</Dimension>
Miasta i oddziały
Jako że miasta i oddziały są ze sobą powiązane, mogą być zaprezentowane na wspólnej hierarchii:
<Dimension name="Department">
<Hierarchy hasAll="false" primaryKey="id">
<Table name="department"/>
<Level name="City" column="city"/>
<Level name="Department" column="name"/>
</Hierarchy>
</Dimension>
Tutaj również skorzystaliśmy z tylko jednej tabeli. Należy zwrócić uwagę na kolejność – w ramach jednego miasta możemy mieć wiele oddziałów, ale każdy z tych oddziałów jest powiązany tylko z jednym miastem – dlatego miasto pojawia się w definicji przed oddziałem.
Kolejna, niewielka różnica w tym przykładzie, to klucz główny, który nie jest związany z żadnym z poziomów – chociaż mógłby w naszym prostym przypadku wynikać z nazw oddziałów, które są unikalne.
W drugim kroku konieczne jest zdefiniowanie samych kostek, powiązanych zazwyczaj ściśle z daną tabelą – chociaż również i w tym przypadku możemy zdecydować się na zapytania SQL. Zdefiniujemy dwie kostki:
- wizyty
- sprzedaże
Wizyty
W ramach kostki musimy zdefiniować połączenia między wymiarami a kostką oraz zdefiniować miary, które wynikają z danej kostki:
<Cube name="Visits">
<Table name="visits"/>
<DimensionUsage source="Department" name="Department" foreignKey="department_id"/>
<DimensionUsage source="Date" name="Date" foreignKey="day"/>
<Measure name="Visitors count" column="visitors" aggregator="sum"/>
</Cube>
Jak widać, korzystamy z tabeli wizyty. DimensionUsage odnosi się do wymiarów, które zdefiniowaliśmy - source do ich nazwy w reszcie schematu, a name w kostce. To jest również nazwa, z której będziemy później korzystali w zapytaniu MDX.
Naszą miarą w tym wypadku jest liczba odwiedzających – i agregujemy ją według sumy.
Sprzedaże
Ta kostka jest podobna do poprzedniej. Jest jednak tylko jeden problem – nie ma w tym przypadku zbytnio wymiaru liczbowego, który możemy zagregować – jeden wiersz oznacza jedną sprzedaż. Można spróbować rozwiązać na wiele sposobów (np. za pomocą agregacji count). Ja zdecydowałem się dodać kolejne pole o wartości 1 - pozwala nam to użyć wszystkich pozostałych agregacji – min, max, sum, avg.
Skończona kostka wygląda w następujący sposób:
<Cube name="Visits">
<Table name="visits"/>
<DimensionUsage source="Department" name="Department" foreignKey="department_id"/>
<DimensionUsage source="Date" name="Date" foreignKey="day"/>
<Measure name="Visitors count" column="visitors" aggregator="sum"/>
</Cube>
Udało nam się zdefiniować wymiary, kostki oraz ich miary. Możemy teraz za pomocą zapytań otrzymać informacje o jednej z tych kostek, ale przypominając nasze zadanie – chcemy uzyskać stosunek sprzedaży do wizyt. W tym celu zdefiniujemy ostatni element – wirtualną kostkę.
Wirtualna kostka składa się z innych kostek. Pozwoli nam skorzystać z miar obu kostek i dzięki temu znajdziemy również poszukiwany przez nas stosunek sprzedaży do wizyt.
<VirtualCube name="Sales and Visits">
<VirtualCubeDimension name="Department"/>
<VirtualCubeDimension name="Date"/>
<VirtualCubeMeasure cubeName="Sales" name="[Measures].[Sales count]"/>
<VirtualCubeMeasure cubeName="Visits" name="[Measures].[Visitors count]"/>
<CalculatedMember name="Buyers percentage" dimension="Measures">
<Formula>[Measures].[Sales count]/[Measures].[Visitors count]</Formula>
</CalculatedMember>
</VirtualCube>
W ramach wirtualnej kostki musimy zdefiniować wspólne wymiary – te same, z których korzystają podkostki. Reszta elementów jest silnie już powiązana z językiem MDX, jednakże jest to tylko podstawowa składnia. We wszystkich tych przypadkach ograniczamy się do pobrania jednej z wybranych miar – liczby sprzedaży lub odwiedzających.
Zapytanie MDX
Czas na ostatni element układanki – samo zapytanie. Ograniczymy się do podstawowej składni, która pozwoli nam uzyskać wyniki.
Zacznijmy od prostego zapytania, w którym chcemy poznać zawartość wszystkich miar w zależności od oddziału:
select
[Department].Members on 0,
{[Measures].Members, [Measures].[Buyers percentage]} on 1
from [Sales and Visits]
where [Date].Members
Możemy od razu zauważyć silną analogię do języka SQL.
Za pomocą wyrażenia select wybieramy miary i wymiary, które chcemy pokazać oraz osie, na których powinny się te elementy pojawić. Elementy mogą być wybierane krotkami – czasami na jednej z osi chcemy pokazać różne wymiary albo pominąć jakieś elementy. Należy uważać na numerowanie osi – osie powinny mieć kolejne wartości i nie możemy pominąć żadnej z nich.
.Members oznacza wszystkie elementy danego zbioru. Niestety, z jakiegoś powodu do tych zbiorów nie są wliczani wyliczeni członkowie (CalculatedMember), w związku z tym, na osi o indeksie 1 dodana jest miara Buyers percentage.
from wskazuje w tym wypadku na kostkę, z której będziemy korzystać. Możemy jednak podobnie jak w przypadku SQL-a skorzystać z podzapytania.
where określa relacje na innych wymiarach kostki – na co trzeba uważać. Jeżeli zapomnimy o tym elemencie, to Mondrian założy, że chcemy ograniczyć dane tylko do pierwszego członka każdego wymiaru.
Po złączeniu wszystkich części w całość otrzymujemy następujący wynik:
| | Gdańsk | Kraków | Warszawa |
| | | BKDS Gdansk | | BKDS Cracow | BKDS Cracow 2 | | BKDS Warsaw | BKDS Warsaw 2 | BKDS Warsaw 3 |
+-------------------+--------+-------------+--------+-------------+---------------+----------+-------------+---------------+---------------+
| Sales count | 6 | 6 | 10 | 7 | 3 | 14 | 4 | 4 | 6 |
| Visitors count | 41 | 41 | 63 | 37 | 26 | 130 | 46 | 32 | 52 |
| Buyers percentage | 0,146 | 0,146 | 0,159 | 0,189 | 0,115 | 0,108 | 0,087 | 0,125 | 0,115 |
Rozszerzmy nasze zapytanie na kolejną oś:
select
[Department].Members on 0,
{[Measures].Members, [Measures].[Buyers percentage]} on 1,
[Date].Members on 2
from [Sales and Visits]
otrzymujemy poniższy wynik:
PAGES: [Date].[2020-08-01]
| | Gdańsk | Kraków | Warszawa |
| | | BKDS Gdansk | | BKDS Cracow | BKDS Cracow 2 | | BKDS Warsaw | BKDS Warsaw 2 | BKDS Warsaw 3 |
+-------------------+--------+-------------+--------+-------------+---------------+----------+-------------+---------------+---------------+
| Sales count | 2 | 2 | 4 | 3 | 1 | 4 | 1 | | 3 |
| Visitors count | 8 | 8 | 13 | 8 | 5 | 47 | 23 | 7 | 17 |
| Buyers percentage | 0,25 | 0,25 | 0,308 | 0,375 | 0,2 | 0,085 | 0,043 | | 0,176 |
PAGES: [Date].[2020-08-02]
| | Gdańsk | Kraków | Warszawa |
| | | BKDS Gdansk | | BKDS Cracow | BKDS Cracow 2 | | BKDS Warsaw | BKDS Warsaw 2 | BKDS Warsaw 3 |
+-------------------+--------+-------------+--------+-------------+---------------+----------+-------------+---------------+---------------+
| Sales count | 2 | 2 | 5 | 3 | 2 | 5 | 1 | 2 | 2 |
| Visitors count | 20 | 20 | 22 | 8 | 14 | 41 | 9 | 13 | 19 |
| Buyers percentage | 0,1 | 0,1 | 0,227 | 0,375 | 0,143 | 0,122 | 0,111 | 0,154 | 0,105 |
PAGES: [Date].[2020-08-03]
| | Gdańsk | Kraków | Warszawa |
| | | BKDS Gdansk | | BKDS Cracow | BKDS Cracow 2 | | BKDS Warsaw | BKDS Warsaw 2 | BKDS Warsaw 3 |
+-------------------+--------+-------------+--------+-------------+---------------+----------+-------------+---------------+---------------+
| Sales count | 2 | 2 | 1 | 1 | | 5 | 2 | 2 | 1 |
| Visitors count | 13 | 13 | 28 | 21 | 7 | 42 | 14 | 12 | 16 |
| Buyers percentage | 0,154 | 0,154 | 0,036 | 0,048 | | 0,119 | 0,143 | 0,167 | 0,062 |
czyli w końcu uzyskaliśmy to, co chcieliśmy!
A jak to wygląda w środku?
Rzućmy okiem na zapytania SQL, które Mondrian wygenerował w celu pobrania danych dla tej tabeli:
----1
select
"department"."city" as "c0",
"Date_alias"."day" as "c1",
sum("sc_alias"."count") as "m0"
from
"department" as "department",
(select *, 1 as "count" from sales) as "sc_alias",
(select distinct day from sales
union
select distinct day from visits) as "Date_alias"
where
"sc_alias"."department_id" = "department"."id"
and
"sc_alias"."day" = "Date_alias"."day"
group by
"department"."city",
"Date_alias"."day"
----2
select
"department"."city" as "c0",
"Date_alias"."day" as "c1",
sum("visits"."visitors") as "m0"
from
"department" as "department",
"visits" as "visits",
(select distinct day from sales
union
select distinct day from visits) as "Date_alias"
where
"visits"."department_id" = "department"."id"
and
"visits"."day" = "Date_alias"."day"
group by
"department"."city",
"Date_alias"."day"
----3
select
"department"."city" as "c0",
"department"."name" as "c1",
"Date_alias"."day" as "c2",
sum("visits"."visitors") as "m0"
from
"department" as "department",
"visits" as "visits",
(select distinct day from sales
union
select distinct day from visits) as "Date_alias"
where
"visits"."department_id" = "department"."id"
and
"visits"."day" = "Date_alias"."day"
group by
"department"."city",
"department"."name",
"Date_alias"."day"
----4
select
"department"."city" as "c0",
"department"."name" as "c1",
"Date_alias"."day" as "c2",
sum("sc_alias"."count") as "m0"
from
"department" as "department",
(select *, 1 as "count" from sales) as "sc_alias",
(select distinct day from sales
union
select distinct day from visits) as "Date_alias"
where
"sc_alias"."department_id" = "department"."id"
and
"sc_alias"."day" = "Date_alias"."day"
group by
"department"."city",
"department"."name",
"Date_alias"."day"
Zaoszczędziliśmy sobie całkiem dużo pisania i myślenia – no i trudniej popełnić tutaj błąd przy pisaniu.
Czy to wszystko?
Wręcz przeciwnie. To dopiero podstawy, ledwo co poruszyliśmy tematy javowego API, konstruowania schematów, zapytań MDX-owych oraz optymalizacji – która nie była poruszona wcale.
Jeżeli korzystamy z lokalnej bazy danych, stworzonej tylko do tego celu, oraz mamy mało elementów to wszystko wykona się błyskawicznie. Jednakże bez próby optymalizacji, w szczególności na większych bazach czasy wykonania mogą bardzo szybko przekroczyć dziesiątki sekund, zajmując parę minut. Nawet jeżeli nie chcemy zmienić struktury bazy lub samej bazy na typ optymalny do zadania, nadal możemy próbować optymalizować czasy wykonania na różne sposoby.
Pierwszy, klasyczny wręcz, sposób optymalizacji to tworzenie indeksów na tabelach.
Niektóre systemy zarządzania bazami danych oferują zmaterializowane widoki – widoki, które "zapamiętują" dane, które przechowują. Jeżeli często korzystamy zamiast z widoków zamiast tabel, możemy się również zastanowić nad tym sposobem optymalizacji.
Podsumowanie
W tym artykule pokazałem, jak w prosty sposób można przedstawić wielowymiarowe dane, korzystając z biblioteki Mondrian – biblioteki będącej Java-owym reprezentantem narzędzi typu OLAP. Przedstawiłem podstawowy szkielet programu, schemat definiujący kostkę opartą na istniejącej bazie danych oraz zapytania MDX pozwalające nam na wydobycie danych.
