

Yann BriançonArchitecte développeurSipios
Eliminacja problemu N+1 zapytań w Hibernate
Poznaj wszystkie kroki, które prowadzą do wyeliminowania problemu z N+1 zapytań w Hibernate, co poprawi jego działanie.
Hibernate jest znanym ORM-em dla aplikacji Java. W tym artykule pokażę, jak poprawić jego wydajność, eliminując problem z N+1 zapytań. Po kilku miesiącach od wypuszczenia mojego projektu opartego o Spring i Hibernate musiałem poprawić wydajność, aby zaspokoić potrzeby moich użytkowników. Odkryłem wtedy problem N+1 zapytań i jego ogromny wpływ na wydajność moich żądań.
Na przykład, przez występowanie problemu N+1, pobranie 20 ostatnich wiadomości powodowało wywołanie 218 zapytań do bazy danych. Po zlikwidowaniu tego problemu liczba zapytań do bazy spadła do 7, a czas przetwarzania skrócił się z 3 sekund do 400 milisekund!
Aby pomóc w osiągnięciu podobnych wyników, wyjaśnię najpierw, na czym polega problem z N+1 zapytań w Hibernate, następnie pokażę, jak łatwo go wykryć za pomocą narzędzia spring-hibernate-query-utils, a na koniec podzielę się rozwiązaniami, które pomogą w jego naprawie.
Czym jest problem N+1 zapytań
Problem N+1 to antywzorzec wydajnościowy, w którym aplikacja masowo przesyła do bazy danych N+1 małych zapytań o dane z powiązanych tabel, zamiast wysłać jedno zapytanie, które zwróci wszystkie potrzebne dane. Można pomyśleć, że to prostszy proces, ale wykonanie wielu zapytań na serwerze bazy danych zajmie znacznie więcej czasu. Spójrzmy na przykład z klasami User i Message, gdzie Message ma autora, a User jest autorem kilku wiadomości.
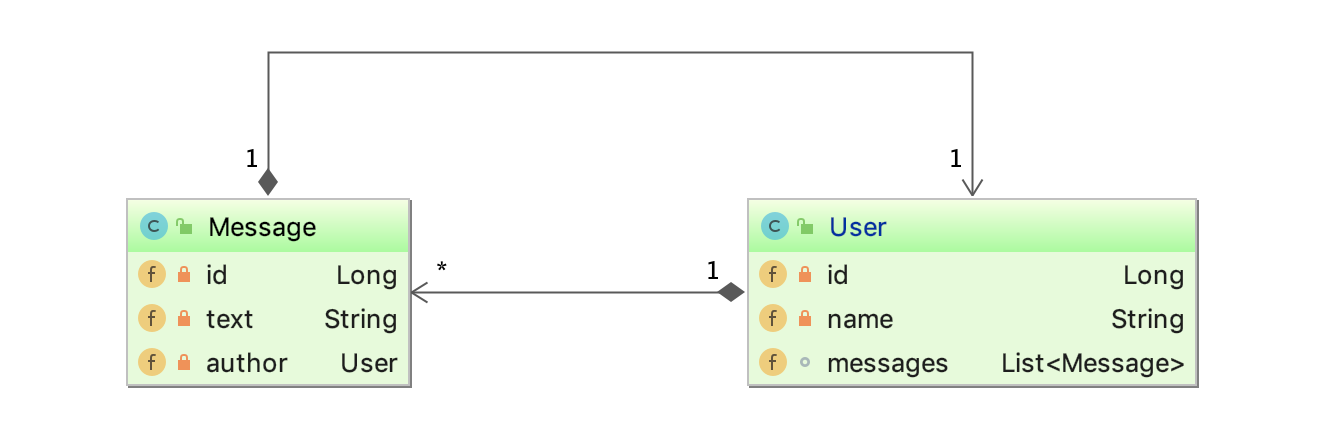
W Spring Message będzie miało pole autora, które jest skonfigurowane w taki sposób, aby ta relacja była pobierana w leniwy sposób. Pozwala to uniknąć pobierania, gdy nie jest to potrzebne:
class Message {
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "author_id")
private User author;
}Jeśli chcemy wyświetlić listę wszystkich wiadomości z nazwami autora, możemy napisać następujący kod:
void logMessages() {
// Get all the messages from the database
// -> Triggers 1 query
Set<Message> messages = messageDao.findAll();
// Map through the N messages to create the DTO with the author display name
// -> Triggers 1 query to fetch each author so N queries!
messages.stream.map(
message -> logger.info(
message.getAuthor().getName() + ": " + message.getText()
)
)
}Usługa ta miałaby oczekiwane zachowanie, ale spowodowałaby 8 zapytań w celu zalogowania 7 ostatnich wiadomości, 1 zapytanie w celu pobrania wiadomości oraz 7 zapytań w celu uzyskania każdego autora wiadomości:
INFO: select message0_.id as id1_0_, message0_.author_id as author_i3_0_, message0_.text as text2_0_ from messages message0_
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
INFO: select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?Można powiedzieć, że powinniśmy tylko usunąć konfigurację Lazy i to zadziała. To prawda, ale zmusiłoby Cię to do pobrania autora za każdym razem, gdy pobierasz wiadomość, a to również wpłynęłoby na wydajność.
Ale o rozwiązaniach później.
Wykrywanie problemu N+1 zapytań
Następnym krokiem będzie upewnienie się, że każdy z nas wie, jak rozpoznać problem z N+1 i że dowiemy się o tym na poziomie testów. Po małym researchu odkryłem, że Ruby on Rails ma fajne narzędzie do wykrywania zapytań N+1 o nazwie Bullet, ale nie znalazłem niestety niczego podobnego dla Spring.
Postanowiłem więc utworzyć bibliotekę, aby najpierw policzyć zapytania, a następnie wykryć N+1. Nazwałem ją spring-hibernate-query-utils i udostępniłem na GitHubie, a zapewnia ona automatyczne wykrywanie problemu z N+1. Instalacja jest naprawdę łatwa — dodaj bibliotekę do swoich zależności, a spowoduje ona pojawianie się logów o błędzie za każdym razem, gdy pojawi się N+1:
- Dodaj zależność do swojego projektu w pliku
pom.xml:
<dependency>
<groupId>com.yannbriancon</groupId>
<artifactId>spring-hibernate-query-utils</artifactId>
<version>1.0.3</version>
</dependency>- Zobacz, jak pojawiają się logi o błędach dotyczące
N+1:
@RunWith(MockitoJUnitRunner.class)
@SpringBootTest
@Transactional
class NPlusOneQueriesLoggingTest {
@Autowired
private MessageRepository messageRepository;
@Test
void nPlusOneQueriesDetection_isLoggingWhenDetectingNPlusOneQueries() {
// Fetch the messages without the authors
List<Message> messages = messageRepository.findAll();
// Trigger N+1 queries
List<String> names = messages.stream()
.map(message -> message.getAuthor().getName())
.collect(Collectors.toList());
}
}Po uruchomieniu testu możemy zobaczyć log ERROR dla każdego wygenerowanego N+1:
ERROR 49239 --- [main] c.y.i.HibernateQueryInterceptor:
N+1 queries detected on a getter of the entity entity.User
at NPlusOneQueriesLoggingTest.lambda$nPlusOneQueriesDetection_isLoggingWhenDetectingNPlusOneQueries$0(NPlusOneQueriesLoggingTest.java:16)
Hint: Missing Eager fetching configuration on the query that fetches the object of type com.yannbriancon.entity.UserLogowanie jest OK, ale aby wyeliminować N+1 zapytań, potrzebujemy wyjątku, aby przerwać nasze testy. W tym celu dodałem opcję konfiguracji hibernation.query.interceptor.error-level, którą można ustawić na EXCEPTION, aby zgłaszać wyjątek za każdym razem, gdy zostanie wykryte N+1. Aby wyeliminować problem z N+1, zdecydowanie polecam ustawienie poziomu błędu na EXCEPTION we właściwościach profilu testowego. Pozwoli Ci to wykryć i oznaczyć wszystkie N+1 w czasie testów.
Po wykonaniu tej czynności konieczne może być zmienienie sygnalizowania N+1 na ERROR, aby nie przerywać wyjątkiem wszystkich testów. W tym celu proponuję zmienić to tylko w testach, których nie można teraz naprawić za pomocą @SpringBootTest:
@RunWith(SpringRunner.class)
@SpringBootTest("hibernate.query.interceptor.error-level=ERROR")
@Transactional
class NPlusOneQueriesLoggingTest {
...
}Test się wykona, a Ty będziesz mieć szansę naprawić go później. To tyle! Każdy programista, który doda N+1, zepsuje test i będzie musiał poprawić swój kod. Ale jak możemy zmienić kod, aby uniknąć problemu z N+1?
Naprawa problemu
Zachłanne pobieranie (ang. eager fetching)
Rozwiązaniem problemu z N+1 jest skonfigurowanie Hibernate tak, aby od razu pobierał wskazane zależności w każdym zapytaniu. Jak wyjaśniłem wcześniej, najlepszą praktyką jest konfigurowanie relacji (ManyToOne…), aby domyślnie wykorzystywały opóźnione ładowanie. Każde zapytanie, które tego wymaga, powinno nadpisać domyślną konfigurację, dzięki czemu unikniemy ładowania zbędnych danych.
Aby uzyskać więcej informacji, zapoznaj się z tym artykułem.
W Spring i Hibernate istnieje kilka sposobów wykonywania zapytania i taką samą liczbę sposobów konfigurowania trybu pobierania. Oto różne rozwiązania dla każdego rodzaju zapytania:
- Przy zapytaniu
JPAużyj diagramu encji:
@EntityGraph(attributePaths = {"author"})
List<Message> getAllBy();- Przy zapytaniu
JPQL, użyj słowa kluczowegoJOIN FETCH:
@Query("SELECT *
FROM Message m
LEFT JOIN FETCH m.author")
List<Message> getAllBy();- Zapytanie w Criteria, użyj metody
fetch:
List<Message> getAllBy() {
CriteriaBuilder criteriaBuilder = entityManager.getCriteriaBuilder();
CriteriaQuery<Message> query = criteriaBuilder.createQuery(Message.class);
Root<Message> message = query.from(Message.class);
// Add fetching of the author field
message.fetch(Message_.author, JoinType.LEFT);
query.select(message);
TypedQuery<Message> typedQuery = entityManager.createQuery(query);
return typedQuery.getResultList();
}Teraz wiemy, jak naprawić problem z N+1.
Zachłanne pobieranie z limitowaniem wyników
Co, jeśli potrzebujesz jedynie 5 ostatnich użytkowników z ich wiadomościami. Przy objaśnianej powyżej strategii zapytanie wyrzuci ostrzeżenie HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
To ostrzeżenie zapobiega bardzo złej wydajności, gdy pobierane są wszystkie wiersze, a wybieranie właściwych rekordów, ma miejsce w pamięci. Najlepszym sposobem na zrozumienie, dlaczego limit nie został zastosowany w SQL, jest sprawdzenie zapytania wygenerowanego podczas pobierania użytkowników:
select
user0_.id,
messages1_.id,
user0_.name,
messages1_.author_id,
messages1_.text,
messages1_.author_id,
messages1_.id
from users user0_
left outer join messages messages1_
on user0_.id=messages1_.author_idZapytanie to pobiera jeden wiersz na wiadomość użytkownika. Jeśli ograniczenie zostanie zastosowane bezpośrednio, otrzyma tylko 5 wiadomości użytkownika zamiast 5 użytkowników z ich wiadomościami. W takim przypadku rozwiązaniem jest wykonanie dwóch zapytań. Pierwsze z nich pobiera identyfikatory elementów do pobrania, a drugie szybko pobiera wszystkie dane dla tych elementów.
Spójrzmy na przykład:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@EntityGraph(attributePaths = {"messages"})
List<User> findTop5By();
// JPQL does not support LIMIT
// We need to use Pageable to set the number of ids we want
@Query("SELECT id " +
"FROM User ")
List<Long> findIds(Pageable pageable);
@EntityGraph(attributePaths = {"messages"})
List<User> findByIdIn(List<Long> userIds);
void fetch5UsersWithMessages() {
// ❌Does the limiting in memory
// Triggers HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
List<User> users = findTop5By();
// ✅Does the limiting in SQL
// Get 5 user ids with JPQL and Pageable
List<Long> userIds = findIds(PageRequest.of(0, 5));
// Get the users and messages associated to the ids
List<User> usersFromIds = findByIdIn(userIds);
}
}Więcej szczegółów tutaj.
Podsumowanie
Jesteś teraz w stanie wyeliminować wszystkie N+1 zapytań w Hibernate.
Oto podsumowanie procesu:
- Dodaj bibliotekę spring-hibernate-query-utils do swoich zależności
- Ustaw
hibernate.query.interceptor.error-levelnaEXCEPTIONwe właściwościach aplikacji dla profilu testowego. - Odpal testy aplikacji
- Oznacz każdy test zakończony niepowodzeniem i, aby przywrócić normalne zachowanie testu, dodaj
@SpringBootTest(hibernate.query.interceptor.error-level = ERROR) - Napraw każdy test oznaczony zgodnie z wytycznymi opisanymi powyżej.
Oryginał artykułu w języku angielskim przeczytasz tutaj.
