

Dario RadečićData Science ConsultantNeos
Nie używaj CSV! Poznaj format 150 razy szybszy
Używanie plików CSV kosztuje cię czas, miejsce na dysku i pieniądze. Czas z tym skończyć.
CSV to nie jedyny istniejący format zapisu danych. W rzeczywistości powinien być ostatnim na liście tych, z których powinieneś korzystać. Jeśli zatem nie planujesz ręcznej edycji zapisu danych, tracisz tylko czas i pieniądze.
Wyobraźmy sobie taką sytuację — zbierasz duże ilości danych i przechowujesz je w chmurze. Nie zrobiłeś zbyt dużego researchu na temat formatów plików, więc zdecydowałeś się na CSV. Twoje wydatki są dość wysokie! A jeden prosty zabieg może zmniejszyć je o połowę, jeśli nie więcej. Tym zabiegiem jest... Zgadłeś! Wybór innego formatu pliku.
Dzisiaj poznasz tajniki formatu danych Feather — szybkiego i lekkiego formatu binarnego do przechowywania ramek danych (DataFrame).
Czym dokładnie jest Feather?
Najprościej mówiąc, jest to format danych do przechowywania ramek danych (pomyśl o Pandas). Został on zaprojektowany na podstawie prostego założenia - jak najefektywniej wpychać i wypychać ramki danych z pamięci. Początkowo został on zaprojektowany do szybkiej komunikacji między Pythonem i R, ale nie tylko.
Nie, Feather nie jest ograniczony do Pythona i R — możesz pracować z plikami Feather w każdym bardziej popularnym języku programowania.
Format danych nie jest przeznaczony do długotrwałego przechowywania. Pierwotnym zamiarem była szybka wymiana pomiędzy programami R i Pythonem oraz krótkoterminowe przechowywanie danych w ogóle. Nikt nie zabroni Ci zrzucać plików Feather na dysk i zostawiać ich tam na lata, ale do tego istnieją bardziej wydajne formaty.
W Pythonie można pracować z Feather poprzez Pandas lub za pomocą osobnej biblioteki. W tym artykule poznasz oba sposoby. Do tego konieczna będzie instalacja feather-format. Tutaj znajduje się polecenie terminala:
# Pip
pip install feather-format
# Anaconda
conda install -c conda-forge feather-formatTo wszystko, czego potrzebujesz, żeby zacząć. Otwórz JupyterLab lub jakiekolwiek inne data science IDE, ponieważ następna sekcja obejmuje podstawy Feather.
Jak pracować z Feather w Pythonie?
Zacznijmy od importu bibliotek i stworzenia stosunkowo dużego zbioru danych. Będziesz potrzebował Feather, Numpy i Pandas, aby kontynuować. Zbiór danych będzie miał pięć kolumn i 10 milionów wierszy losowych liczb:
import feather
import numpy as np
import pandas as pd
np.random.seed = 42
df_size = 10_000_000
df = pd.DataFrame({
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size)
})
df.head()Tak wygląda nasz zbiór danych:
Zapiszmy go lokalnie. Możesz użyć następującego polecenia, aby zapisać ramkę do formatu Feather za pomocą Pandas:
df.to_feather('1M.feather')
I tak samo z biblioteką Feather:
feather.write_dataframe(df, '1M.feather')Niewielka różnica. Oba pliki są teraz zapisywane lokalnie. Można je czytać zarówno z Pandas, jak i z osobną biblioteką. Oto składnia dla Pandas:
df = pd.read_feather('1M.feather')
Jeśli używasz biblioteki Feather, zmień ją w ten sposób:
df = feather.read_dataframe('1M.feather')
I to na razie wszystko, co powinieneś wiedzieć w tym temacie. Poniżej znajdziesz porównanie z formatem pliku CSV — pod względem wielkości pliku, czasu odczytu i zapisu.
CSV vs. Feather – którego z nich powinieneś używać?
Jeśli nie potrzebujesz zmieniać danych w locie, odpowiedź jest prosta — powinieneś używać Feather. Zróbmy jednak kilka testów.
Poniższy wykres przedstawia czas potrzebny do zapisania DataFrame z ostatniej lokalnej sekcji:
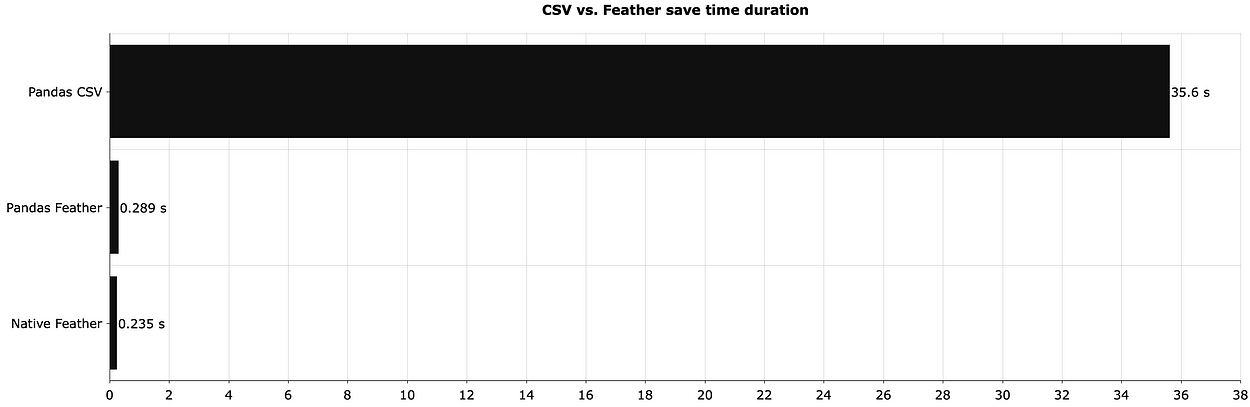
Drastyczna różnica — Feather jest około 150 razy szybszy niż CSV. Nie ma to zbyt dużego znaczenia, jeśli używasz Pandas do pracy z plikami Feather, ale wzrost prędkości w porównaniu z CSV jest znaczący.
Następnie porównajmy czasy odczytu — ile czasu zajmuje odczyt identycznych zestawów danych w różnych formatach:
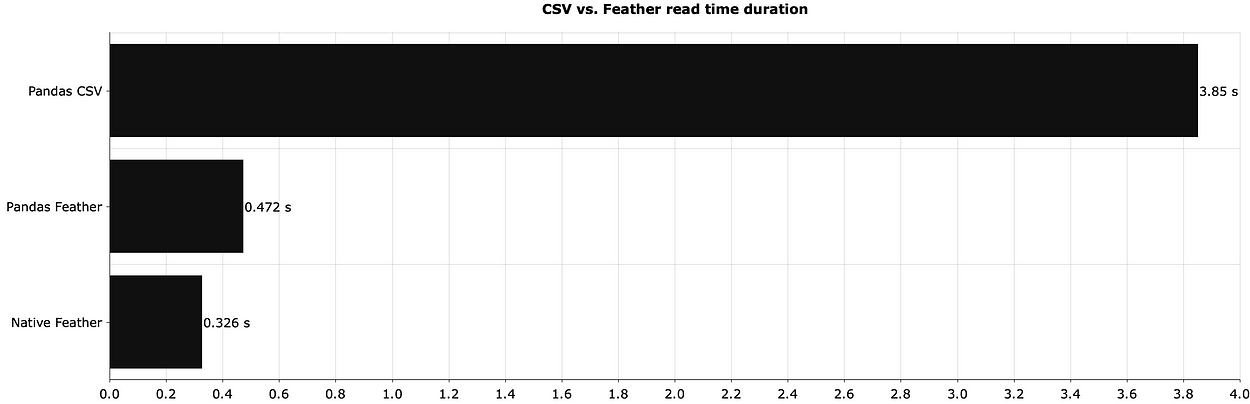
I znowu, znaczące różnice. Pliki CSV są znacznie wolniejsze do odczytania. Zajmują też więcej miejsca na dysku, ale dokładnie o ile więcej?
Na to pytanie odpowiada właśnie kolejna wizualizacja:
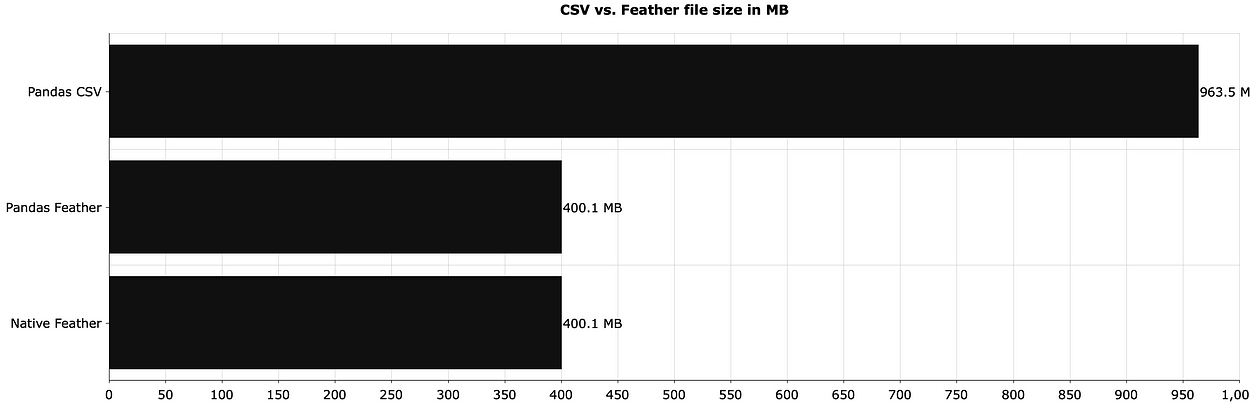
Jak widać, pliki CSV zajmują ponad dwa razy więcej miejsca niż pliki Feather.
Jeśli codziennie przechowujesz gigabajty danych, wybór właściwego formatu pliku ma kluczowe znaczenie. Pod tym względem Feather wygrywa z CSV. Jeśli potrzebujesz jeszcze większej kompresji, powinieneś wypróbować Parquet. Uważam, że jest to najlepszy z dzisiejszych formatów.
Podsumowując, zmiana to_csv() na to_feather () oraz read_csv() na read_feather() może zaoszczędzić Ci sporo czasu i miejsca na dysku. Weź to pod uwagę przy następnym projekcie Big Data.
Oryginał tekstu w języku angielskim można przeczytać tutaj.
