

Kamil KowalskiSoftware EngineerMotorola Solutions Systems Polska Sp.z.o.o
W pogoni za High Availability w chmurze
Dowiedz się, jak osiągnąć High Availability w chmurze na poziomie 99.999%.
Każdy dostawca usług chciałby, żeby jego serwis był zawsze dostępny. Czy to w ogóle możliwe? No cóż, to przede wszystkim zależy od tego, jak zdefiniujemy ‘dostępność’. Dlatego najważniejszą rzeczą, którą musimy ustalić na samym początku, są wymagania w tym zakresie. Inwestycje w dostępność (Availability) potrafią być bardzo kosztowne. Znalezienie złotego środka, best value for money czy punktu YAGNI nie jest łatwe i bardzo zależy od biznesu, w którym pracujemy. Czym innym jest ‘404 Not Found’ na stronie wyświetlającej memy, w aplikacji bankowej podczas przelewu czy też w systemie obsługującym połączenia alarmowe ‘112’.
Dostępność systemu opisuje się przez tzw. SLA (Service Level Agreement), określane w tzw. ‘dziewiątkach’, które oznaczają, przez jaki czas Twój system musi być dostępny w danym okresie. I tak np. 99% (dwie dziewiątki) oznacza, że w ciągu np. miesiąca system może być niedostępny tylko przez około 7,5h; 99,9 = 44 min; 99,99 = 4,5 min; 99,999 = 26 sec. Pięć dziewiątek i więcej oznacza już wysoką dostępność (High Availability - HA). Czy to jest w ogóle komukolwiek potrzebne? Jako odpowiedź wyobraźmy sobie reakcję użytkownika, gdy przez 7 godzin nie może się zalogować do swojego banku albo bank wyświetla saldo jego rachunku jako “Unknown”.
Przyjmijmy na potrzeby tego artykułu, że nasza firma nie jest już zainteresowana utrzymywaniem wielu wersji swojej aplikacji na setkach komputerów klienta czy też monolitycznej implementacji na dedykowanych serwerach. Firma zdecydowała się delegować ich hostowanie. Powody takich decyzji są tematem na osobny artykuł. Zobaczmy więc, jak zwiększać niezawodność takiego rozwiązania. Zaczniemy od najprostszych i najtańszych metod, by przejść potem do tych bardziej skomplikowanych. Omówimy po drodze wyzwania związane z każdym z nich, a na koniec zbierzemy też parę praktycznych rad, które przydadzą się niezależnie od poziomu, w który celujemy.
Tanio i szybko
Najprostszym sposobem jest uruchomienie wspomnianych serwisów na dowolnej podstawowej platformie hostingowej, gdzie administrator dostarcza nam elementarne usługi ich restartowania oraz tworzenia kopii zapasowej naszych danych. Problemów na tym etapie jest kilka. Między innymi: awaria jednego serwisu wpływa na cały system; kopie zapasowe są robione sporadycznie (możliwa utrata sporej ilości danych); aktualizacja zazwyczaj wymaga wyłączenia całego systemu; rzadko który operator gwarantuje SLA swoich maszyn na poziomie ‘99’.
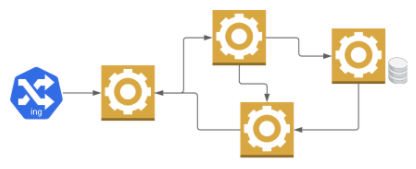
Dlatego decydujemy się zainwestować więcej i przejść na kolejny poziom zaawansowania.
Replikacja
Wybieramy operatora, który dostarcza możliwość replikacji mikroserwisów i danych. Oznacza to, że będą one miały kilka swoich kopii pracujących jednocześnie. Dostęp do nich zapewnia nam usługa równoważąca obciążenie (load balancing), czyli rozpraszająca przychodzący ruch pomiędzy wszystkie dostępne repliki.
Jednak to naszym obowiązkiem będzie zapewnienie spójności danych pomiędzy nimi (stateful services). Takie rozwiązanie może już wymagać sporych inwestycji w aplikacji, ale z punktu widzenia HA zyski są bardzo duże. W przypadku problemów pojedynczej instancji serwisu (błąd w aplikacji lub awaria maszyny serwera) mamy aktywne repliki przejmujące ruch. A błędnie pracującą instancję powinniśmy szybko zastąpić poprawną. Najbardziej oczywistym rozwiązaniem będzie wyłączenie jej z obsługi przychodzącego ruchu, a następnie restart. Służą do tego punkty kontroli (readiness and liveness probes) pozwalające zarządcy naszych replik zdecydować, czy dana instancja jest gotowa na przyjmowanie nowych requestów (readiness) i czy przypadkiem nie trzeba jej zrestartować (liveness). Celem jest zapewnienie, żeby przynajmniej jedna instancja była zawsze gotowa przetwarzać przychodzące zapytania.
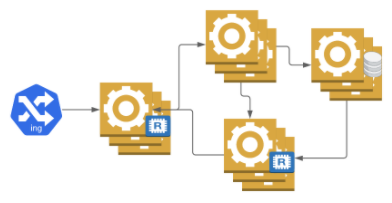
Dodatkowo, w zależności od dostawcy możemy wybrać replikację między strefami dostępności (Availability Zones), dzięki czemu nawet awaria zasilania w całej serwerowni nie wpłynie negatywnie na działanie naszego systemu.
W ten sposób jesteśmy w stanie osiągnąć SLA na poziomie 99,9 dla pojedynczego mikroserwisu. Szybko jednak zobaczymy, że przy zwiększonym ruchu potrafią one zwolnić i znacząco wydłużyć czas odpowiedzi. Osoba oglądająca memy zamknie zakładkę, klient banku będzie się irytował, gdy przy każdym kliknięciu będzie zmuszony czekać 5 sekund. Dla matki dzwoniącej po pomoc dla swojego dziecka takie dodatkowe 10 sekund to prawie jak wieczność. Niby nasze serwisy działają, ale wydłużony czas odpowiedzi powoduje, że system jest tak naprawdę niedostępny do użytku z punktu widzenia klienta. Możemy zwiększyć ilość replik w statycznej konfiguracji, aby obsłużyły ruch szczytowy (peak load), ale to dość kosztowne i nie mamy gwarancji, że prawidłowo je wyliczyliśmy.
Chwytamy za portfel i dofinansowujemy nasz projekt.
Skalowanie dynamiczne
Możemy oczywiście zwiększyć wirtualne zasoby (vCpu; mem; storage; cache; etc) naszych serwerów (tzw. skalowanie pionowe) lub też zwiększyć ilość replik samych serwisów (tzw. skalowanie poziome). To ostatnie jest bardziej popularne, gdyż pozwala niemal przezroczyście (repliki są schowane za load balancerem) manipulować możliwościami systemu w większym zakresie i bardziej precyzyjnie.
Pytania, na które musimy odpowiedzieć, to:
- na jakiej podstawie podejmiemy decyzję o skalowaniu (do wyboru m.in.: procent zajętości procesora lub pamięci; długość komunikatów w kolejce; wydłużenie czasu odpowiedzi; ilość zajętych wątków; tylko konkretne godziny)
- skąd weźmiemy te dane (monitoring systemu i infrastruktury; metryki aplikacji; logi; etc)
- kto będzie tym zarządzał (człowiek czy maszyna) i jak sprawdzi, czy osiągnął oczekiwany wynik.
Operatorzy udostępniają odpowiednie narzędzia, ale decyzja, konfiguracja i integracja należą już do nas. W ten sposób stabilizujemy nasze 99,9%, ale często obserwujemy na metrykach systemu, że występują pojedyncze okresy, gdy takich wyników nie widać. Dzieje się tak, ponieważ nasz system to połączenie wielu elementów: aplikacji z bazą danych, transportu, zarządcy klastra, kolejek i wielu innych. Pojedynczo mają one SLA na poziomie 99,9, a czasami więcej, ale w połączeniu SLA całego systemu to iloczyn części składowych. 3 elementy o dostępności 99,9% dają razem 99,7% na poziomie całego systemu (3 x 99,9).
Im więcej elementów, tym więcej okazji, żeby coś nie zadziałało. Zwyczajnie w świecie raz na jakiś czas komunikat utknie w kolejce na kilkanaście sekund, serwer dostanie mniej czasu procesora albo JVM wyczerpie pulę zdefiniowanych wątków. Takich sytuacji nie da się uniknąć, trzeba nauczyć się z nimi żyć, to znaczy umieć je wykryć i zareagować. A jeszcze lepiej przygotować się na nie. Pomocna będzie analiza FMEA (Failure mode and effect analysis), czyli dedykowane spotkanie wszystkich członków zespołu (lub ich reprezentantów) i wspólna próba znalezienia wad systemu, wymyślenia i spisania wszystkich możliwych scenariuszy (zarówno na poziomie funkcjonalnym, jak i poziomie projektu czy samej technologii), które mogą doprowadzić do jego zatrzymania lub błędu. Jest to czasochłonny proces i kosztuje dużo roboczogodzin, ale znakomicie obrazuje możliwe problemy i pozwala bardziej świadomie dobierać mechanizmy zabezpieczające.
Metodą na pojedyncze problemy/opóźnienia serwera jest powtórzenie zapytania od strony klienta (retry). Używając load balancingu mamy nadzieję, że drugie zapytanie zostanie obsłużone poprawnie na innej replice serwera. Jeśli jednak problem dotyczy wszystkich replik (np. brak dostępu do wspólnej bazy danych) i kolejne repliki również nie odpowiadają poprawnie, to nie ma sensu generować dodatkowego obciążenia. Dlatego warto próbować ponownie, ale tylko skończoną ilość razy i w skończonym czasie (timeout). W tej metodzie obsługa błędu dotyczy tylko konkretnego klienta i konkretnego zapytania, a jego konsekwencje nie wpływają na działanie innych klientów.
Jeśli problem utrzymuje się dłużej, to nie ma sensu wysyłać kolejnych nowych zapytań do wadliwej instancji serwisu, tylko dać jej czas na dokończenie bieżącej i powrót do prawidłowej pracy. Jeśli repliki mają zarządcę, to wadliwa instancja powinna zgłosić, że nie jest gotowa przyjmować nowych requestów (readiness probe).
Można też użyć mechanizmu wyłącznika/bezpiecznika (circuit breaker), który śledzi na bieżąco wszystkie odpowiedzi serwisu na konkretne zapytania i w przypadku wykrycia anomalii (np. błędne odpowiedzi, dłuższy czas oczekiwania, inne wewnętrzne parametry), natychmiast je odrzuca, informując klienta o niepowodzeniu. Dzięki temu nie wprowadza dodatkowego obciążenia do już przeładowanej instancji. Dopiero po wcześniej zdefiniowanym czasie próbuje ponownie, żeby sprawdzić, czy sytuacja wróciła do normy i odpowiedzi są prawidłowe. W połączeniu z mechanizmem powtórzeń jest to bardzo przydatne rozwiązanie.
Zbyt obciążona instancja może także poinformować swojego klienta o swojej obniżonej wydajności (throttling) i poprosić, żeby ten nie przysyłał więcej zapytań. Modyfikacją tego mechanizmu jest także obniżenie jakości odpowiedzi (np. Inny kodek audio, mniej aktualne dane z cache’a) lub priorytetyzowanie zapytań i odrzucanie tych najmniej ważnych przy użyciu np. kolejki, Throttling jest bardzo dobrym mechanizmem przejściowym w sytuacjach nagłego wzrostu ilości zapytań, gdy nie zakończył się jeszcze proces skalowania.
W tym momencie powinniśmy zacząć obserwować stabilne 99,9% na poziomie całego systemu. W zależności od użytych komponentów może to być nawet 99,95%. Gdzie więc szukać brakujących dziewiątek?
Redundancja systemu
Walka o kolejne ułamki procenta w pojedynczym regionie zaczyna być już bardzo kosztowna. Dużo prostszym sposobem jest wdrożenie kopii całego naszego systemu w drugim regionie i dynamiczne przełączanie. Jeśli nastąpi awaria całego regionu (takie sytuacje zdarzają się niestety nawet największy operatorom), wtedy możemy przekierować wszystkie zapytania do drugiego regionu. Można skorzystać tutaj z mechanizmu dynamicznego DNS, który odpytuje nasze usługi w obu regionach i na tej podstawie podejmuje decyzje.
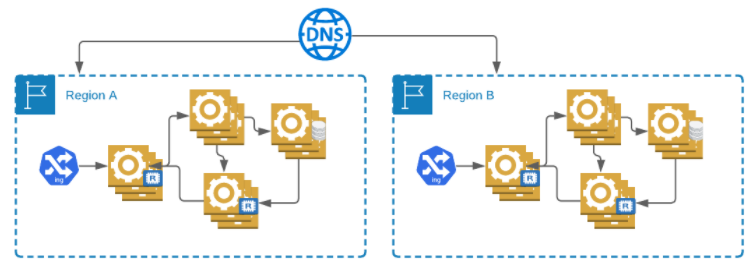
DNS jest jednak bardzo wolnym mechanizmem przełączania ze względu na cache’owanie zapytań przez różne urządzenia sieciowe. Jeśli w naszym systemie kontrolujemy aplikację użytkownika/klienta, to właśnie tam powinien znaleźć się mechanizm powtórzeń i przełączania pomiędzy regionami. Jeśli nie, to pozostaje nam liczyć na mechanizmy ukryte w przeglądarkach internetowych i skryptach ładowanych przez nasze strony.
W tym momencie mamy dwa równolegle pracujące systemy i możemy osiągnąć SLA na poziomie 99,9999 [1-(1-SLA )2]. Tak mówi teoria niezawodności systemów, ale do praktycznej realizacji jeszcze długa droga.
Istotnym elementem w konfiguracji wieloregionowej jest to, czy pozwolimy pojedynczym serwisom na komunikację i synchronizację danych pomiędzy regionami. Jeśli któryś z nich w danym regionie nie jest dostępny, to można spróbować w drugim. Jest to bardzo kusząca opcja, jednak niesie za sobą pewne niebezpieczeństwo. Potrzebujemy synchronizacji danych, a to oznacza automatyczne propagowanie błędnych danych pomiędzy regionami. Jeśli z tego powodu wyłączony zostanie któryś z naszych mikroserwisów, to istnieje duże prawdopodobieństwo, że to samo stanie się z jego geo redundantną repliką. Pomocne są tutaj grodzie (bulkhead), czyli celowe, często fizyczne dzielenie użytkowników, ich zapytań, a w szczególności danych tak, aby były od siebie niezależne. Wystarczy powstrzymać się od replikacji wszystkich dynamicznych danych pomiędzy regionami a bazę danych odpowiednio partycjonować. Czyli np. transakcja rozpoczęta w jednym regionie, musi być w nim zakończona. W przypadku błędu w jednym regionie nie ma możliwości jej kontynuacji w drugim.
Analizując możliwe awarie i ich wpływ na dostępność systemu, zaczniemy się zastanawiać nad sposobem aktualizacji poszczególnych serwisów. Zmiana aktualnej wersji na nową z nadzieją, że ten drugi nie wprowadził żadnej regresji, może być zbyt ryzykowna. Pomocne będą tutaj wdrożenia typu Blue-Green, gdzie tworzymy drugą kopię naszego systemu i przekierowujemy tylko ułamek ruchu, obserwując odpowiedzi nowej wersji. To samo na poziomie pojedynczego mikroserwisu nazywamy wdrożeniem typu canary. Tylko jedna instancja jest uruchamiana w nowej wersji, pozostałe pracują bez zmian. Dzięki temu ograniczamy możliwość wprowadzenia błędu do wszystkich instancji. Można też duplikować ruch do obu wersji i porównywać ich odpowiedzi, zanim nowa zacznie podejmować decyzję samodzielnie. Automatyzacja tego procesu bardzo mocno minimalizuje wpływ możliwej regresji na SLA całego systemu.
Redundancja operatora
Ten poziom nie dość, że drogi, to chroni tylko w przypadku totalnych katastrof. Tutaj pojawiają się pytania typu:
- A co, jeśli padną wszystkie regiony danego operatora chmury?
- A co, jeśli jakaś dana nie będzie dostępna w ciągu 0,5 sec w drugim regionie?
- A co, jeśli mamy w aplikacji błąd typu ‘zero day’?
Projektując nasz system i integrując kolejne mechanizmy HA i tak musimy iść na kompromisy w dziedzinie czasu odpowiedzi czy spójności danych. Zawsze będzie istniał taki splot zdarzeń, który w konsekwencji doprowadzi do awarii całego systemu. Tylko jakie jest jego prawdopodobieństwo i efekt na końcowego klienta? Czy będziemy niezadowoleni, jeśli saldo naszego rachunku w banku pojawi się z 2-sekundowym opóźnieniem? Pewnie nie, ale ciągle mamy przypadek matki dzwoniącej o pomoc dla dziecka. A co, jeśli nie będzie miała możliwości zadzwonić jeszcze raz?
Można oczywiście stworzyć kolejną kopię systemu u innego operatora (multi cloud) i połączyć w parę Active-Active czy też Active-Backup. Aby ustrzec się przed błędami typu ‘zero-day’, być może trzeba napisać dwie wersje naszej aplikacji w zupełnie innych technologiach. A przynajmniej jej najbardziej krytyczną część (multi application).
Co dalej?
Inwestować w HA można w nieskończoność. Możemy walczyć o ułamki sekund, wykręcać ręce istniejącym na rynku technologiom, modyfikować je czy też pisać wszystko od zera. Może warto zmienić spojrzenie na ten sam problem, spróbować innej koncepcji. Zawsze lepiej szukać możliwości wykorzystania istniejących na rynku rozwiązań niż pisać samodzielnie nowe, ale czasami nie mam wyjścia.
W firmie Motorola pracujemy nad aplikacjami wykorzystywanymi w służbie bezpieczeństwa publicznego, gdzie wymagane jest min. pięć dziewiątek. W dodatku czas oczekiwanej odpowiedzi jest ekstremalnie krótki. Niestety większość dostępnych rozwiązań gwarantuje czas reakcji na błędy na poziomie kilku sekund. To właśnie z tego powodu rozwiązania HA w Motoroli docierają często do granic aktualnych technologii lub tworzone są nowe dedykowane pod specjalne potrzeby.
Podsumowanie
Kolejność wprowadzania poszczególnych mechanizmów jest oczywiście kwestią dyskusyjną i należy ją dostosować do konkretnych potrzeb. Każde z przytoczonych tutaj rozwiązań jest dużo bardziej skomplikowane i może być tematem na osobne artykuły. W 99% przypadków wystarczą ustawienia domyślne, ale jeśli jesteśmy tym pozostałym 1%, to zdecydowanie potrzebne jest lepsze zrozumienie ich mechaniki i konfiguracji.
Pamiętajmy też o potrzebie testowania systemu w sytuacjach wyjątkowych. Znakomicie nadają się tutaj aplikacje stosujące tzw. testy chaotyczne (chaos testing), gdzie możemy symulować np. nagłe zabicie jednej z replik konkretnego serwisu, brak odpowiedzi od serwera, opóźnioną odpowiedź, zagubiony pakiet w sieci, błędną konfigurację sieciową i wiele innych.
Bez względu na to, jakich technologii zdecydujemy się użyć, jest kilka ponadczasowych reguł, którymi warto się kierować (Rules of thumb):
- Zaakceptuj błędy, nie walcz z nimi. Naucz się szybko je wykrywać i reagować.
- Keep it simple stupid! (KISS) Nie komplikuj niepotrzebnie systemu. Dobieraj poziomy HA w zależności od wymagań, po uzgodnieniu z menedżerem produktu.
- Planuj aktywności związane z HA już na etapie projektu.
- Zrównoleglaj proste rozwiązania, zamiast komplikować pojedyncze
- Symuluj/testuj możliwe katastrofy swojego systemu.
- Zainwestuj w dobry monitoring (logi, metryki, przebiegi, transakcje)
A przecież wiele ze wspomnianych problemów nie występuje w ogóle w aplikacjach monolitycznych. A może by tak… ? Hmm. Tam też już byliśmy.
Źródła:
https://www.intechopen.com/books/concise-reliability-for-engineers/reliability-of-systems
https://docs.microsoft.com/pl-pl/azure/architecture/patterns/
https://aws.amazon.com/blogs/startups/high-availability-for-mere-mortals/
https://cloud.google.com/solutions/scalable-and-resilient-apps