

Szymon CzarnuchDevOps Engineer
Monitorowanie serwisów web przy użyciu Prometheusa
Sprawdź, jak zaimplementować Prometheusa oraz Grafanę do monitorowania serwisów web, aby sprawdzać status różnych serwisów w jednym miejscu dla całych projektów.
Podczas jednego z ostatnich sprintów dostałem zadanie stworzenia prostego monitoringu dla kilku serwisów web z wykorzystaniem Prometheusa i Grafany. Szczerze mówiąc nie zgłębiałem nigdy tego zagadnienia, ale jak się okazało, wcale nie jest to rocket science.
Potrzeba monitorowania kilku serwisów wykorzystywanych w projekcie zrodziła się dlatego, że projekt realizowany jest w kilkunastu odrębnych lokalizacjach. Z tego względu istnieje potrzeba sprawdzenia statusu danych serwisów w jednym miejscu dla całego projektu.
Po krótkich poszukiwaniach odkryłem, że do tego zadania mogę wykorzystać Blackbox Exporter, który umożliwia sprawdzanie punktów końcowych, takich jak HTTPS, HTTP, TCP, ICMP czy też DNS. Istnieje wiele znakomitych gotowych rozwiązań, które prezentują zasadę działania całej architektury. Dzięki temu zaznajomienie się z tematem i implementacja monitoringu nie są czymś skomplikowanym.
Architektura
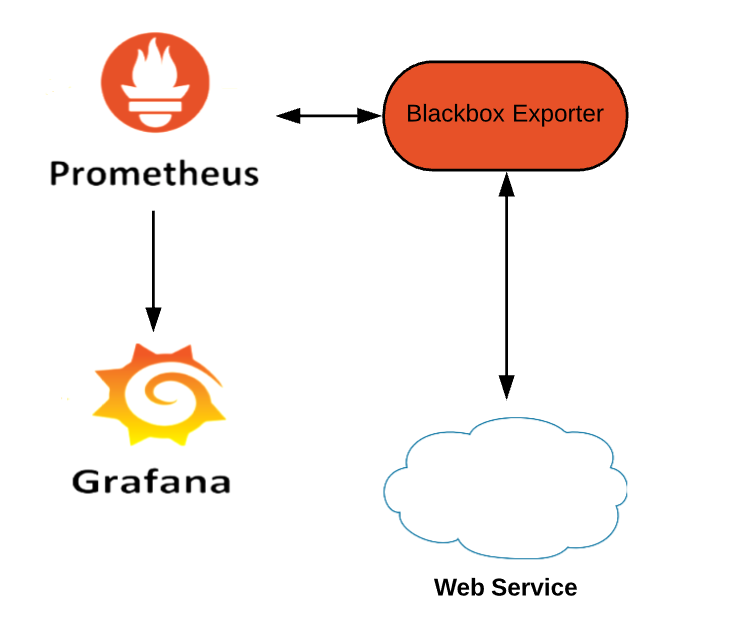
Zasada działania jest bardzo prosta - Prometheus jest połączony z Blackbox Exporter, który to monitoruje bezpośrednio w odpowiednim interwale czasowym określone wcześniej serwisy w pliku konfiguracyjnym. Prometheus z kolei jest połączony jako źródło danych do Grafany, co umożliwia wizualizację danych.
Kolejnym wymogiem postawionym przed tym rozwiązaniem była jego elastyczność, ponieważ monitoring może być wykorzystywany nie tylko przez jeden projekt, lecz w przyszłości przez inne projekty. Dlatego system powinien być jak najbardziej uniwersalny, tak aby jego użycie nie wymagało od innych wprowadzania żadnych zmian w repozytorium.
Konfiguracja
Zacząłem pracę od stworzenia docker-compose.yml, w którym zostały zdefiniowane dwa kontenery. Pierwszy z nich to oczywiście Prometheus, drugi to Blackbox-exporter.
version: "3"
services:
prometheus:
image: prom/prometheus
command: ['--config.file=/monitoring/prometheus.yml']
ports:
- 9090:9090
volumes:
- ./prometheus:/monitoring/
blackbox:
privileged: true
image: prom/blackbox-exporter
command: ['--config.file=/config/blackbox.yml']
ports:
- 9115:9115
volumes:
- ./blackbox.yml:/config/blackbox.yml
Następnie należało utworzyć pliki konfiguracyjne zarówno dla Prometheus, jak i dla Blackbox-exporter.
modules:
http_2xx:
prober: http
timeout: 5s
http:
preferred_ip_protocol: ip4
no_follow_redirects: false
tls_config:
insecure_skip_verify: true
http_post_2xx:
prober: http
timeout: 5s
http:
method: POST
preferred_ip_protocol: ip4
tcp_connect:
prober: tcp
timeout: 5s
tcp:
preferred_ip_protocol: ip4
icmp:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: ip4
http_2xx_home:
prober: http
timeout: 5s
http:
method: GET
fail_if_body_not_matches_regexp:
- "OK"
fail_if_not_ssl: true
preferred_ip_protocol: ip4
Kolejnym krokiem było utworzenie konfiguracji dla samego Prometheusa.
scrape_configs:
# The job name assigned to scraped metrics by default.
- job_name: monitoring
static_configs:
- targets: ['localhost:9090']
- job_name: 'blackbox'
# The HTTP resource path on which to fetch metrics from targets
metrics_path: /probe
# Configures the protocol scheme used for requests.
scheme: http
# Optional HTTP URL parameters
params:
module: [http_2xx]
# List of file service discovery configurations
file_sd_configs:
- files:
- targets.yml
# List of target relabel configurations
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox:9115
Gdy cała konfiguracja dla komponentów jest gotowa, wystarczy utworzyć plik target.yml, w którym każdy będzie mógł zdefiniować serwisy, które mają być monitorowane.
- targets:
- https://google.com
- https://youtube.com
Po utworzeniu wszystkich plików, struktura projektu wyglądała w następujący sposób:
monitoring/
┣ prometheus/
┃ ┣ prometheus.yml
┃ ┗ targets.yml
┣ blackbox.yml
┗ docker-compose.yml
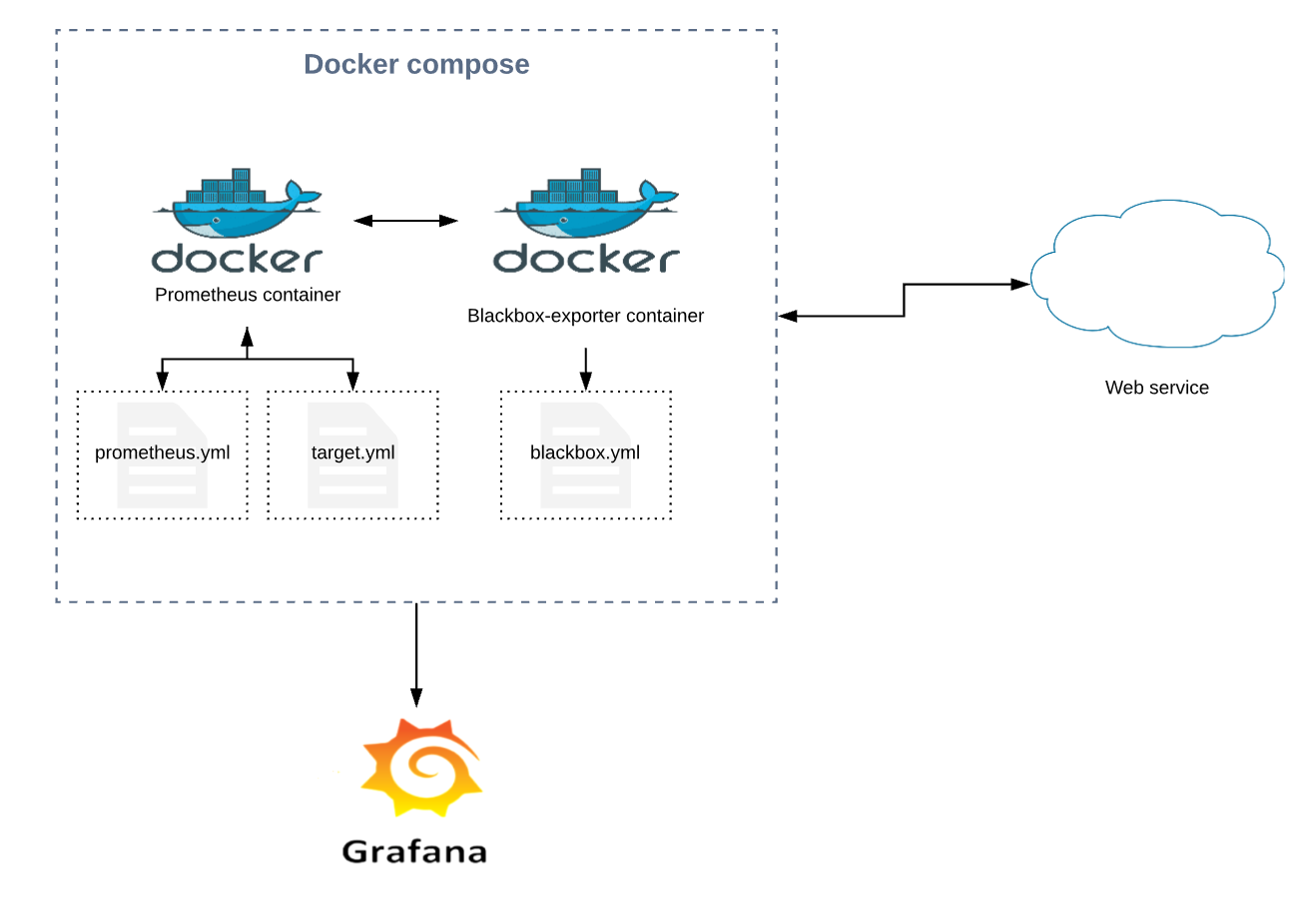
Powyżej przedstawiony jest już dokładny schemat budowy systemu. Jak widać każdy element systemu zarówno Prometheus, jak i Blackbox-exporter, posiadają swoje pliki konfiguracyjne. Jedynym plikiem podlegającym modyfikacji w zależności od potrzeb danego projektu, jest plik target.yml, w którym zdefiniowane są serwisy do monitorowania.
Uruchomienie systemu
Do uruchomienia systemu wystarczy nam Docker wraz z Docker Compose. Teraz należy wydać polecenie docker-composer up, co spowoduje uruchomienie dwóch kontenerów, Prometheus będzie dostępny na porcie localhost:9090 a Blackbox-exporter na localhost:9115.
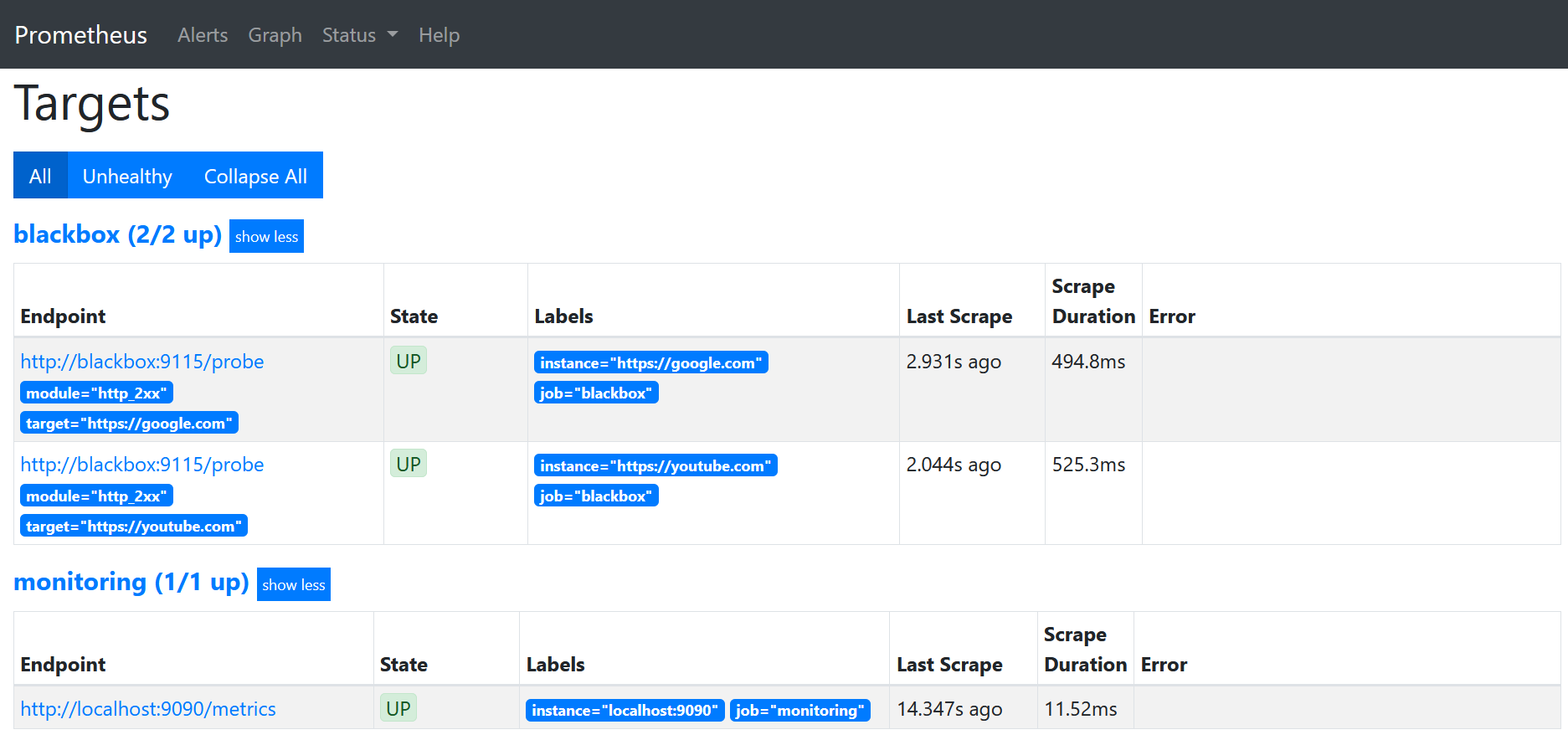
Po przejściu kolejno najpierw do Prometheusa, w zakładce targets możemy sprawdzić statusy aktualnie podłączonych punktów. Natomiast w Blackbox exporter mamy już dostęp do dokładnych logów, co może przydać się podczas sprawdzania ewentualnych problemów z danym serwisem. Jak widać oba serwisy zostały odczytane z pliku target.yml i są już monitorowane.
Niestety w tej postaci monitoring pomoże nielicznemu gronu odbiorców, dlatego należy połączyć Prometeus do Grafany, aby uzyskać kompaktową wizualizację danych (w moim przypadku instancja Grafany istniała już wcześniej). Od podstaw można ją w łatwy sposób uruchomić w osobnym kontenerze. Samo połączenie obu narzędzi jest banalnie proste.
Jeśli natomiast nie chcemy zagłębiać się w tworzenie od podstaw dashboardu wraz ze wszystkimi panelami, polecam znaleźć gotowe rozwiązania w postaci pliku json, które wystarczy zaimportować do naszej instancji Grafany. Sam wykorzystałem takie podejście ze względu na to, że nie do końca jest mi po drodze z wizualizacją danych.
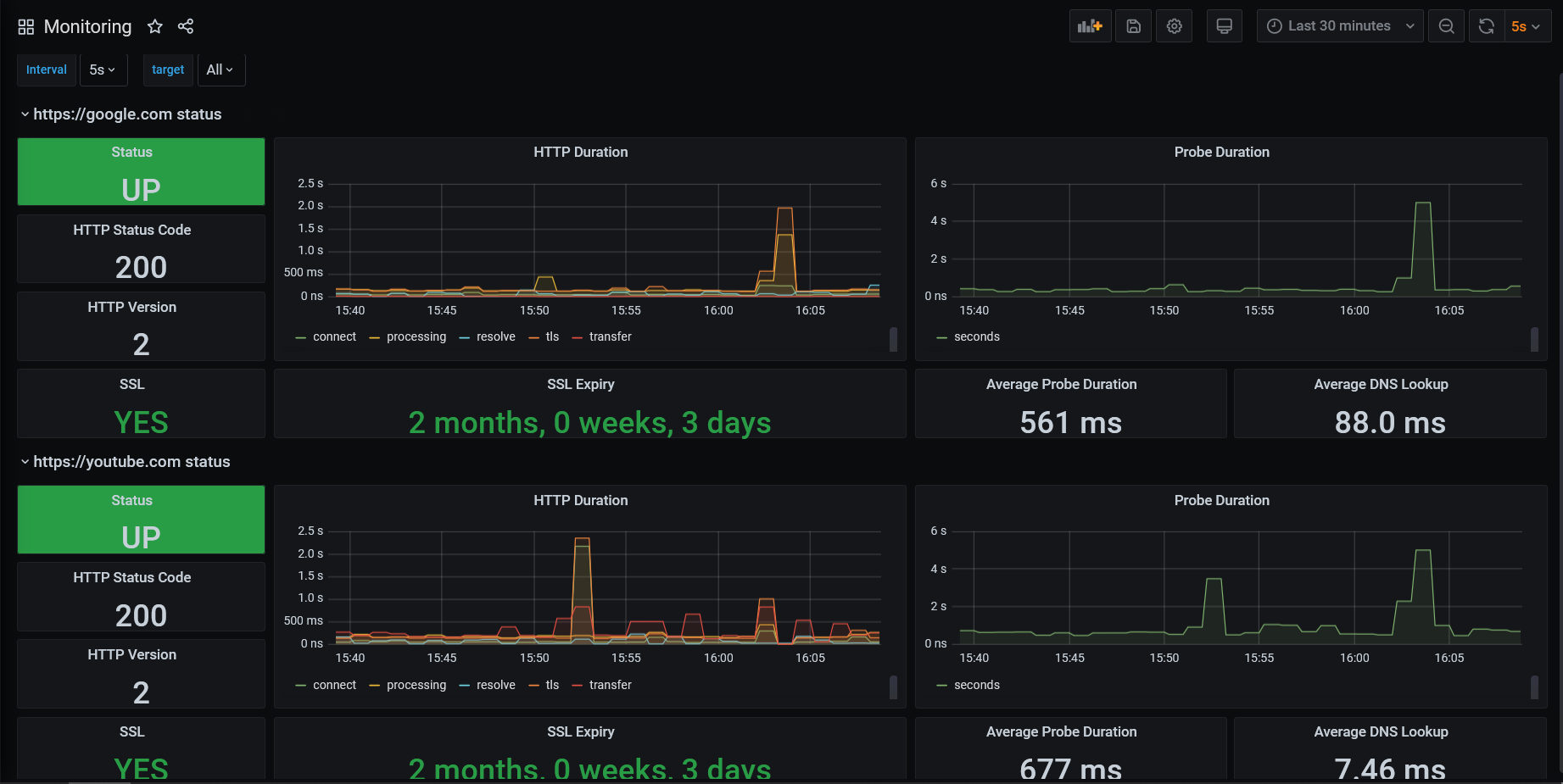
Jak widać gotowe rozwiązanie oparte na wcześniej pobranym pliku json sprawdza się doskonale. Oba serwisy i ich statusy są wyświetlane. Oczywiście najbardziej istotną dla nas informacją jest pole „status” które przedstawia obecny stan serwisu. Dodatkowo żadne zmiany nie musiały zostać zaimplementowane w dashboardzie tak, aby dostosować go do Prometheusa.
Podsumowanie
Zaimplementowanie prostego systemu monitoringu opartego o Prometheusa i Grafanę, nie jest wcale takie trudne. Na cały system składają się tak naprawdę trzy elementy, a dzięki temu, że tego rodzaju rozwiązania są dość popularne, w łatwy sposób dostaniemy wiele dobrych przykładów. W głównej mierze schemat naszego systemu zależy od wymagań, które są przed nami stawiane, w tym przypadku miała być to tylko wizualizacja statusu w Grafanie, ale w łatwy sposób możemy rozszerzyć ten system o powiadomienia wysyłane, gdy którykolwiek z serwisów przestanie działać.
Na koniec dodaję kilka linków wraz z kodem z Githuba, które może przydadzą się komuś w przyszłości:
https://github.com/czarny994/prometheus-demo
https://grafana.com/grafana/dashboards/7587
https://prometheus.io/docs/guides/multi-target-exporter/
https://prometheus.io/docs/introduction/overview/
