

Ihor KosandiakLead Full Stack Java DeveloperORIL
Przyspiesz swoją aplikację ze Spring Cache
Sprawdź, jak Spring Boot oraz Spring Cache przyśpieszą działanie Twojej apki na przykładzie tworzenia aplikacji serwerowej.
Artykuł ten pokaże Ci, jak używać Spring Boot z cache’owaniem, tak aby zwiększyć wydajność Twojej aplikacji. Prawdopodobnie wielu z Was miało problem dotyczący powolnego serwisu. Dlaczego tak w ogóle jest?
Istnieje wiele powodów. Oto najbardziej popularne:
- Wysokie przeciążenie - wiele użytkowników w usłudze
- Skomplikowana logika biznesowa - kiedy jest dużo rzeczy do wyliczenia, które kalkuluje się przy każdym żądaniu od użytkownika
- Zewnętrzna baza danych - dobrze jest mieć bazę danych, którą dostarcza ktoś zaufany, kto ją też regularnie zabezpiecza. Niestety wpływa to negatywnie na wydajność, bo cały cykl wysłania żądania z serwera do bazy danych i powrót z danymi trwa dłużej.
Powodów może być jeszcze więcej, ale powyższe są najbardziej popularne.
Rozwiązanie
Spring ma naprawdę świetne narzędzie do zwiększenia wydajności i dostępności Twojego serwera - nazywa się ono Spring Cache. Przyjrzymy się cache’owaniu danych krok po kroku, tworząc aplikację serwerową. Wykorzystamy tutaj Spring Boot razem ze Spring Cache.
Najszybszym sposobem na stworzenie projektu Spring Boot jest prawdopodobnie wygenerowanie go ze Spring Initialzr. Zależności, których na razie potrzebujemy, to Web i Cache. Pobierz je, rozpakuj i otwórz w swoim IDE. Ja będę używał IntelliJIdea. Po otwarciu, mamy strukturę następnego projektu:
OK, teraz utworzymy klasę domenową User oraz UserService, która będzie wypełniać fikcyjne dane dla użytkowników i UserController, który zdefiniuje punkty końcowe. Nasze User.class będzie wyglądać następująco:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User {
private String username;
private int age;
}
Zwróć uwagę na adnotacje nad nazwą klasy. Wszystkie pochodzą z biblioteki lombok, którą możesz dodać do projektu za pomocą zależności Maven:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.16</version>
<scope>provided</scope>
</dependency>
Klasa UserController będzie na razie miała tylko jedno mapowanie, tak aby pobrać wszystkich użytkowników:
@RestController
@RequestMapping(value = "/users")
public class UserController {
private final UserService userService;
@Autowired
UserController (UserService userService) {
this.userService = userService;
}
@GetMapping(value = "/all")
public List<User> getAllUsers() {
return userService.findAll();
}
}
Usługa UserService, gdzie wszystko będzie się odbywać, wygląda na razie tak:
@Service
public class UserService {
private List<User> users = new ArrayList<>();
@Autowired
UserService() {}
@PostConstruct
private void fillUsers() {
users.add(User.builder().username("user_1").age(20).build());
users.add(User.builder().username("user_2").age(76).build());
users.add(User.builder().username("user_3").age(54).build());
users.add(User.builder().username("user_4").age(30).build());
}
public List<User> findAll() {
simulateSlowService();
return this.users;
}
private void simulateSlowService() {
try {
Thread.sleep(3000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Jak widać, mamy na razie tylko jeden punkt końcowy - http://localhost:8080/users/all. Powinien on zwrócić wszystkich użytkowników przechowywanych w zmiennej users.
Symulujemy jednak, że nasza usługa jest naprawdę powolna, wywołując następującą metodę: simulateSlowService() — odczeka ona 3 sekundy przed wykonaniem logiki wewnątrz metody findAll().
A kiedy wykonasz żądanie GET do naszego punktu końcowego find all users, to otrzymasz następny wynik:
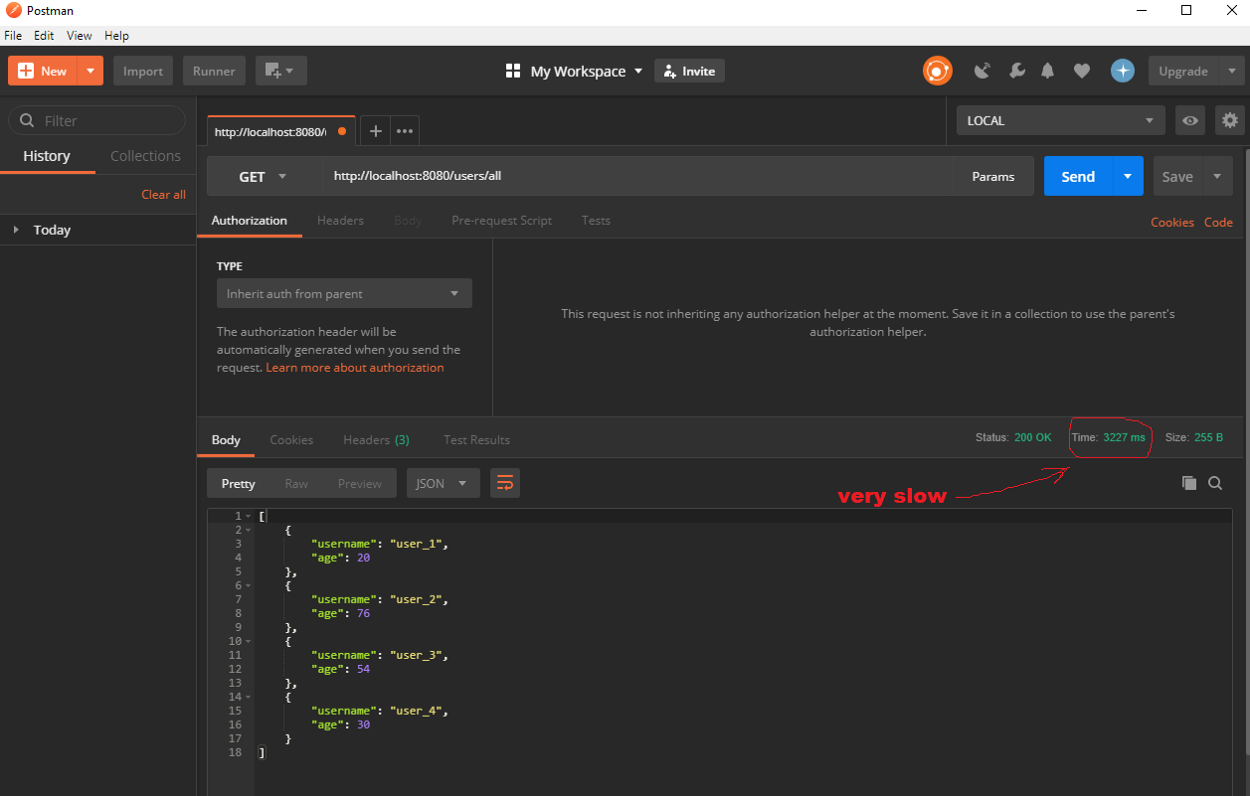
Pobranie wszystkich użytkowników zajmuje około 3227 milisekund. I jeżeli to by był prawdziwy serwis, to byłby to tragiczny wynik. Spring Cache rozwiąże jednak nasz problem.
Pogrzebiemy teraz w kodzie. Oto Główna klasa SpringBootWithCachingApplication.class.
@SpringBootApplication
@EnableCaching //enables Spring Caching functionality
public class SpringBootWithCachingApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootWithCachingApplication.class, args);
}
}
A oto UserService.class.
@Service
@CacheConfig(cacheNames={"users"}) // tells Spring where to store cache for this class
public class UserService {
private List<User> users = new ArrayList<>();
@Autowired
UserService() {}
@PostConstruct
private void fillUsers() {
users.add(User.builder().username("user_1").age(20).build());
users.add(User.builder().username("user_2").age(76).build());
users.add(User.builder().username("user_3").age(54).build());
users.add(User.builder().username("user_4").age(30).build());
}
@Cacheable // caches the result of findAll() method
public List<User> findAll() {
simulateSlowService();
return this.users;
}
private void simulateSlowService() {
try {
Thread.sleep(3000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}@CacheConfig - możesz zdefiniować część konfiguracji pamięci podręcznej w jednym miejscu - na poziomie klasy, dzięki czemu nie będziesz musiał wielokrotnie czegoś deklarować.
@Cacheable - kiedy metoda ma taką adnotację, to będzie wykonywana tylko raz dla danego cachekey, chyba że to, co znajduje się pod, kluczem przestanie być aktualne, lub zostanie usunięte.
Teraz uruchamiamy serwer ponownie i każemy żądaniu GET pobrać wszystkich użytkowników. Za pierwszym razem minie około 3 sekund, zanim dostaniemy dane. A to dlatego, że za pierwszym razem żądanie sprawdza cache i widzi, że jest puste - stąd wynika 3-sekundowe opóźnienie wykonania metody.
Wszystkie dalsze żądania findAll() będą jednak uruchamiane znacznie szybciej, ponieważ metoda nie zostanie wykonana. A to dlatego, że żądane dane były wcześniej cache'owane i zostaną pobrane z pamięci.
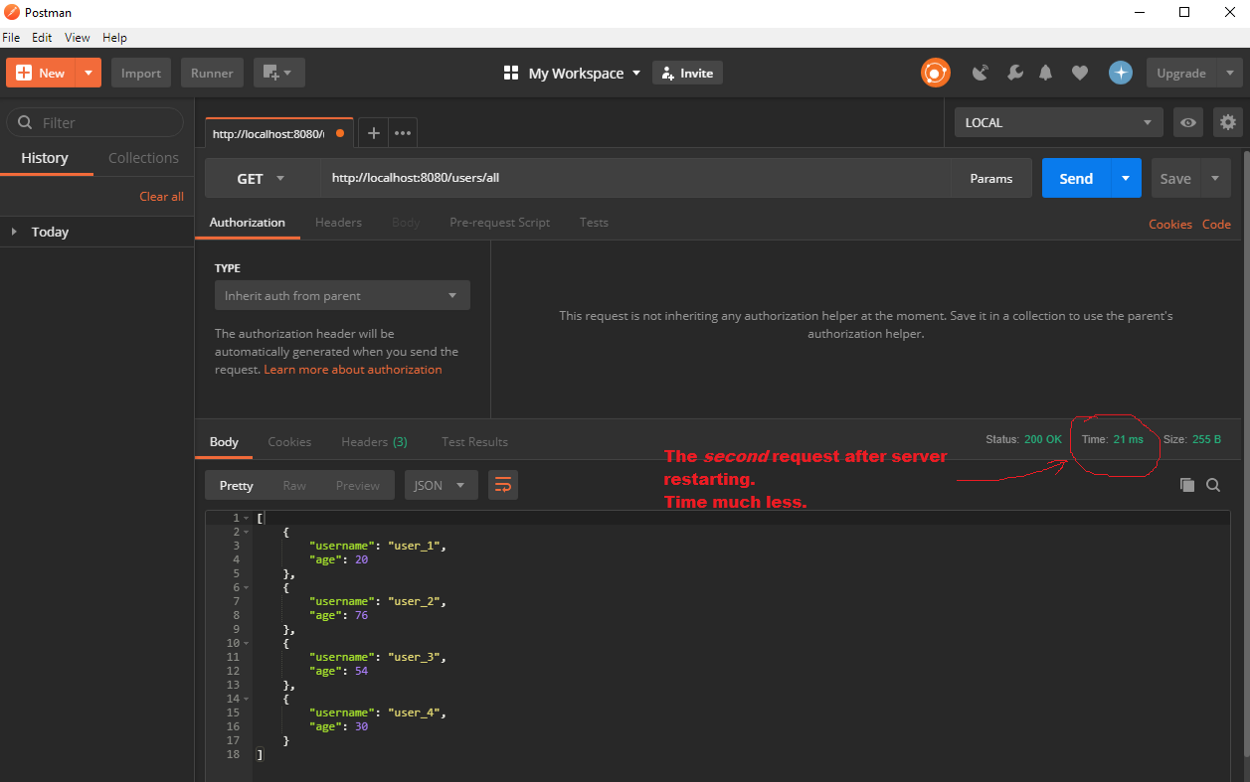
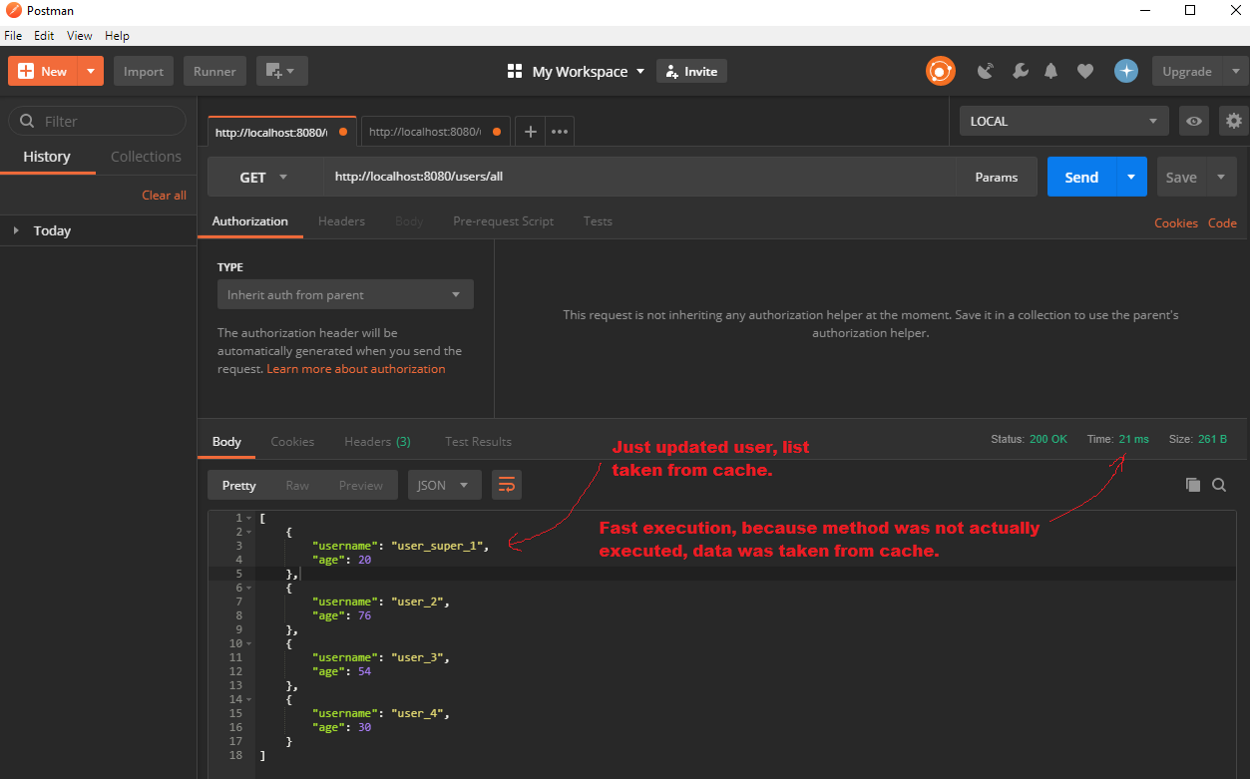
Jak widać, czas wykonania żądania jest znacznie krótszy niż wcześniej. Dzieje się tak dlatego, że metoda findAll() nie jest wykonywana, ponieważ dane są już w cache - i to dlatego wszystko działa tak szybko! To nie jest jednak jeszcze do końca to, czego chcemy. Wyobraź sobie, że użytkownik otrzymał jakąś aktualizację. Na przykład, nazwa pierwszego użytkownika została zmieniona z „user_1” na „user_super_1”.
A ponieważ metoda findAll() jest oznaczona jako cacheable, to nie zostanie wykonana i będziemy cały czas dostawać stare dane z pamięci. A tego raczej nie chcemy. W zasadzie za każdym razem, gdy coś się zmieni (aktualizacja, zapisywanie żądań), musimy odpowiednio aktualizować nasze cache. Zobaczmy, jak możemy to zrobić.
Na przykład, dodam metodę, która zmieni pierwszego użytkownika w tablicy.
@CachePut
public User updateUser(User user) {
this.users.set(0, user);
return this.users.get(0);
}@CachePut - zawsze zezwala na wykonanie metody. Służy do aktualizowania pamięci podręcznej przy pomocy wyniku wykonania metody. Gdy zaktualizujemy pierwszego użytkownika i odpowiednią metodę z adnotacją @CachePut, to zaktualizuje ona dane w cache, a żądanie findAll() zwróci nam ostatnio zaktualizowane dane. Zostanie to wykonane bardzo szybko.
Pozostała nam jeszcze jedna interesująca rzecz:
@CacheEvict - usuwa dane z cache. Możesz tego używać na różne sposoby:
- jeśli chcesz opróżnić całe cache
@CacheEvict(allEntries = true)
- albo usuń element za pomocą klucza
@CacheEvict(key = "#user.username")
W ten sposób nie będziesz przechowywać w cache niepotrzebnych danych. I to jest właśnie sposób, w jaki Spring Cache może pomóc w rozwiązaniu problemów z wydajnością podczas developementu.
Pamiętaj jednak, aby nie używać cache'owanie, gdy nie jest to potrzebne. Zajrzyj do mojego repozytorium na GitHubie, aby jeszcze lepiej zrozumieć ten temat.
Jeśli chcesz użyć jakiegoś konkretnego narzędzia do cache'owania, to możesz użyć Hazelcast. Dowiedz się o nim więcej z tego artykułu. Sprawdź też to konto na GitHubie, aby zdobyć trochę zasobów do pracy nad omawianym tutaj tematem.
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.
Masz jakieś przemyślenia dotyczącego tego tematu. Podziel się nimi w komentarzu ?
